伴隨著市面上新一代裝置追求高解析度、高品質及同時多個檔案錄影的需求,SD協會(Secure Digital Association, SDA)在2016年定義新的連續存取速度標準Video Speed Class,來確保穩定最低寫入性能,讓消費者可以根據自己應用需求,來選擇適合的產品。
SD Card在2016年是一個規格改變的開始,從快閃記憶體(NAND Flash)轉換二維(2D)三層式儲存單元(Triple-Level Cell, TLC)製程至三維(3D) TLC,導致控制器的功能要求須順勢提升;到市場應用越來越重視隨機存取速度而非僅重視連續讀寫速度,故協會公布SD 5.1規格以界定隨機存取速度需求。
快閃記憶體控制晶片廠商為因應消費者、SD協會、快閃記憶體製造商的變革,以3D TLC NAND Flash的特性,搭配控制器除錯特性與韌體架構,並兼容最新SD 5.1與市場主流SD 3.0規格。
本文將介紹如何運用優化的動態調整演算法,來達到記憶卡資料穩定寫入性能,避免因為寫入速度低於主機需求,而有資料遺失、錄影掉格(Frame Drop)或是錄影中止(Time-out)的情況發生。
關於穿戴式裝置這類應用,SD協會推出新的連續存取速度標準Video Speed Class,表1清楚顯示了Video Speed Class與先前速度規格Speed Class和UHS Speed Class的相對關係。
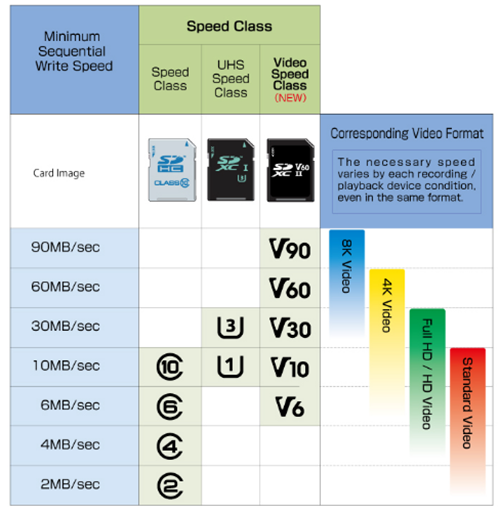 |
| 表1 Video Speed Class標準之速度規格比較 |
資料來源:https://www.sdcard.org/
前一代裝置的應用,比起新一代裝置相對單純,單筆寫入資料的量比較小,且大部分應用只有同時單一檔案錄影,使用舊有演算法架構,即足以提供主機需求的最低寫入速度。
新一代裝置如空拍機(Drone)、運動相機(Action Camera)、360度相機(360 Degree Camera)、虛擬實境相機(VR Camera),除了單筆寫入資料量變大外,也多會同時對卡片寫入或更新多個檔案,例如全球衛星定位系統(GPS)位置、高度、目前時間等等。須在各種主機行為全部兼顧的考量下優化演算法。接下來,透過兩大特點來更進一步認識動態調整演算法。
資料暫存區的分散式處理
為了使3D快閃記憶模組的速度最大化,因而開發了一套新的抹除單元管理方式。既存的TLC抹除單元管理方式,即是當從主機端收取到資料後,馬上對三個稱之為Buffer Block的暫存抹除單元進行寫入的動作,並且在適當的時機把分散在此三個暫存抹除單元的資料合併,並且寫入一個永久抹除單元裡面,稱之為Static Block。
以上這種管理方式適用於目前一般的TLC快閃記憶模組,並且也能夠達到協會和市面上主機要求的速度和穩定性。但是,如果換成3D快閃記憶模組的話,會出現速度沒有辦法突破的現象,主要原因就在於3D快閃記憶模組的抹除單元容量增加,而且裝置要處理的總容量也增加,原本的管理方式沒有辦法百分之百隨時保持Buffer Block的暢通,因此首先必須解決的就是在主機隨時及密集地傳入資料時,任何時間都要有足夠的Buffer Block,或者能夠快速地處理已經寫滿的Buffer Block來儲存那些資料,這樣才可以避免寫入時間的拉長。
為增加卡片寫入性能,舊有架構會把從主機端接收的資料先存入暫存區,並在適當的時機將分散在暫存區的資料整理並合併到資料儲存區。這種處理方式在面對容量越大或越零散的資料,會出現來不及把舊資料從暫存區整理到資料儲存區,進而造成新資料寫入暫存區塞車、寫入時間拉長的現象(圖1)。
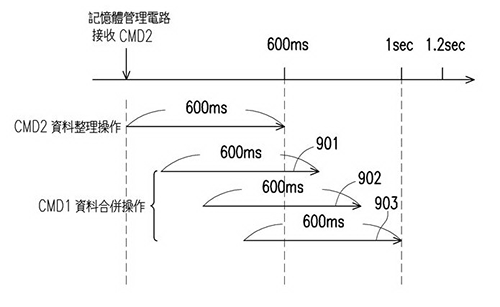 |
| 圖1 舊有架構的處理方式 |
如圖1所示,在資料寫入空餘的時間,針對當下被使用到或即將被使用到的暫存區,做資料合併及整理。這種處理方式,容易出現排隊塞車的現象,即每一次的合併都必須等待上一筆的合併結束之後才能開始運作(例如901、902、903),整個CMD2+CMD1作業的時間就會拉長至1秒(sec),直接影響到使用者的感受和裝置的穩定性。
新架構則透過增加第二暫存區的方式,讓兩個暫存緩衝區各自分散獨立作業,原暫存區負責接收來自主機端的即時資料,並將資料存入第二暫存區,第二暫存區負責將資料整理並合併到資料儲存區。透過此分散式多工處理,可以同時獨立作業,縮短處理時間(圖2),進而避免新資料寫入暫存區塞車、主機端寫入時間拉長或暫存於主機端快取記憶體的資料,在還未寫入至快閃記憶體模組前就被抹除的情況。
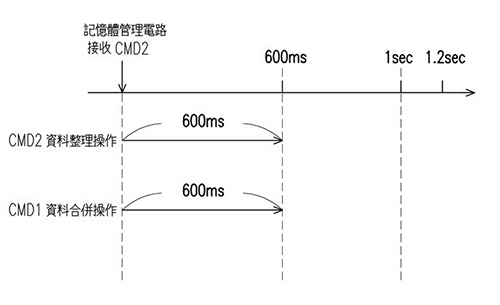 |
| 圖2 新架構增加第二暫存區後的處理方式 |
如圖2所示,與舊架構不同,暫存區的作業毋須互相等待,可以各自獨立作業,進而避免圖1內901、902、903須互相等待的情況發生,CMD 1的資料合併操作與對應CMD 2的資料整理操作同時被執行,如此一來,整個CMD2+CMD1資料整理合併作業的時間就會縮短至600毫秒(ms)。
高效率資料合併管理
一旦遇到記憶卡內部在做資料整理合併作業時,速度性能還是會受到影響。所以這裡介紹的動態調整技術,不但要透過增加第二暫存區來縮短資料整理並合併的作業時間,還搭配新的計算方式,有效地降低新資料寫入就必須要有資料整理並合併的次數,但增加資料傳輸的效率就牽涉到記憶卡的性能。
動態調整演算法會監控和記錄每一個暫存區的使用狀況與主機端所傳送的資料型態,主動地把寫入位址連續的大資料檔案和寫入位址隨機的小資料檔案分開處理。
如果寫入的都是連續性的大檔案,系統會用一個專屬的暫存區來處理所有相關的寫入資料,如此一來,資料合併的時間點就會被限制在一個暫存區寫滿的時候,而不會因為一開始使用兩個不同的暫存區來處理該寫入資料,而在資料整理合併階段,須要多處理一個暫存區,進而減少無謂的合併。
針對隨機性的小資料檔案處理,因為寫入的位置會因為主機端而有所不同,所以本來所須整理及合併暫存區的頻繁度會比較高,透過計數值統計,將隨機性小資料檔案頻繁使用的寫入的位置,放到同一個對應暫存區。等寫滿比較多資料時,再將此暫存區的資料整理合併到資料儲存區,減少合併頻率及次數。透過高效率資料合併管理,讓每一次的合併都會發生在最有必要和最有價值的時間點。
主要創新的即時監控系統分成兩個階段來運作,第一個階段會主動地監控及記錄每一個Buffer Block的使用狀況與主機所傳送的資料,系統會主動地把連續性的大檔案和隨機性的小檔案分開處理。原因是如果寫入的都是連續性的大檔案,系統就會用一個專屬的Buffer Block來處理所有相關的寫入,這樣合併的時間點就只會被限制在一個Buffer Block寫滿的時候才會合併,而不會因為寫在兩個不同的Buffer Block,而須要提早做合併刪除的動作,這個階段能減少無謂的合併。
記憶卡規格/主機端廠商配合求雙贏
在消費性電子及主機端規格的快速發展的市場上,記憶卡規格與主機端廠商持續在尋找雙方的平衡點。開發廠商未來會持續致力於快閃記憶體控制器晶片完整技術的開發、優化演算法、產品規格相容市場主流,提供針對不同主機端的應用及符合市場需求的完整解決方案。
(本文作者為群聯電子技術長)