無線耳塞式耳機和頭戴式耳機等免持裝置逐漸普及,使用者對於高品質音訊的需求也日益增加,聲音處理方法已成為日常生活中的重要面向。語音辨識技術的進步,則讓我們對於聲音處理技術的要求更高。
(承前文)本篇文章的第一部分討論了設計環境降噪(ENC)系統時,必須牢記的重要概念。第二部分將談談等式的另一邊,也就是噪音本身。本文將描述常見的噪音類型,並探討一些一般用來解決此問題的傳統語言增強方法。
靜態/非靜態噪音比較
研究人員通常會將噪音歸類為靜態或非靜態,視不同的特徵而定。瞭解兩種噪音類型之間的差異,能夠幫助我們更加瞭解兩者不同的特性與處理方式。
靜態噪音指的是,一段時間內,統計特性相對不變的噪音。換句話說,均值、變異數與自我相關等統計特性將保持不變,或僅會隨時間略有變化。靜態噪音的常見例子包括空調或冰箱的持續嗡鳴聲。靜態噪音通常可以用數學技術輕易地描述和分析,因此適合採用各種分析演算法來進行預測和消除。
靜態噪音的著名範例之一是「白噪音」,為一種隨機噪音,包含頻譜中所有頻率的相等強度。之所以被稱為「白」噪音,是因為它與白光類似,白光包含了所有可見光的波長。白噪音通常用來作為背景聲音,以遮蓋其他聲音,促進放鬆或改善睡眠。此外,白噪音也用於音訊工程,以對設備進行測試和校準。靜態噪音的另一個例子是冰箱的嗡鳴聲。儘管在各頻率強度不同,我們仍可預測其未來的顯示方式。
圖3為上述兩種靜態噪音的聲譜範例圖。聲譜圖(Spectrogram)是隨著時間變化呈現訊號頻率頻譜的視覺表示方式。水平軸代表時間,垂直軸代表頻率,強度以色彩表示,色彩越亮代表訊號強度越高。
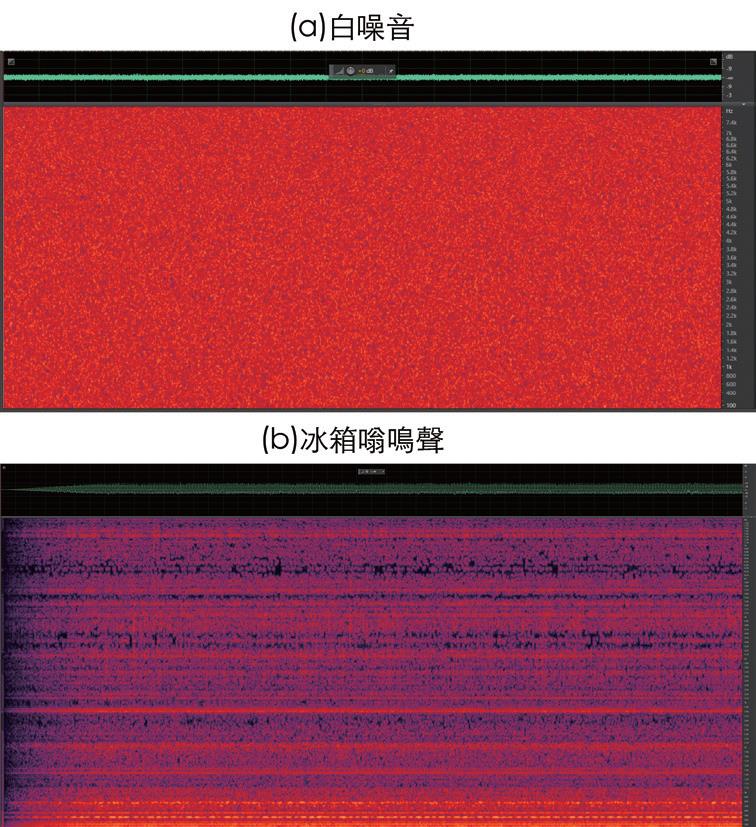 圖3 靜態噪音的聲譜範例圖
圖3 靜態噪音的聲譜範例圖
另一方面,非靜態噪音指的是一段時間內,其統計特性會出現顯著變化的噪音。這表示非靜態噪音的統計特性可能會有明顯變化,甚至會突然變更,使分析變得更複雜且困難。非靜態噪音可能來自各種來源,例如交通噪音、群眾噪音或其他環境因素。與靜態噪音不同,非靜態噪音帶來了獨特的挑戰,因其動態且具有時間變化的特性,需要先進的技術來進行捕捉。
交通噪音是非靜態噪音的範例(圖4),其統計特性將隨著時間大幅改變。交通噪音是複雜且動態的環境噪音類型,噪音源自各種來源,包括自發性喇叭、不同的引擎聲音,以及以不同速度通過的各種車輛。此外,路面類型、周遭地形和天候狀況都可能影響一整天的強度和頻率內容變化。因此,交通噪音的分析和緩解作業可能相當困難,因為沒有重複的特徵可描述這類噪音,難以預測和學習。
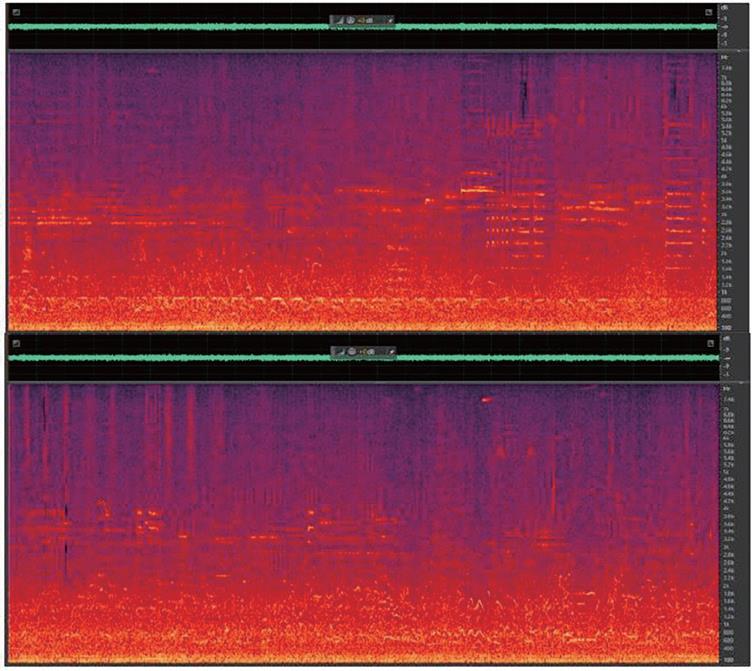 圖4 兩個不同交通噪音的聲譜範例圖
圖4 兩個不同交通噪音的聲譜範例圖
噪音也可依其持續時間來描述。溫和、持續的噪音,如風聲,可能具有較長的持續時間,而突發性噪音(有時稱為暫態噪音),如雷聲、槍聲、爆炸、刮痕聲和其他突然的聲音,持續時間則較短。這些突發性噪音可能會特別難處理,因為它們可能會在無預警的情況下發生,且持續時間不足以讓適應語音增強系統對噪音進行學習和消除。
噪音也可以透過頻譜的能量分布來區別。例如,在風切噪音中,大部分能量會集中在較低的頻率(小於500Hz),而鳥叫聲大部分的能量介於約3~7kHz之間(圖5)。這種能量分布的差異可能會對不同聲音的感知和分析造成顯著影響。瞭解不同聲音的能量分布有助於研發有效的降噪和過濾技術,以提升音訊訊號的品質。
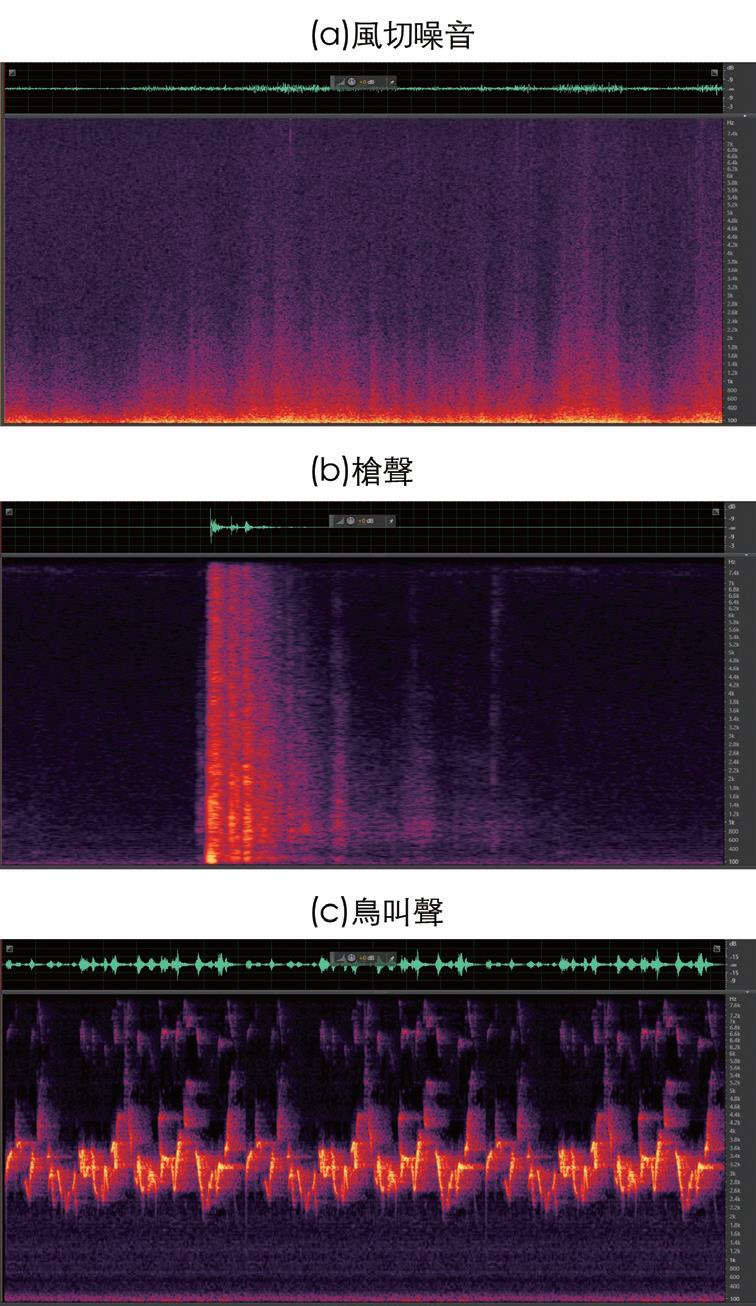 圖5 幾種噪音的聲譜範例圖
圖5 幾種噪音的聲譜範例圖
在增強語音方面,其中一個特別具有挑戰性的情境稱為「雞尾酒派對」問題。這個問題是形容在吵雜的環境中,將目標語音訊號與多個語音訊號或其他干擾聲音進行分離及增強相當困難,就像試著在擁擠的派對上專注進行單一對話一般(圖6)。
 圖6 「雞尾酒派對」問題示意圖
圖6 「雞尾酒派對」問題示意圖
在現實情境中,例如在雞尾酒派對、會議或擁擠的公共場所,可能會有多個人同時說話,而這些人將有各種說話特徵和未知來源。如此創造出一種聲音混合的效果,其中包括他們的聲音以及同時受到房間聲學特性影響的背景噪音,將導致目標語音訊號被干擾聲音影響而難以區別,使所需的語音訊號難以被理解或擷取。
傳統的訊號處理方法
傳統訊號處理理論中已建議採用許多演算法,以處理環境降噪問題。此類演算法通常可分為四個主要類別[1]:
一、聲譜削減演算法(Spectral Subtractive Algorithms):這種演算法會在語音未出現時估計/更新噪音聲譜,並將其從吵雜訊號(Noisy Signal)中削減。聲譜削減演算法是以噪音疊加的原理為基礎,且為執行方式最簡單的增強演算法。
二、統計模型演算法(Statistical-model-based Algorithms):這種演算法會在統計預估架構中提出語音增強問題。舉例來說,若有一組測量值,對應到吵雜訊號的傅立葉轉換係數,它們的目標是找到一個線性(或非線性)的預估工具來計算清楚訊號(Clean Signal)的轉換係數。維納演算法(Wiener Algorithm)以及最小均方誤差(MMSE)演算法,都是統計模型演算法的例子。
三、子空間演算法(Subspace Algorithms):這種演算法主要根據線性代數理論,且其基本原則為清楚訊號可能會被局限於吵雜歐幾里得空間的一個子空間中。子空間演算法會將吵雜訊號的向量空間分解為主要受清楚訊號占用的子空間,以及主要由噪音訊號(Noise Signal)占用的子空間。透過將存在於「噪音子空間」吵雜向量成分歸零,進而估計清楚訊號。
四、二元遮罩演算法(Binary Mask Algorithms):二元遮罩演算法與前面三種演算法不同,它使用二元增益函數。這相當於從損壞的語音頻譜中選擇一個頻率格(或通道)的子集,同時丟棄其餘部分。這些頻率格的選擇根據指定的規則或標準進行。二元遮罩演算法經證實可以在某些情況下改善語音清晰度。
傳統的語音增強演算法已存在數十年,經證實可有效降低語音訊號中的靜態背景噪音(圖7)。然而,在非靜態的噪音環境中,其效能通常會降低,並且運算複雜度可能會造成輸出語音訊號的顯著延遲或失真(圖8)。此外,這些演算法可能需要微調參數,才能在特定應用中達到令人滿意的結果,且可能無法在其他情境下順利運作。因此,雖然這些傳統演算法在某些情境中仍然有用,但較新且較進階的技術,例如深度學習型方法,將能突破諸多限制,並在更廣泛的噪音條件下達到優異的效能。
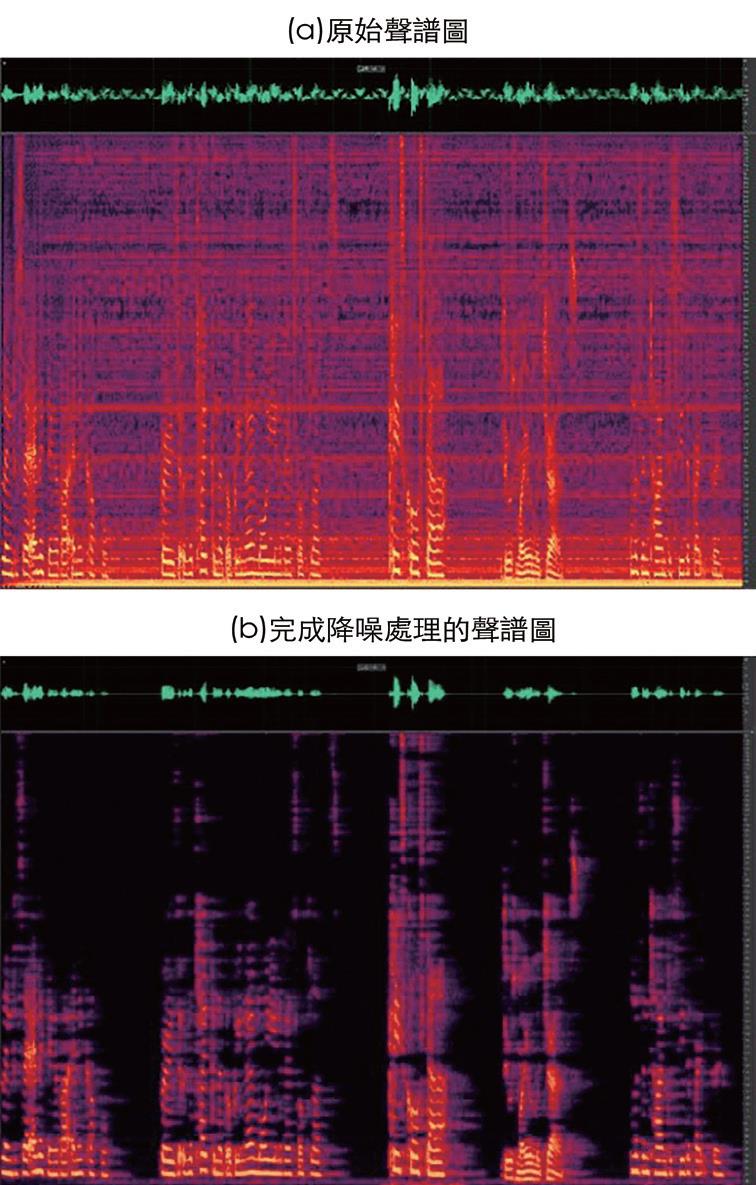 圖7 使用傳統演算法處理具有冰箱噪音(靜態)的語音
圖7 使用傳統演算法處理具有冰箱噪音(靜態)的語音
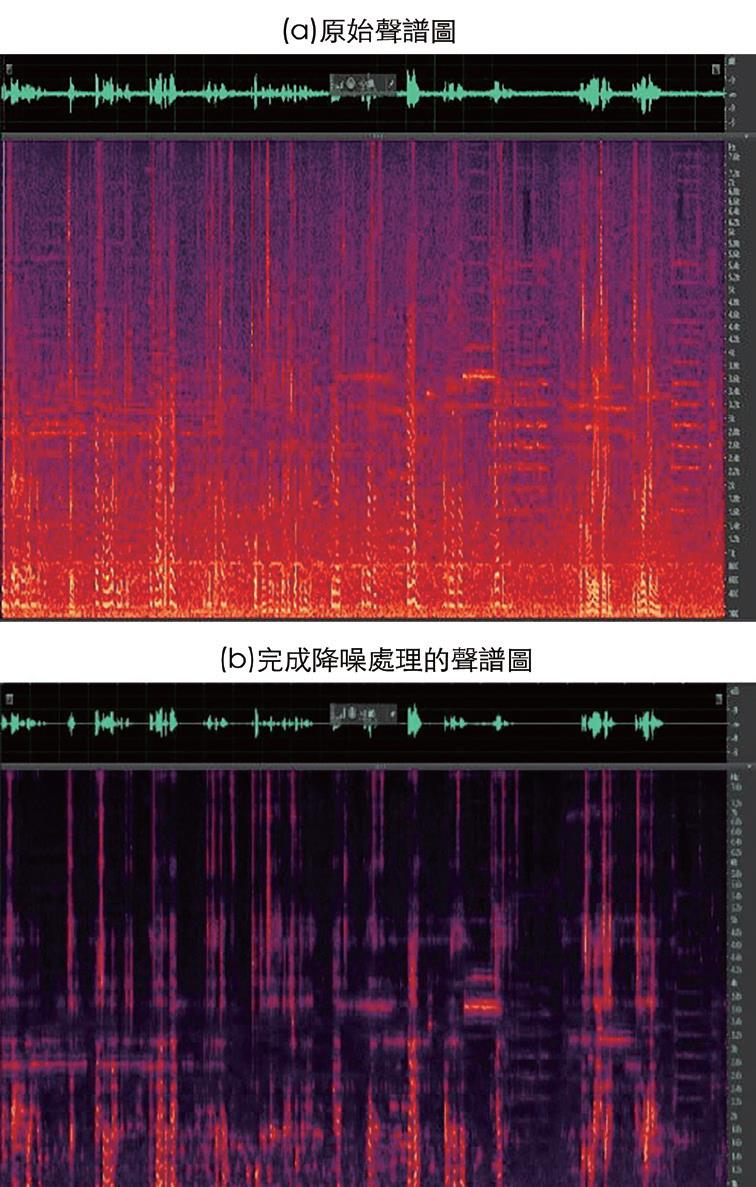 圖8 使用傳統演算法處理具有交通噪音(非靜態)的語音
圖8 使用傳統演算法處理具有交通噪音(非靜態)的語音
第三部分將深入探討在ENC中使用深度學習的尖端技術,探索該方法如何達成非凡的成果,以及其越來越受歡迎的原因。此外,也將以CEVA-ClearVox ENC為例,說明相關解決方案如何有效對應不同噪音類型,並針對如何為環境和系統選擇最佳的語音增強方法提供見解。
(本文作者任職於CEVA)
參考資料
[1] P. C. Loizou, Speech Enhancement (語音增強): Theory and Practice, Boca Raton, FL, USA:CRC Press, 2013.
AI音訊技術系列(1) ENC環境降噪強化音訊品質
AI音訊技術系列(2) 靜態/非靜態降噪處理有方
AI音訊技術系列(3) 深度學習降噪處理開啟音訊新紀元