無線耳塞式耳機和頭戴式耳機等免持裝置逐漸普及,使用者對於高品質音訊的需求也日益增加,聲音處理方法已成為日常生活中的重要面向。語音辨識技術的進步,則讓我們對於聲音處理技術的要求更高。
(承前文)此系列文章中,前兩部分已經介紹過基礎概念,並探討應考量的關鍵因素,同時了解如何分辨靜態和非靜態噪音,深入探討傳統的語音增強方法。現在,第三部分中將深入AI音訊的領域,探索如何使用深度學習方法來進行環境降噪(ENC)。我們正處於聲學技術發展的新紀元,本文將說明先進技術如何為對抗擾人噪音的戰鬥帶來革命性影響,塑造聽覺的未來。
深度學習助攻降噪 資料擴增加強訓練成效
深度學習方法已成為先進的環境降噪解決方案。深度學習與傳統的作法不同,傳統方法仰賴精心設計的演算法,以將噪音與所需的音訊區隔開來,而深度學習則利用神經網路的力量,在大量資料中自動學習複雜的模式和關係。這種適應資料並從中學習的能力,可以擺脫傳統方法往往難以掌握真實世界噪音情況的問題。深度學習模型精通歸納(Generalization),能夠處理更廣泛的噪音類型和變化。此為傳統方法在使用單聲道時,因其固定基於規則的本質而難以實現的處理能力(圖1)。
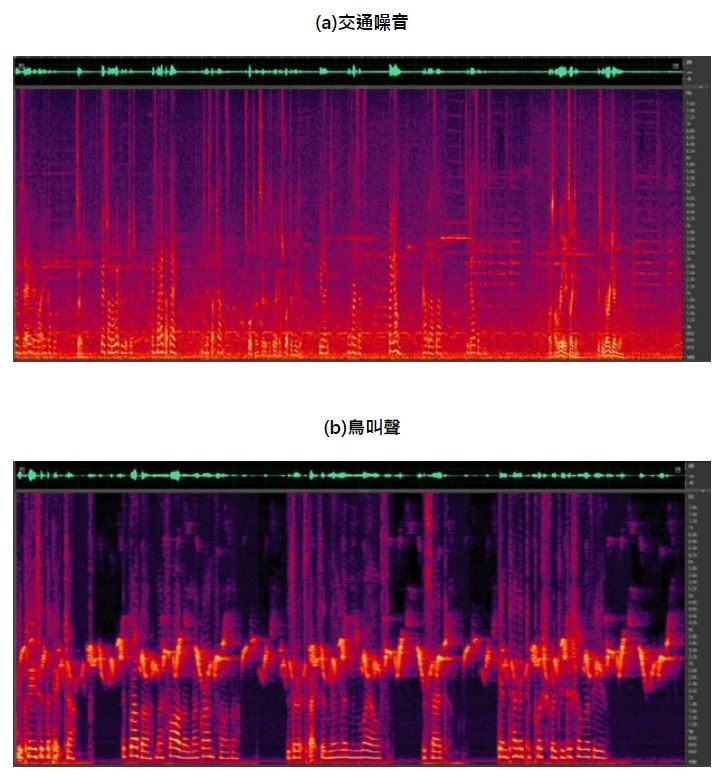 圖1 使用CEVA深度學習解決方案降低噪音
圖1 使用CEVA深度學習解決方案降低噪音
深度神經網路具備分析和處理複雜時間及頻譜特徵的能力,使其本質上適合擷取不斷變化的環境噪音特性。這種適應能力可轉化為降噪解決方案,不僅效果更好,還能帶來更多功能,能夠應付多樣且不斷演變的噪音環境,而不需要經常手動調整。
深度學習的本質在於其優異的能力,能夠從大量的資料中擷取模式和見解。在訓練語音增強模型時,將使模型暴露於成對的吵雜和清楚音訊樣本中,以應用此基本概念。這些成對的組別將扮演此模型的教師,引導模型了解噪音的複雜性。這個過程的真正力量來自資料的數量、多樣性,以及對現實世界情境的呈現。
選擇多元且全面的資料集非常重要,需要確保模型能夠經歷各式各樣的噪音變化、背景環境和訊號類型。透過結合各種靜態和非靜態的噪音來源,此模型可學習在各種情況下識別並降低噪音。此即為資料擴增(Data Augmentation)概念能夠發揮作用的地方,能夠將受控制的失真和變化加入資料集中。此類擴增模擬了真實世界情境的不可預測性,使模型對不同的噪音來源具有韌性,並增強其進行歸納的能力(圖2)。
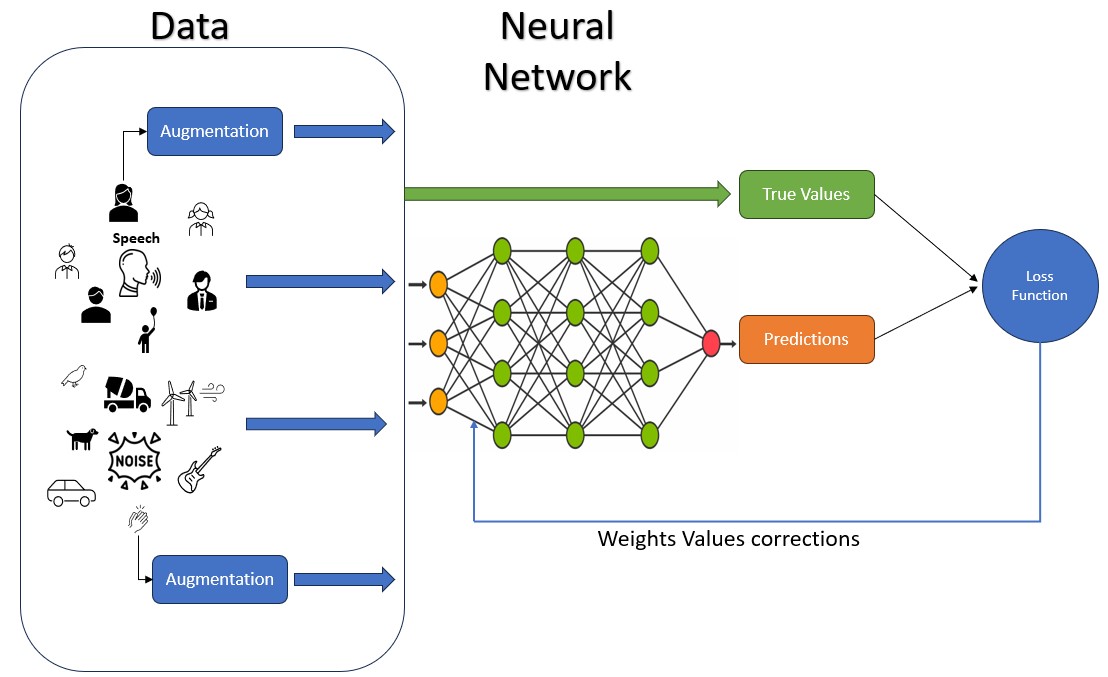 圖2 模型訓練流程
圖2 模型訓練流程
此外,學習區分重要的音訊組成要素和不需要的噪音,是模型轉型過程的關鍵一環,就像人類聽覺系統的運作方式一樣。隨著模型在迭代訓練中不斷進步,其內部參數將隨著最佳化的過程而調整,進一步了解資料中的複雜關係。此類模型模擬了人類大腦透過學習來適應和改善感知的方式。
若將訓練過的模型應用在即時音訊串流,便能見證這項流程的成效。透過所獲得的知識及所學習的模式,模型能夠準確預測和消除噪音,在吵雜環境中提供更安靜的體驗。模型的成功不只取決於其識別噪音的技能,也包括了解噪音在不同情況下的呈現方式。因此,訓練降噪模型的過程並不僅止於演算法與參數,也延伸至探索資料多樣性、增強策略,以及數位學習與人類感知的和諧互動。
遮罩型VS對應型
遮罩型(Masking-based)和對應型(Mapping-based)是使用深度學習進行環境降噪的兩種方法,分別透過不同機制達成降低噪音影響以改善所需音訊訊號品質的目標。
遮罩型方法根據頻譜遮罩的原理運作,將估計時頻遮罩,指出每個時頻格(Time-frequency Bin)的目標訊號和噪音是否存在。這些遮罩接下來會套用至噪音聲譜(Spectrogram),降低噪音成分並增強所需訊號。遮罩可視為一種「軟性」介入的方法,模型會修改聲譜中的幅度,同時大致上保持相位不變,以此引導增強過程(圖3)。
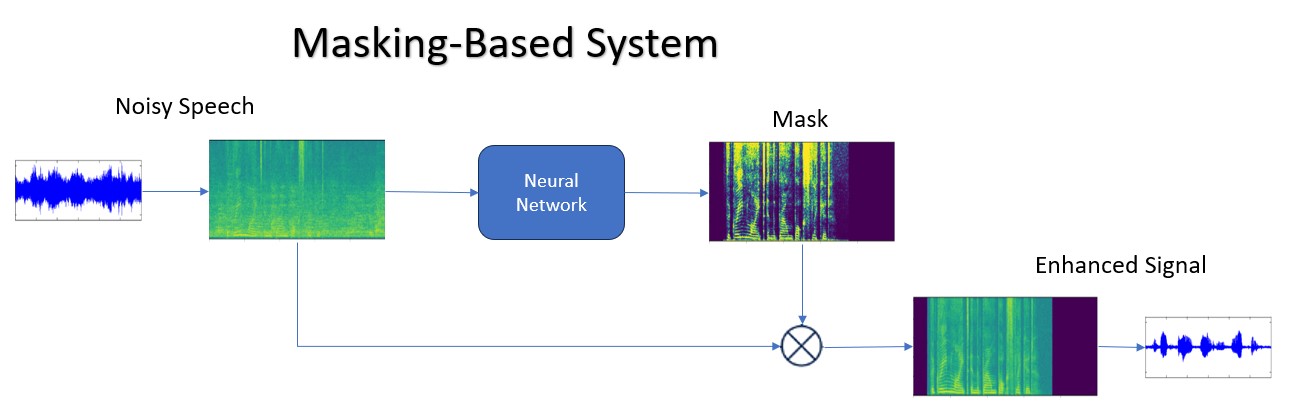 圖3 遮罩型系統流程圖
圖3 遮罩型系統流程圖
遮罩型方法的優點包括可有效減少噪音,且不會對目標訊號造成顯著失真。然而,若遇到目標和噪音來源在頻域中大量重疊的情況,遮罩型方法可能會遇到困難,導致降噪不完整。
對應型方法的作法則有所不同,其直接將噪音輸入聲譜對應至更清楚的版本。這種方法不會估計遮罩,而是學習一個複雜的對應功能,將輸入聲譜轉換為符合對應的清楚聲譜。此方法更像是「硬性」篩選,模型會明確決定哪些聲譜部分需要增強,哪些需要抑制(圖4)。
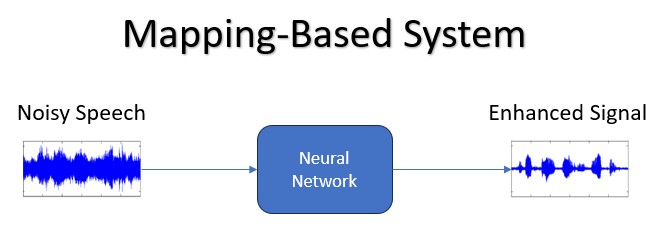 圖4 對應型系統流程圖
圖4 對應型系統流程圖
對應型方法具有在噪音和清楚聲譜之間處理複雜轉換的優點,可以處理相位重建和處理不同頻率成分之間的複雜時間關係等問題。然而,由於對應型方法對聲譜實施了更直接的轉換,如果不謹慎訓練,也可能因此引進一些異常。CEVA ClearVox AI型的ENC解決方案為一種遮罩型方法,其設計可加強訊號的清晰度,同時保留人類語音的自然特質,因此可避免失真和不必要的干擾。
克服深度學習降噪挑戰 創新技術升級音訊體驗
一般而言,深度學習在AI音訊處理的應用範圍非常廣泛,特別是ENC。從提升語音通話和虛擬會議的音訊品質,到透過減少設備嗡鳴聲以提供更安靜的生活空間,深度學習在音訊處理的潛在優點無庸置疑。不過,這項前景看好的技術也面臨許多挑戰。研究人員和工程師正努力克服的難題包括建構涵蓋多種噪音情境的健全資料集,並在降噪和訊號失真之間取得平衡。
相關解決方案能夠應對這些挑戰。例如,CEVA解決方案透過運用優化架構、讓其接觸龐大且多樣化的資料集、執行多種資料擴增、謹慎選擇並準備資料,以及設定正確的訓練目標,成功克服了這些挑戰。ClearVox AI型解決方案提供有效的解決方案,可增強音訊品質並減少不必要的噪音。
聲音處理技術的進化,尤其是在ENC領域中,持續克服變化多端的聲音環境所帶來挑戰。從傳統的過濾與調適演算法方法,到深度學習驅動的先進AI音訊,我們已經歷一場聲音革命。CEVA致力將ENC無縫整合至其音訊處理解決方案,克服上述挑戰,重新定義體驗聲音世界的方式。對於卓越音質和有效溝通的追求永無止境,每一項創新都將使我們更接近一個噪音不再是阻礙、人際連結的各式音訊在任何環境中都能蓬勃發展的世界。
(本文作者任職於CEVA)
AI音訊技術系列(1) ENC環境降噪強化音訊品質
AI音訊技術系列(2) 靜態/非靜態降噪處理有方
AI音訊技術系列(3) 深度學習降噪處理開啟音訊新紀元