人工智慧(AI)、機器學習(ML)及深度學習(DL)等高效能運算應用蓬勃發展,儲存裝置和GPU記憶體之間的資料路徑將決定應用程式是否能實現最佳效能。NVIDIA Magnum IO GPUDirect Storage解決方案能夠在儲存裝置和GPU記憶體之間建立直接路徑,在PCIe 4.0規範下,將資料速率提高至26GBps。
隨著更快的圖形處理單元(GPU)能夠提供明顯更高的運算能力,儲存裝置和GPU記憶體之間的資料路徑瓶頸阻礙應用程式實現最佳效能。NVIDIA的Magnum IO GPUDirect Storage解決方案透過在儲存裝置和GPU記憶體之間建立直接路徑,協助解決該問題。此外,採用容錯系統來優化該產品已經十分出色的能力,以確保在發生災難性故障時備份關鍵資料,同樣十分重要。該解決方案透過PCIe結構連接邏輯RAID磁碟陣列(Logical RAID Volume),在PCIe 4.0規範下,可以將資料速率提高至26GBps。為了解如何實現這些優勢,首先需要檢查該解決方案的關鍵元件及其如何協同工作來提供結果。
Magnum IO GPUDirect Storage
由於Magnum IO GPUDirect Storage解決方案不使用CPU中的系統記憶體來將資料從儲存裝置載入到GPU進行處理,該解決方案能夠排除其中一個主要效能瓶頸。通常情況下,資料會先移動到主機記憶體再傳送到GPU,這有賴於CPU系統記憶體中的回彈緩衝區(Bounce Buffer),在資料傳送到GPU之前,會在其中創建多個資料副本。然而,透過這種路徑移動大量資料會產生延遲,降低GPU效能,並在主機中占用許多CPU週期。Magnum IO GPUDirect Storage解決方案無須存取CPU,避免了回彈緩衝區所導致的效率低下(圖1)。
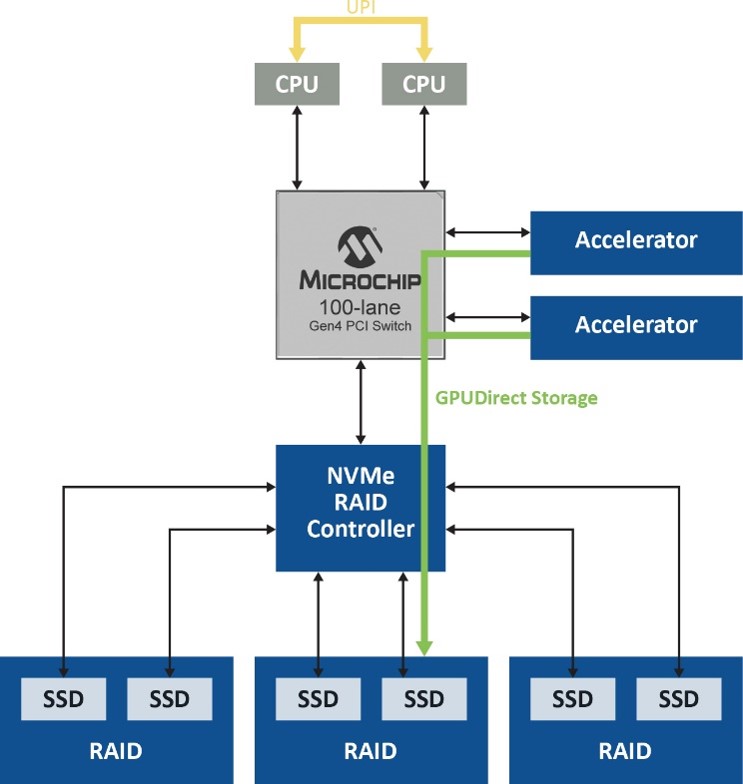 圖1 Magnum IO GPUDirect Storage解決方案無須存取CPU,避免了資料路徑的回彈緩衝
圖1 Magnum IO GPUDirect Storage解決方案無須存取CPU,避免了資料路徑的回彈緩衝
效能直接隨著傳送資料量的增加而提高,傳送資料量則隨著人工智慧(AI)、機器學習(ML)、深度學習(DL)和其他資料密集型應用所需的大型分散式資料集呈指數級成長。當資料在地儲存或是遠端儲存時,可以實現這些優勢,進而允許以較CPU記憶體中頁面快取更快的速度存取petabytes的遠端儲存資料。
優化RAID效能
該解決方案中的下一個元素,是加入RAID功能,以便保持資料備援和容錯能力。雖然軟體RAID可以提供資料備援,但底層軟體RAID引擎仍然使用精簡指令集電腦(RISC)架構進行操作,例如同位運算(Parity Calculations)。比較高級RAID級別(例如RAID 5和RAID 6)的寫入I/O延遲時,因為提供了專用處理器來執行這些操作和回寫快取記憶體,硬體RAID的速度仍比軟體RAID要快得多。在串流應用中,軟體RIAD漫長的RIAD回應時間將導致資料堆積於快取記憶體中。硬體RAID解決方案不存在快取資料堆積問題,並且具有專門的備用電池,可以避免出現災難性系統電源失效時出現資料丟失的情況。
標準硬體RAID雖然減輕了主機的同位管理負擔,但大量資料仍需要經過RAID控制器才能發送至NVMe驅動器,導致資料路徑變得更加複雜。針對此問題的解決方案是優化NVMe的硬體RAID,該解決方案提供了簡化的資料路徑,無須經過韌體或RAID內建控制器即可傳送資料,同時允許維護基於硬體的保護和加密服務。
儲存裝置/GPU資料路徑傳輸再加速(1)
儲存裝置/GPU資料路徑傳輸再加速(2)