2023年,生成式AI的應用如雨後春筍般冒出,而在邊緣端運行大型語言模型(LLM)具有隱私安全及快速回應等優勢,行動裝置因此陸續開始探索邊緣LLM的可能性。本文以Arm實際示範成果為例,說明可協助行動裝置實現邊緣LLM應用的關鍵技術。
2023年,由生成式AI驅動的應用場景數量十分壯觀。OpenAI的ChatGPT以及Google的Gemini AI模型的核心,正是展現這種顛覆型的人工智慧(AI)技術,透過使用者的文字提示,產出文本、影像甚至是音訊內容,展現出簡化工作與增進教育發展的契機。
不過,隨著生成式AI在我們倚賴的消費性電子裝置間擴散,生成式AI的下一步是什麼?答案是在邊緣的行動裝置上運行生成式AI。
本文將說明大型語言模型(LLM,一種生成式AI的推論類型),如何能在基於Arm技術打造的多數行動裝置上運行。文中將討論Arm CPU如何因應此類應用場景的典型批量大小(Batch Size),以及這類AI工作負載在運算與頻寬之間所需的平衡。本文也將解釋Arm CPU的AI能力,並展示其彈性與可程式化設計性如何促成智慧的軟體優化,為許多LLM應用場景帶來優異的效能與絕佳的機會。
大型語言模型發展現況
各種不同的網路架構都能用來運行生成式AI。不過,由於LLM能用前所未見的規模翻譯與產出文本,外界對其持有高度興趣。
正如大型語言模型的名稱所示,這些模型與2023年之前使用的模型相比絕對要大得多。以下提供一些相關數據:LLM可輕易達到1,000億到1兆個可訓練的參數,代表與基於轉換器(Transformers)的雙向編碼器表示技術(BERT)相比,它的規模至少大上三個數量級,而BERT已經是Google於2018年訓練的最大型的前瞻自然語言處理(NLP)模型之一。
如果以隨機存取記憶體(RAM)的需求來看,若將模型部署於使用浮點16位元加速的處理器之上,那麼具有1,000億個參數的模型將至少需要200GB的RAM。因此,這些大型模型最終被移至雲端上運行。不過,在雲端運行大型模型也產生三個基本的挑戰,進而限制這項技術的採用:高昂的基礎設施成本、隱私權問題(使用者資料可能曝光)、擴充性的挑戰。
大約在2023下半年,我們開始看到一些較小型、效率更高的LLM出現。這些模型將在行動裝置上展現生成式AI的威力,並讓此一技術更為普遍。Meta的LLaMA2、Google的Gemini Nano與Microsoft的Phi-2,在2023年開啟了行動LLM部署的大門,以解決前述的三項挑戰。這些模型分別擁有70億、32.5億與27億個可訓練的參數。
在行動裝置上運行LLM
時下的行動裝置能夠基於Arm技術實現可觀的運算力,因此可以即時運行複雜的AI演算法。事實上,現有的旗艦與高階智慧型手機已經可以運行大型語言模型。
根據預測,未來LLM在行動裝置上的部署將會加速進行,以下為可能出現的使用案例:
.文本生成:例如,我們可能會要求虛擬助理為我們撰寫電子郵件。
.智慧回覆:即時通訊應用軟體可能可以針對問題自動提出建議答覆。
.文本摘要:電子書閱讀器應用軟體可能可以提供整篇章節的摘要。
這些使用場景將產生龐大的使用者資料,而模型必須處理這些資料。由於LLM是在邊緣端、沒有網際網路連線的情況下運行,資料不會離開裝置,有助於保護個人隱私,同時改善使用者在延遲與回應性上的體驗。上述優勢成為在邊緣端於行動裝置上部署LLM的有力理由。
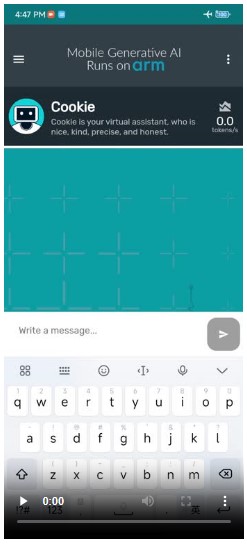 圖1 運用Arm技術在行動裝置運行生成式的示範案例
圖1 運用Arm技術在行動裝置運行生成式的示範案例
Arm近期使用3個Cortex-A700系列的CPU核心,示範在現有安卓(Android)手機上運行LLaMA2-7B LLM的效能(圖1)。展示中,安卓應用軟體的虛擬助理回應性高,能夠快速進行答覆,首個Token時間(Time-to-first Token)回應效能佳,而每秒9.6個token的文本生成速率,也比人類的平均閱讀速度還要快。實現如此性能背後的元素,包括用於AI的現有CPU指令,以及專為LLM進行的軟體優化。
行動裝置解鎖邊緣LLM應用(1)
行動裝置解鎖邊緣LLM應用(2)