近年來隨著人工智慧(AI)與大數據產業的興起,數據資料密集型的應用持續成長,傳統的運算架構無法支撐深度學習大規模並行運算的需求。鑑於AI晶片是人工智慧時代的技術核心之一,越來越多科技業者投入邊緣人工智慧晶片開發,邊緣裝置製造商也希望在產品中添加AI功能。
AI產業興起為IC設計新創企業開啟新市場,這些新創公司打造特殊化晶片藉此加速深度學習以及模型評估,其中位於以色列的AI智慧晶片開發商Hailo,致力於研發人工智慧處理器,其晶片能讓邊緣裝置運行嵌入式AI應用。
借力ANN技術Hailo打造深度學習AI晶片
目前人工智慧晶片有二種發展路徑:一種是延續傳統運算架構,加速硬體運算能力,主要是以圖形處理器(GPU)、現場可編程邏輯閘陣列(FPGA)、特定應用積體電路(ASIC)等三種類型的晶片為代表(但CPU依舊發揮著不可替代的作用);另一種是替代傳統的運算架構而採用類腦神經結構來提升運算能力,其所採用類腦晶片是基於神經形態架構設計,即模仿人類大腦的神經元(Neurons)傳導,因其具有多達千億個以上的神經元,且每個又可透過成千上萬個突觸與其他神經元相連而形成超級龐大的神經元網路。
人工神經網路(Artificial Neural Network, ANN),簡稱神經網路(Neural Network, NN)或類神經網路,在機器學習和認知科學領域是一種模仿生物神經網路(動物的中樞神經系統,特別是大腦)的結構和功能的數學模型或運算模型。因此,人工神經網路是基於一組稱為人工神經元(類似於生物大腦中的神經元)的連接單元且藉由該等大量的人工神經元聯結進行運算。神經元之間的每個連接或突觸可將訊號傳遞給另一個神經元,處理訊號的方式是透過突觸向連接到它的下游神經元發出訊號。神經元和突觸具有隨學習進行而變化的權重,這可增加或減小它發送到下游(Downstream)的訊號的強度。此外,它們可具有臨界值(Threshold),使得只有在總訊號低於或高於該臨界值門檻時才發送訊號到下游。
如圖1,人工神經網路350包括四個網路層(Network Layers) 352,即網路層1至網路層4。每個網路層包括複數個神經元354。輸入X1至X14是對網路層1的輸入。將權重(Weights) 358應用到網路層中的每個神經元的輸入。生成一個網路層的輸出,且該輸出形成對下一個網路層的輸入,直到生成最後的輸出359,即圖1所示之輸出1至輸出3。通常,神經元按層組織,不同的層可對它們的輸入執行不同類型的轉換,訊號可能在好幾遍歷層之後從第一層(即輸入)行進到最後層(即輸出)。
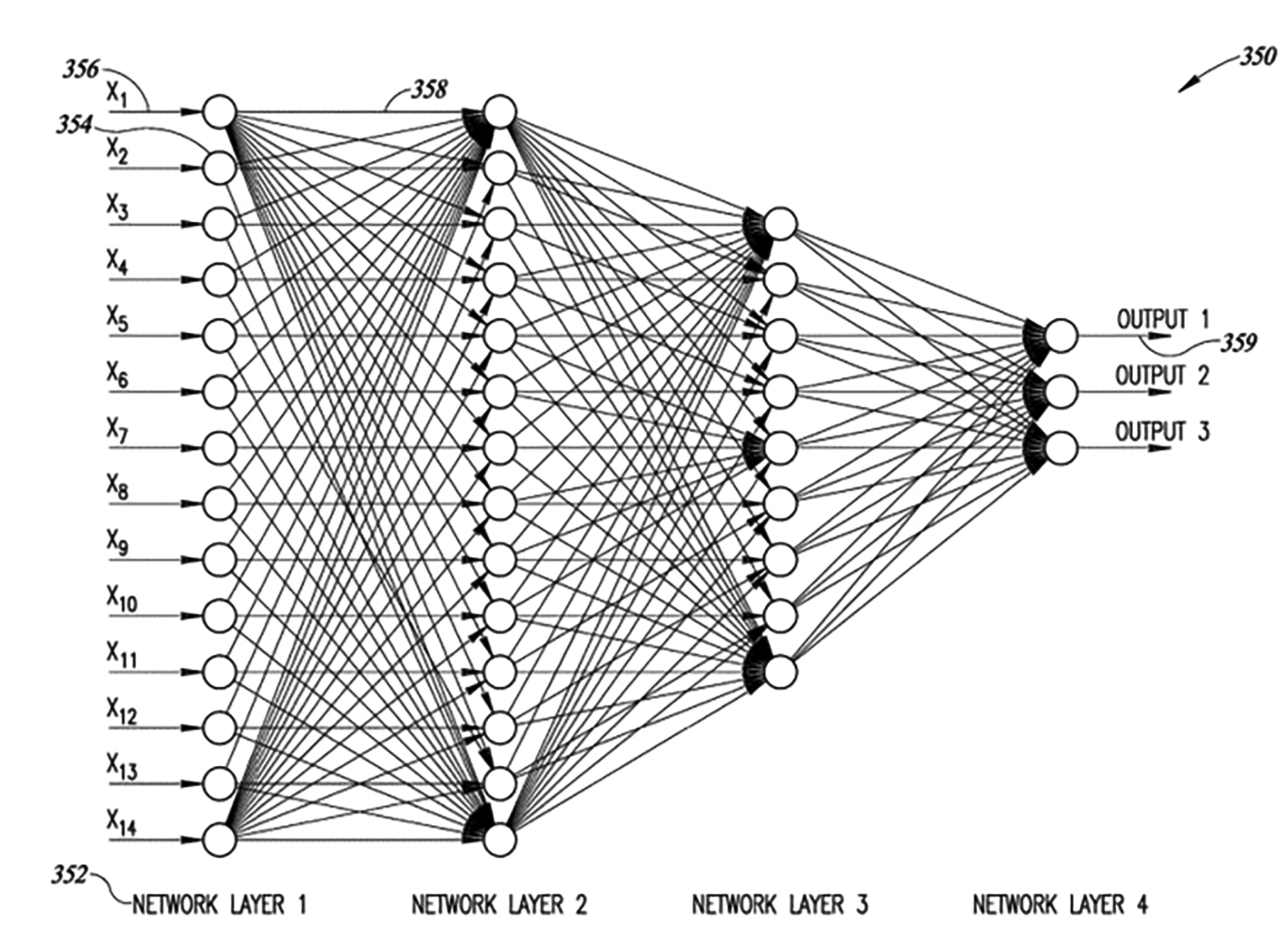 圖1 Hailo人工神經網路示意圖
圖1 Hailo人工神經網路示意圖
因此,歸納人工神經網路的組件包括:(1)具有啟動臨界值的神經元;(2)用於傳遞神經元的輸出的連接和權重;(3)用於運算來自前代神經元輸出的對神經元的輸入的傳播函數;以及(4)學習規則,其是一種演算法,該演算法用以修改神經網路參數以便給定輸入產生期望結果,這通常相當於修改權重和臨界值。
Hailo基於神經網路核心技術設計全新的晶片架構,期望以專精於新興的8位元整數格式在推論取向市場中占有優勢,並讓深度學習能夠在邊緣裝置上執行。Hailo於2019年推出的邊緣設備深度學習AI處理器Hailo-8及其尺度比例[1]。Hailo-8獨特設計旨在加速邊緣設備上的嵌入式AI應用,其邊緣運算處理量最高可達每秒26兆次(TOPS),能源效率為每瓦3TOPS,兼具高效率和高效能,且面積小於一美分硬幣,可滿足低延遲、高傳輸率、高效能等邊緣市場的需求。最近發布新款加速器模組Hailo-8 M.2和Mini PCIe,兩者均搭載其Hailo-8晶片,為邊緣智慧設備(包括自動駕駛車輛、智慧鏡頭、智慧手機、無人機和AR/VR設備)提供更高性能和隱私性。
Hailo專利布局與技術解析
Hailo自2017年起開始申請涉及採用人工神經網路之運算處理器的專利,2018年專利申請量更高達33件。專利申請國別統計如圖2所示,其中以申請美國專利最多,其次為歐洲(EP)專利,亦有日本(JP)、中國大陸(CN)以及透過專利合作條約(Patent Cooperation Treaty, PCT)程序申請的PCT專利申請案(WO)。圖3顯示五階IPC國際專利分類碼分析圖,其中以G06N 3/063(涉及採用電子方式之神經網路、神經元或神經元部分的硬體實現)最多,其次為G06N 3/04(涉及利用神經網路模式之互連體系建構)。
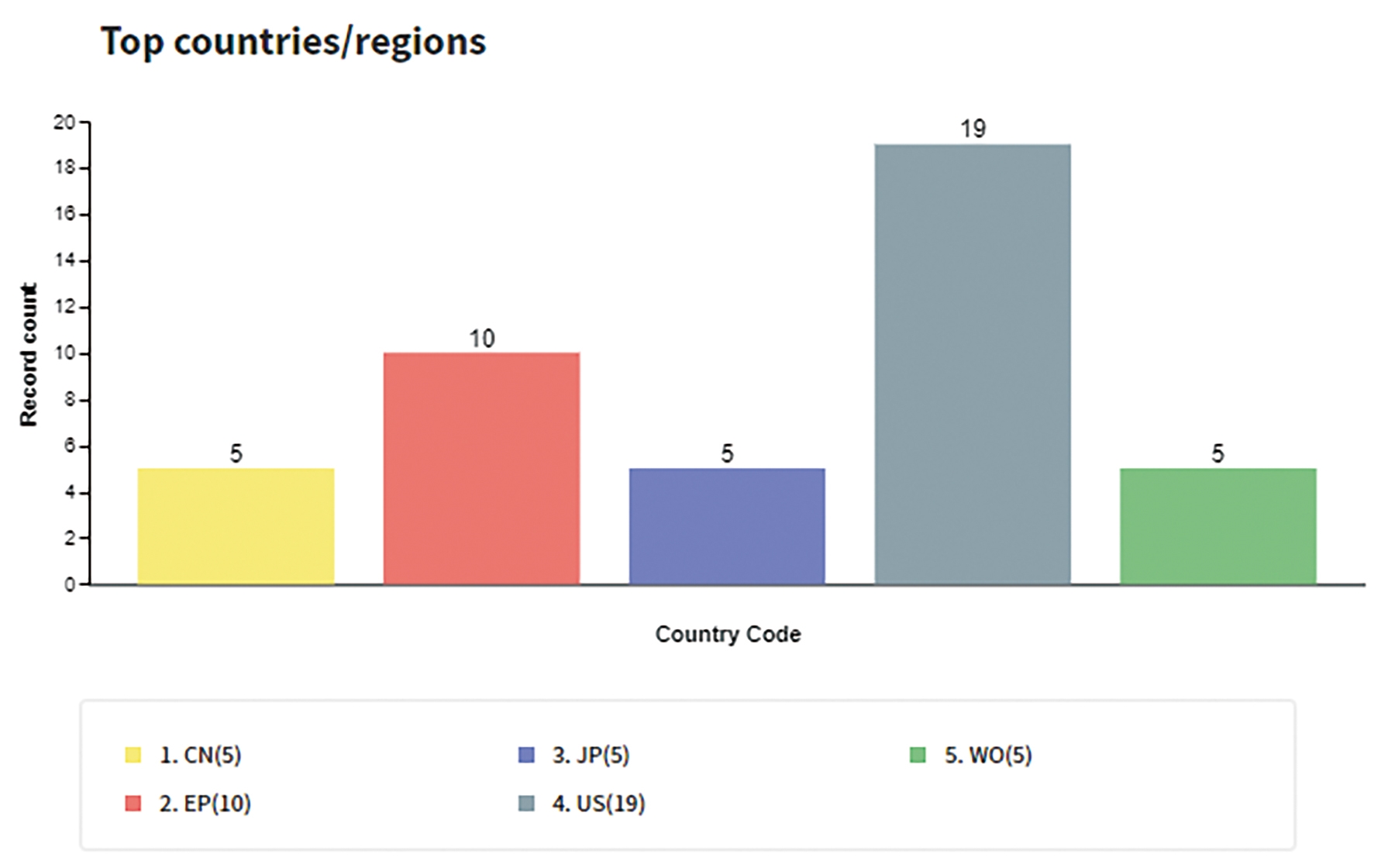 圖2 Hailo專利申請國分析
圖2 Hailo專利申請國分析
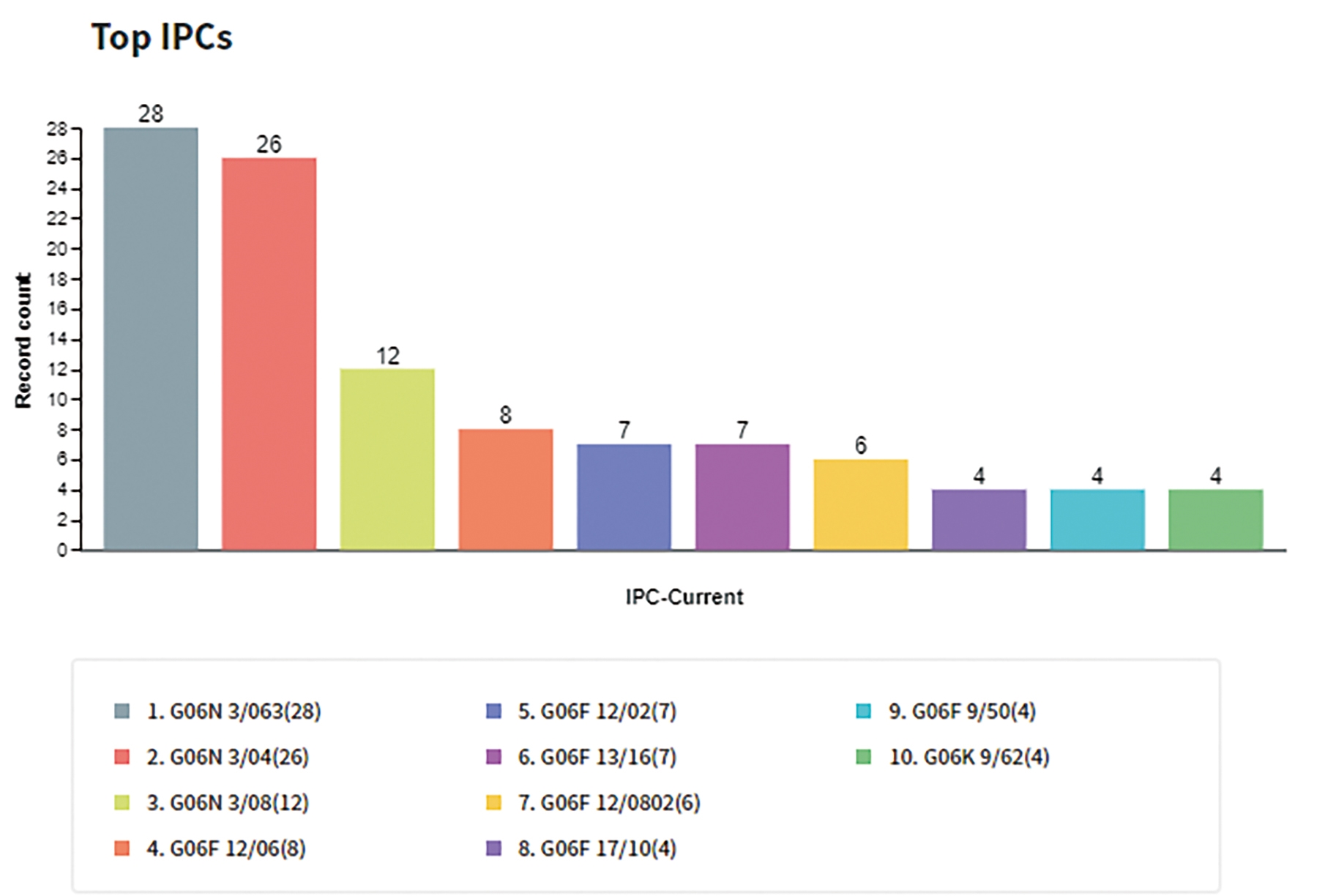 圖3 五階IPC國際專利分類碼分析圖
圖3 五階IPC國際專利分類碼分析圖
結合補充人工神經網路的附加層以擴增現存人工神經網路
美國專利公開號US20180285735A1[2]被自動駕駛系統新創公司Quadric所引用,以其邊緣處理的晶片支持自動駕駛系統實施決策。該專利涉及神經網路領域,更具體地涉及一種透過結合補充人工神經網路(Supplemental Artificial Neural Network)之附加層(Additional Layer)來擴增現存的人工神經網路(Existing Artificial Neural Network)的系統和方法。
圖4顯示包含具有補充人工神經網路之因果擴增人工神經網路的架構。該擴增人工神經網路60包括現存人工神經網路62、補充人工神經網路70以及移位暫存器(Shift Register) 68。現存人工神經網路62被配置為接收一輸入x(t) 64並產生一輸出向量y(t) 66(即推論),補充人工神經網路70係用於接收該輸出y(t)並產生一輸出z(t) 72,移位暫存器68之輸出係被輸入到補充(Supplemental)人工神經網路70。在一實施例中,移位暫存器68包括由複數個暫存器74組成的先進先出型(First in First out, FIFO)堆疊。每個暫存器被配置為存儲補充人工神經網路70所輸出的z(t) 72。補充人工神經網路70輸出的z(t) 72的當前值係輸入到t-1暫存器,以此類推至暫存器L。因此,堆疊保留從時間t-1至時間t-L的輸出「z」值。當產生z(t)的每個連續值時,先進先出型堆疊(FIFO Stack)中之當前值將移到右側相鄰的暫存器中。因此,存儲在t-1暫存器中的值向右移動並存儲在t-2暫存器中,依此類推,直到t-L暫存器,移出的值將被捨棄。在一個實施例中,補充人工神經網路70的輸入因此包括來自現存人工神經網路62的當前輸出y(t)以及z(t)的L個歷史值,即z(t-1)至z(t-L)。
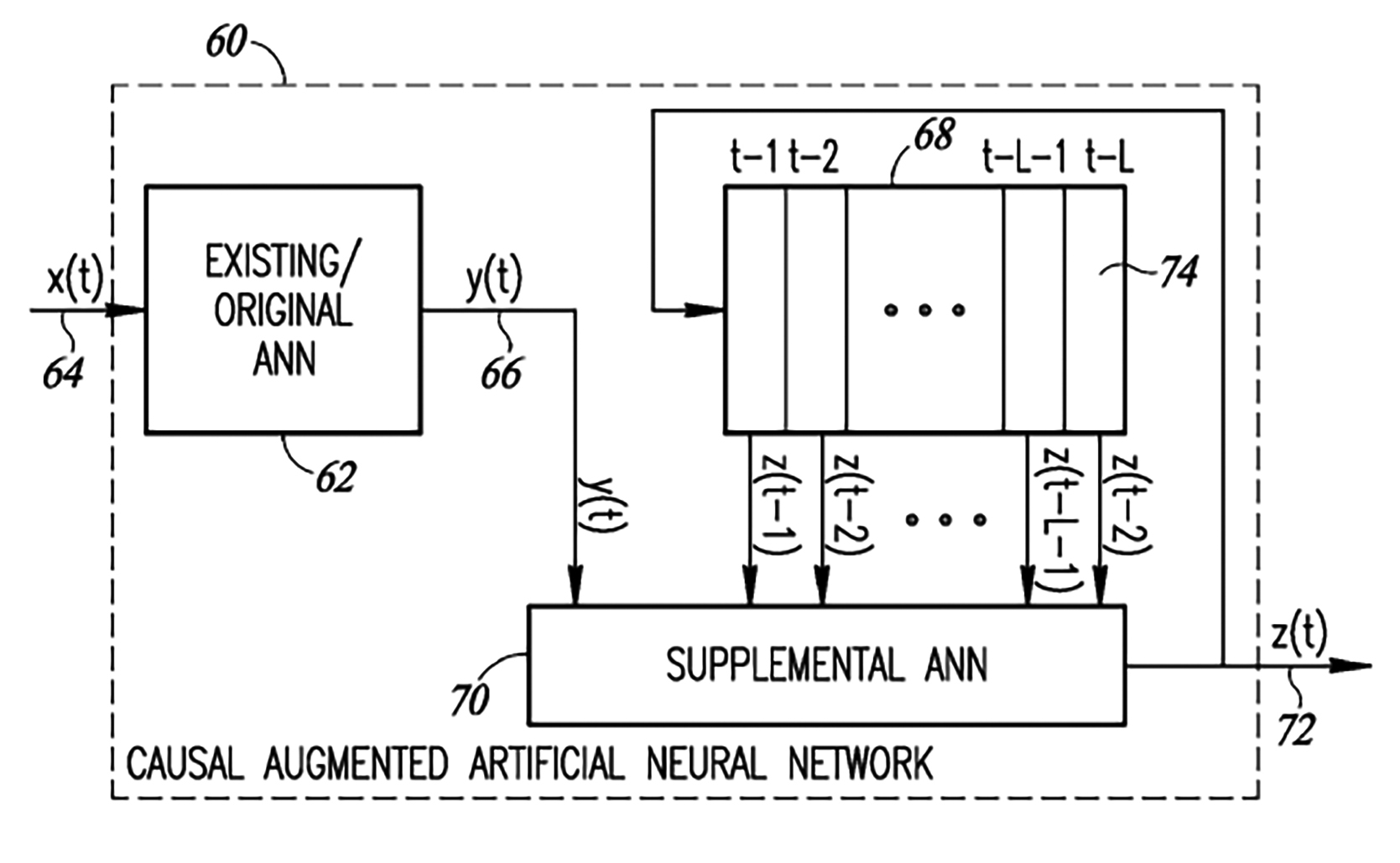 圖4 結合了補充人工神經網路之因果擴增人工神經網路的示意圖
圖4 結合了補充人工神經網路之因果擴增人工神經網路的示意圖
此專利之權利請求項主張一種透過具有補充人工神經網路之附加層來擴增現存人工神經網路的設備與方法,用以接收現存人工神經網路之輸出(當前數據)和補充人工神經網路之輸出的歷史值作為輸入。在整個系統運算輸出時,補充人工神經網路將對現存人工神經網路產生的當前數據和補充人工神經網路產生的過去歷史數據進行分析,並利用其封閉迴路(Closed-loop)依據損失函數產生最佳值。在該系統中,使用補充人工神經網路的「過去」輸出值和現存人工神經網路輸出的「未來」值來決定當前幀(Frame)。此外,該機制不需要重新訓練整個神經網路,也不需要資料集標識(Data Set Labeling)。
按級別聚合之運算電路的多層次結構神經網路處理器
美國專利公開號US20180285718A1[3]被一家以色列晶片公司NeuroBlade所引用,以支援其開發用於人工智慧應用的處理器。該專利涉及用於執行人工神經網路運算的處理器,該處理器包括具有與記憶體元件相關聯的運算元件以及相關的控制邏輯的運算電路,操作上可處理與人工神經網路相關的輸入資料流。其中,該運算電路按級別進行聚合(Aggregated)以形成多個層次結構,層次結構中的較高級別通常較複雜,並且與較低級別相比包含較少的實例化(Instantiations)次數。
在該專利的一個實施例中,圖5詳細地列出低級處理元件140的架構圖。基本運算單元是處理元件(Processing Element, PE) 140。該處理元件140包括由乘法觸發器(Multiply Trigger) 177控制的一個或多個乘法器(Multipliers) 142、由加法器觸發器(Adder Trigger) 171控制的加法器(Adder) 144、包括多個暫存器(Registers) 152的L1記憶體150、由目的地控制(Destination Control) 175控制的目的地多工器(Destination Multiplexer) 146、由源控制(Source Control) 173控制的源多工器(Source Multiplexer) 148、由輸出混洗控制(Output Shuffle Control) 178控制的寫入多工器(Write Multiplexer) 154以及由輸入混洗控制(Input Shuffle Control) 179控制的讀取多工器(Read Multiplexer) 156。來自輸入記憶體158的輸入(x)資料161和來自權重記憶體160的權重(w)163分別根據輸入控制和權重控制提供給一個或複數個乘法器142。
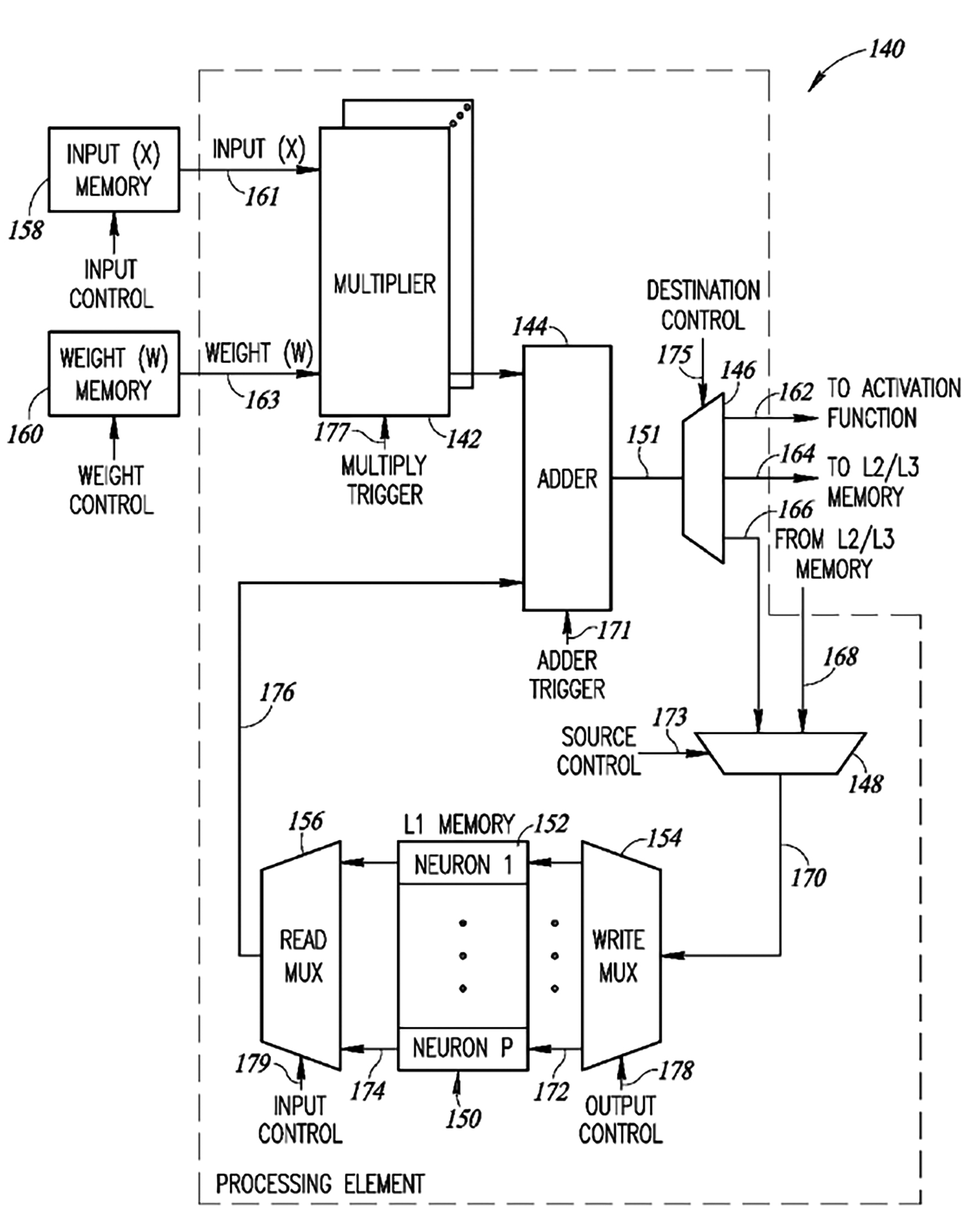 圖5 低階處理單元的示意性架構圖
圖5 低階處理單元的示意性架構圖
神經網路中神經元的最基本的數學運算由式子yj=σ(∑i=0N-1wi,j.xi)限定,其中x(i)表示輸入資料集,其被組織成1維向量;w(i,j)表示對輸出j的第i個輸入貢獻的權重;σ表示啟動函數,其通常是非線性標量函數。
處理元件(PE)140包括反映神經元的內在操作的乘法/累加實體(Multiply/Accumulate Entity),中間結果或成果存儲在L1記憶體150中。實施例中,L1存儲器具有特定的深度和寬度,可使用具有任何期望的深度和寬度的L1記憶體,例如神經元的數量P=16,即該神經元中的每一個是16位寬。L1記憶體的深度P反映了處理元件(PE)140可處理的同步「神經元」或「上下文」的數量。參考圖4,處理元件(PE) 140包括針對權重(w)和輸入(x)單獨控制的計數元件以及對加法器和乘法器的表示格式的單獨控制。
在操作時,處理元件(PE) 140內的資料流程相當靈活,加法器144的輸出151可使用目的地控制175通過目的地多工器146轉向以通過路徑162到啟動函數;或者通過路徑164到L2、L3記憶體;亦或者通過路徑166到源多工器148。源多工器148通過源控制173選擇來自加法器的輸出;或者來自L2或L3記憶體168的中間結果。寫入多工器154經由輸出混洗選擇器(Output Shuffle Select) 178選擇神經元暫存器152中的一個,經由P個路徑172中的一個寫入源多工器148的輸出。經由P路徑174中之一個連接神經元暫存器152到讀取多工器156以讀取L1記憶體中的資料,並經由輸入混洗控制179加以選擇。讀取多工器156的輸出176形成對加法器144的其中一個輸入,另一個對加法器的輸入是乘法器142的輸出。
該專利權利請求項主張一種神經網路處理器電路,用以為具有一個或複數個網路層的人工神經網路執行神經網路運算。
神經網路處理器中基於可配置和可編程滑動視窗的記憶體存取
美國專利公開號US20180285725A1[4]被英特爾(Intel)所引用。該專利係有關於一種連接資源元件的方法,例6涉及建立存取視窗與配置多個資源元件的控制元件,以使存取窗口彼此重疊以形成滑動且受限的存取視窗。圖6為運算和記憶體元件之間之記憶體可存取性(Accessibility)的示意圖,所述之可存取性包括視窗大小和電腦存取可配置性(Computer Access Configurability)。圖6展示了記憶體視窗化方案(Memory Windowing Scheme)中運算元件和記憶體元件之間的存取受到限制。例如,考慮記憶體元件1至D和運算元件1至E。帶陰影線的區域520表示每個元件可存取的資源。因此,運算元件1至3只能存取記憶體元件1至12。類似地,記憶體元件1至12只能連接到運算元件1至3。如圖7所示,運算元件可存取的記憶體元件形成彼此重疊的滑動存取視窗(Sliding Access Windows)。存取窗口的大小(即跨度)和特定的連接性可以動態配置而無需硬連線(Hardwired)或固定(Fixed)。一個關鍵特徵在於任何單個運算元件都不可隨機存取整個記憶體。相反地,每個運算元件只可存取記憶體元件的一部分,例如附近相鄰的記憶體元件。記憶體的運算元件不可存取的部分由白色區域522表示。還應注意,記憶體可存取的運算元件的數量是可程式設計且可配置的(如縱向箭頭523所示)。類似地,運算元件可存取的記憶體元件的數量是可程式設計且可配置的(如橫向箭頭521所示)。
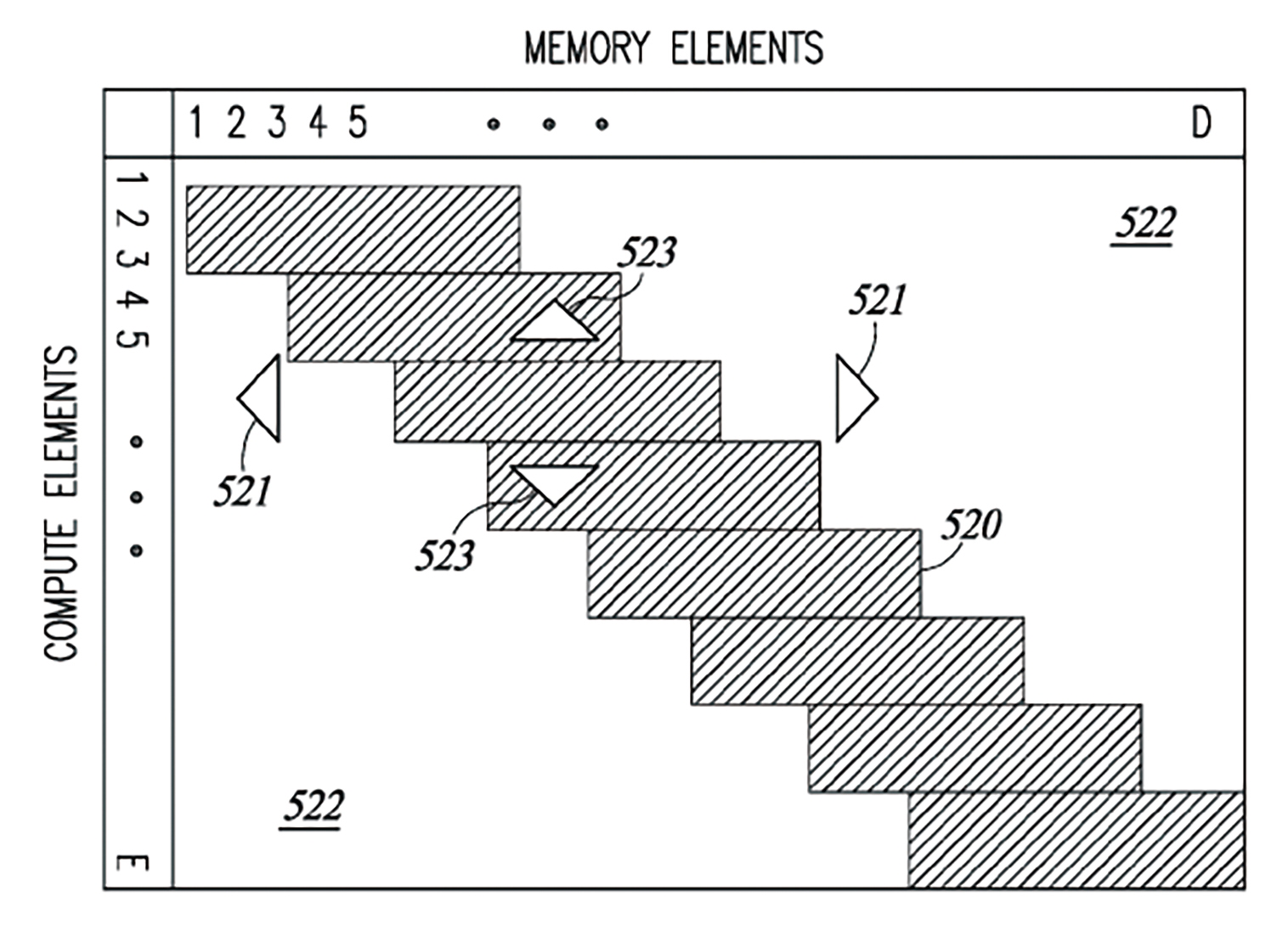 圖6 記憶體存取視窗的可配置性
圖6 記憶體存取視窗的可配置性
該專利之權利請求項主張一種在積體電路中連接第一資源元件與第二資源元件的方法,該積體電路包括用於為具有一個或多個網路層的人工神經網路執行神經網路運算的神經網路處理器電路。其中,該方法涉及在第一資源元件和第二資源元件之間建立一組存取視窗。且對於每個視窗而言,將第一數量的該第一資源元件的存取僅限於第二數量的第二資源元件;將第三數量的該第二資源元件的存取僅限於第四數量的第一資源元件;以及將該等第一數量、第二數量、第三數量和第四數量配置成使得該等存取視窗彼此重疊以形成滑動且受限的存取視窗。因為所有運算都被存儲在記憶體中的中間結果,使得該方法能夠實現輸入資料流被完全地使用且應用至所有需要的運算,同時能將延遲最小化且不需要檢索輸入資料。
聚焦汽車產業關鍵市場
如今,越來越多的車輛配備了智慧駕駛員輔助系統。目前,先進駕駛輔助系統(Advanced Driver Assistance Systems, ADAS)系統主要依賴於專用的智慧相機,它需要強大的運算處理能力,但受限於功率預算及其空間,因此受到傳統處理器(CPU和GPU)的限制。汽車產業正快速地採用深度學習技術促成汽車ADAS與自駕車系統的應用,目前自動駕駛汽車供應商都試著在無數的新一代AI處理器中尋找適用於自駕車的晶片。當今的測試自駕車實際上都在公共道路上行駛,車後行李箱中還配置了一個資料中心,需要一種全新的AI處理器,協助其更有效率地執行相同的深度學習任務。深度學習AI晶片必須有效率地運行高度運算的深度學習演算法,使用於汽車和其他車輛的IC晶片預期將從2016年的229億美元,大幅成長到2021年的429億美元規模[5]。
Hailo過去幾年來觀察到新興業者與新興技術進入到汽車市場,Hailo也看好汽車領域正是其新款AI處理器得以直接發揮的目標市場。為能滿足深度學習以及AI處理的需求,Hailo AI處理器專為汽車輔助系統和自動駕駛系統中之高效、高量產和低功耗的AI處理而建構,使其在較小的功率預算內,它可以在一個或多個高解析度的視訊影像輸入上同時以低延遲且即時方式運行多個神經網路,使其成為支持最先進的ADAS應用的理想之選[6]。Hailo將其領先的深度學習性能引入各種輔助和自動駕駛系統,同時滿足不斷演進發展的安全標準和法規。Hailo正在開發的產品預期將是這場革命性變化的關鍵零組件,見證汽車產業未來爆發性成長的變化,Hailo將扮演著關鍵重要角色。
(本文作者為工業技術研究院技術移轉與法律中心博士)