為了滿足不斷攀升的資料處理需求,未來的系統需在運算能力上進行改善。傳統解決方案(如x86處理器)再也無法以高效率、低成本的方式提供所需運算頻寬,因此系統設計人員須尋找新的運算平台。
越來越多系統設計人員將現場可編程閘陣列(FPGA)和繪圖處理器(GPU)視為能夠滿足未來需求的運算平台。本文將分析未來GPU、FPGA和系統單晶片(SoC)元件,能為新時代提供哪些必要的運算效率和彈性。
雲端資料中心和自動駕駛汽車等未來系統,需在運算能力上進行改善,以支援不斷增加的工作負載,以及不斷演進的底層演算法[1]。例如,大數據分析、機器學習、視覺處理、基因體學以及先進駕駛輔助系統(ADAS)的感測器融合工作負載都超出現有系統(如x86系統)所能提供的效率與成本效益。
系統架構師正在尋找能滿足需求的新運算平台,且該平台需要有足夠的彈性,以便整合至現有架構中,並支援各種工作負載及不斷演進的演算法。此外,許多這類系統還須提供確定性低延遲效能,以支援如自動駕駛汽車在即時系統上所需的快速反應時間。
因GPU在機器學習訓練的高效能運算(HPC)領域獲得的成果,因此GPU廠商非常積極地將GPU定位為新時代運算平台的最佳選擇。在此過程中,GPU廠商已修改其架構來滿足機器學習推論的工作負載。
然而,GPU廠商一直忽視GPU基本架構的局限性。而這些局限會嚴重影響GPU以高效率、低成本方式提供必要的系統級運算效能之能力,例如,在雲端資料中心系統中,工作負載需求在一天內會發生很大的變化,且這些工作負載的底層演算法也正快速地演進。GPU架構的局限性會阻礙很多現今與未來的工作負載映射到GPU,導致硬體閒置或低效率。本文稍後提及的章節,將針對這些局限進行更詳細的介紹。
相反地,FPGA與SoC具有眾多重要特質,將成為解決未來系統需求的最佳選擇。這些獨特特質包括:
看清背景/應用/優劣勢 繪圖處理器大拆解
GPU的起源要追溯到PC時代,輝達(NVIDIA)聲稱在1999年推出世界首款GPU,但其實許多顯卡推出時間更早[2]。GPU是一款全新設計的產品,用於分擔及加速影像處理任務,例如從CPU進行像素陣列的遮蔽和轉換處理,使其架構適用於高平行傳輸率處理[3]。本質上,GPU的主要作用為替視覺顯示器(VDU)提供高品質影像。
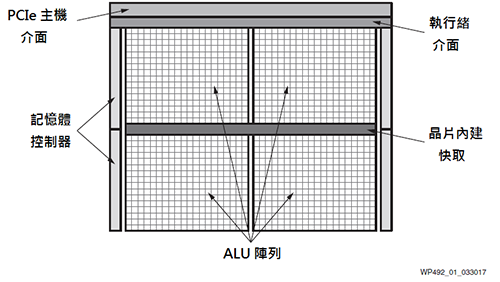 |
| 圖1 GPU模組圖 |
多年來,如大規模矩陣運算的醫療影像應用,此類少量非影像但需大規模平行及受記憶體限制的相關工作負載,已從GPU而非CPU上實現。GPU廠商意識到有機會將GPU市場拓展到非影像應用,因此如OpenCL這類的GPU非影像編程語言應運而生,而這些編程語言將GPU轉化成通用GPU(GPGPU)。
最近,能夠良好映射到GPU運行方案的工作負載之一,便是機器學習訓練。透過充分運用GPU,能明顯縮短深度神經網路的訓練時間。
GPU廠商試圖利用機器學習訓練的成功,來牽動其在機器學習推論上的發展(部署經過訓練的神經網路)。隨著機器學習演算法與所需資料精度的演進,GPU廠商一直在調整其架構以保持自身地位優勢。其中一個例子就是,NVIDIA在其Tesla P4產品中支援INT8,然而現今許多用戶探索著更低的精度,如二進位和三進位[4]。若要利用機器學習與其它領域的發展,GPU用戶必須等待新硬體推出之後再購買。
GPU廠商想運用機器學習作為基礎,使自身成為此新運算時代的首選運算平台。但若要清楚了解GPU是否適合未來系統,仍需做更全面的系統級分析、考量GPU架構的局限性,以及系統要如何隨時間發展演進。
本章節將深入研究典型的GPU架構,來揭露其局限性及如何將其應用於各種演算法和工作負載。
圖1展示典型的GPU模組圖。通用GPU運算功能的核心是大型算術邏輯單元(ALU)或運算核心。這些ALU通常被認為是單指令多執行緒(SIMT),類似於單指令多資料(SIMD)。
基本原理是將工作負載分成數千個平行的執行緒(Thread),ALU需要大量的GPU執行緒來預防閒置。在對執行緒進行調度後,不同的ALU組便能平行執行相同的(單一)指令。GPU廠商透過使用SIMT,能提供相較於CPU占位面積更小和功效更高的方案,因為許多核心資源能與同組的其他核心共享。
然而,顯然特定工作負載(或部分工作負載)能被有效地映射到這大規模平行的架構中[5]。倘若構成工作負載的執行緒不具足夠的共通性或平行性,例如連續或適度平行的工作負載,ALU則會呈現閒置狀態,導致運算效率降低。此外,構成工作負載的執行緒預期要將ALU利用率最大化,進而產生延遲。即使在NVIDIA的Volta架構中使用獨立執行緒調度的功能,其底層架構仍保持SIMT,如同需要大規模平行工作負載。
對於連續、適度平行或稀疏的工作負載,GPU提供的運算與效率低於CPU所能提供的[6]。其中一個量化實例為在GPU上執行稀疏矩陣運算;假使非零元素數量較少,並從效能和效率的角度來看,GPU低於或等同於CPU[7][8]。有趣的是,很多研究人員正在研究稀疏卷積式類神經網路,來利用卷積式類神經網路中的大規模冗餘[9],這趨勢顯然代表GPU在機器學習推論中所遇到的挑戰。稀疏矩陣運算也是大數據分析中的關鍵環節[10]。
多數包含大量平行運算任務的工作負載亦包含一些連續或適度平行元素,這意味著需要GPU-CPU混合系統來滿足系統效能要求[11]。顯然,對於高階CPU的需求會影響平台的效率與成本效益,而且CPU與GPU之間的通訊需求為系統增添潛在瓶頸。SIMT/GPU架構的另一個局限性是ALU的功能取決於其固定指令集和所支援的資料類型。
系統設計人員正在探索簡化資料類型精度,以此達到運算效能的跳躍式提升,而且不會明顯降低精度[12][13][14]。機器學習推論導致精度下降,首先是FP16,接著是INT16和INT8。研究人員正在探索進一步降低精度,甚至降到二進位[4][15]。
GPU ALU通常原生支援單精度浮點類型(FP32),而有些情況下支援雙精度浮點(FP64)。FP32是影像工作負載的首選精度,而FP64通常用於一些HPC應用。然而低於FP32的精度通常無法在GPU中獲得有效支援,因此相較於降低所需的記憶體頻寬,採用標準GPU上降低精度較有優勢。
GPU通常提供一些二進位運算功能,但通常只能每ALU進行32位元運算,且32二進位運算有很大的複雜度和面積需求。在二值化神經網路中,演算法需要XNOR運算,緊接著進行族群(Population)統計。由於NVIDIA GPU僅能每四個週期進行一次族群統計運算,因此對二進位運算有極大的影響[18]。
如圖2所示,為了跟上機器學習推論空間的發展腳步,GPU廠商持續進行必要的晶片修改,以支援如FP16和INT8的有限降低精度資料類型。其中一個實例為,Tesla P4和P40運算卡上的NVIDIA GPU支援INT8,為每ALU/Cuda核心提供4個INT8運算。
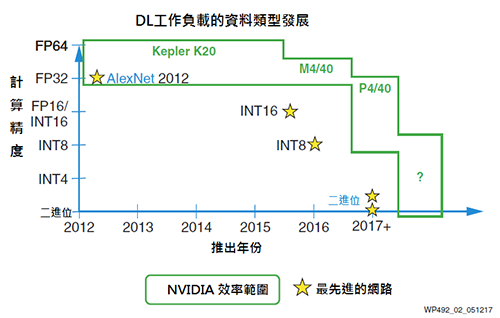 |
| 圖2 NVIDIA降精度支援 |
然而,依NVIDIA在Tesla P40上的GoogLeNet v1 Inference推出的機器學習推論基準顯示,INT8方案與FP32方案相比效率僅提升3倍,此結果顯示在GPU架構中強行降低精度,並取得高效率存在較大難度[16]。
隨著機器學習和其他工作負載轉向更低精度和客製化精度,GPU廠商需要在市場上推出更多新產品,且廠商的現有用戶亦需升級平台,才能受益於此領域的發展。
記憶體多階層把關 軟體定義資料到達路徑艱辛
與CPU類似,GPU中的資料流也由軟體定義,並取決於GPU嚴格且複雜的記憶體階層[17],而典型的GPU記憶體階層如圖3所示。每個執行緒在暫存器檔案中都有自己的記憶體空間,用以儲存執行緒的區域變數。同一個模組內的少量執行緒可透過共享記憶體來通訊;且所有執行緒皆能透過全域或晶片外記憶體通訊[18]。
如圖3所示,由於資料需從暫存器檔案橫跨整個記憶體階層到全域記憶體,造成與記憶體存取相關的功耗和延遲分別增加100倍和80倍以上[15][17][19]。此外,記憶體衝突是必然的,同時亦會增加延遲導致ALU閒置,進而降低運算能力和效率。
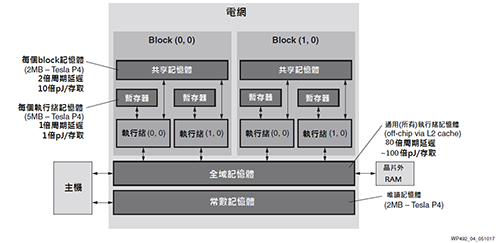 |
| 圖3 典型的GPU記憶體階層 |
因此,若想發揮GPU的運算和效率潛能,工作負載的資料流必須準確映射到GPU記憶體階層。事實上,很少工作負載具備足夠的資料局部性來有效地映射到GPU上。對多數的工作負載而言,當在GPU上運行時,實際的運算能力和效率會大打折扣,解決方案的延遲也會增加[19][20]。
機器學習推論作為量化實例,能清楚展現出資料流的局限性。GPU必須進行如128筆的批次處理(Batch),以獲得高效率但延遲更長的解決方案。最終,批次處理使機器學習處理局部化,但須付出增加延遲的代價[21],而此結果能清楚的在GoogLeNet v1 Inference的NVIDIA P40基準測試中看到。對於GoogLeNet v1來說,其網路因P40記憶體頻寬而受到運算束縛,因此減少與批次處理有關的記憶體頻寬並不會產生很大的幫助。然而,P40顯然需要透過128的批次處理以達到50%的GPU理論效能,但同時也增加系統的延遲[16]。
某些情況下,資料可透過CPU進行前置處理,以便工作負載能更有效的映射到GPU SIMT架構和記憶體階層,但其代價則是產生更多CPU運算和功耗,因而抵消了GPU的優勢[7]。
如本文一開始的段落所述,GPU原本的角色是作為協同處理器。為了促進與主機溝通,GPU以往只有一個PCIe介面與幾個如GDDR5的晶片外接DRAM介面。近期的產品中,有些GPU採用硬體介面來進行GPU到GPU的通訊。而CPU仍須連接網路來分配任務予GPU,此不僅增加系統功耗,還會因PCIe有限的頻寬而帶來瓶頸。例如,支援PCIe 3.0×16的NVIDIA Tesla 40,只能擁有16GB/s的頻寬。
GPU廠商已開始建構小型SoC,例如NVIDIA Tegra X1,其能整合GPU運算、Arm處理器、一些通用汽車周邊和如HDMI、MIPI、SIP、CAN的基礎乙太網路等。由於上述元件具備少量運算能力,因此必須倚賴額外的分離式GPU來達到必要的運算能力。然而,分離的GPU介面有很大局限性,例如Tegra X1僅支援PCIe 2.0×4,導致嚴重瓶頸,且額外SoC的功耗會更進一步降低平台的效率。
除了延遲、效率和傳輸率方面的不利影響,晶片外記憶體的頻寬要明顯低於局部/晶片內建記憶體。因此,若工作負載需要依靠晶片外記憶體,不僅晶片外記憶體的頻寬會成為瓶頸,且運算資源也會被閒置,從而降低GPU能提供的運算功能和效率。
因此,更有利的做法是採用大型、低延遲且高頻寬的晶片內建記憶體,再以機器學習推論為例,GoogLeNet共需27.2MB的記憶體空間;假設執行FP32,是沒有GPU能提供的,這意味著需要晶片外記憶體[22]。在很多情況下,則需採用高成本的高頻寬記憶體(HBM)和批次處理,以防止核心處於閒置狀態。若選擇具更大型的晶片內建記憶體元件,便能避免HBM成本及額外的延遲和功耗問題。
GPU廠商在設計板卡和GPU時通常要適用於250W的功耗上限,並依靠有效熱管理來調節溫度。針對機器學習推論市場,NVIDIA已開發如Tesla M4和P4等滿足75W功耗範圍的元件。雖然75W已遠超出所允許的系統級功耗和熱範圍,但GPU的絕對功耗依然是阻礙GPU被廣泛採用的因素之一。
功能安全性
GPU源於消費影像處理和高效能運算領域,其不存在功能安全性的需求。但隨著GPU廠商瞄準ADAS市場,功能安全性就成了必要條件,因此為用於ADAS系統中,元件需要重新設計,以確保達到所需的功能安全性認證等級。這對GPU廠商來說不僅是一個長期且涉及各方面的學習過程,還需要新工具和設備。
實現多元應用推手 FPGA/SoC好處多
與GPU擁護者的說法不同,單一個FPGA元件能提供的原始運算能力,能達到38.3 INT8 TOP/s的效能。NVIDIA Tesla P40加速卡以基礎頻率運行時提供相似的40 INT8 TOP/s原始運算能力,但功耗是FPGA方案的2倍多[26]。
此外,FPGA元件的彈性能支援各種資料類型的精度[27]。例如,針對二值化神經網路,FPGA可提供500TOPs/s的超高二進位運算能力(假設2.5LUT/運算的情況),相當於GPU典型效能的25倍。有些精度較適用於DSP資源,有些則能在可編程邏輯中運行,還有些適合將兩者結合起來使用,而這些彈性確保元件的運算和效率能隨著精度降低,且降低到二進位。機器學習領域的大量研究都從運算、精度和效率角度來進行最佳精度的研究[28~32]。無論最佳點在哪,對於給予的工作負載都能隨之調整。
多年來,許多FPGA用戶針對多種工作負載,運用脈動陣列處理設計達到最佳效能,其中包括機器學習推論[33][34]。
有趣的是,NVIDIA為了現今的深度學習工作負載來提高可用的運算能力和效率,在Volta架構中以Tensor Core形式強化類似的功能。然而,深度學習工作負載會隨著時間演進,因此Tensor Core架構亦需要改變,且GPU用戶也需等待購買新的GPU硬體。
從系統層級來看,運算平台必須在指定的功率和熱範圍內提供最大運算能力。為滿足此需求,運算平台必須:
1. 處於允許的功率範圍內
2. 在功率預算內將運算能力最大化
All Programmable系列元件,使用戶能選擇與功率和熱範圍最相符的元件。如表1所示,從原始運算角度來看,該元件能針對固定精度資料類型提供高效通用運算平台,主要是因為FPGA架構中的間接開銷較低。例如,GPU需要更多複雜性圍繞其運算資源,以促進軟體可編程功能。對於當今的深度學習工作負載的張量(Tensor)運算,NVIDIA的Tesla V100憑藉已強化的Tensor Core達到能與FPGA和SoC匹敵的效率。然而,深度學習工作負載正以非常快的速度演進,因此無法確定NVIDIA Tensor Core的高效率能在深度學習工作負載維持多久。
由此看來,對於其他通用工作負載,NVIDIA V100亦面臨效率的挑戰。鑑於本文之前介紹的局限性,對於實際的工作負載與系統,GPU很難達到如表1中所提供的數字。
賽靈思透過將硬體可編程資源(如邏輯、路徑和I/O)與具彈性且獨立的整合核心區塊(如DSP分割和UltraRAM)結合,並將全部構建在領先製程技術上,如台積電(TSMC)的16nm FinFET製程,進而達到這種平衡。
硬體可編程性和彈性,意味著底層硬體通過配置可滿足指定工作負載的需求。隨後,資料路徑甚至能在運行時,透過部分可重組功能簡易地進行重新配置[35]。圖4試圖舉例All Programmable元件提供的部分彈性。核心(或用戶設計元素)可直接連接可編程I/O、任意其它核心、LUTRAM、Block RAM和UltraRAM、及外部記憶體等。
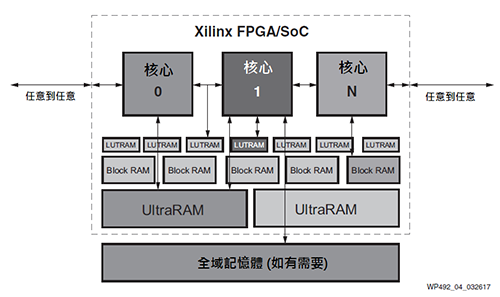 |
| 圖4 All Programmable資料路徑和各種形式IO |
硬體可編程性元件意味著它們不存在這類的特定局限,如SIMT或固定資料路徑等。無論是大規模平行、適度平行、管線連續或混合形式,都能獲得賽靈思元件的運算能力和效率。此外,若底層演算法改變,例如機器學習網路的發展,則平台也能隨之調整。
很多系統和工作負載中都能看到FPGA與SoC元件發揮彈性優勢,而機器學習推論就是其中之一。其中機器學習推論的趨勢就是向稀疏網路邁進,且FPGA與SoC元件用戶已在利用此趨勢,而NVIDIA本身就是其中一位用戶。在近期與NVIDIA聯合編寫關於語音辨識的一篇文章中提到,通過使用FPGA,相較於CPU能提升43倍速度和40倍效率,而NVIDIA GPU僅能提升3倍速度和11.5倍效率[36]。可編程資料路徑還減少了FPGA的批處理需求,批處理是系統延遲對比即時效能的重要決定因素。
從大數據角度來看,FPGA在處理包括在如可變長度字符串的複雜資料情況下,SQL工作負載時具高效率且快速。基因體分析則是一個實例,有人已利用GPU來加速基因體分析,其相較於Intel Xeon CPU方案能提升6至10倍的速度[40]。不過,FPGA提升速度的效果更高,相較於同等CPU可提升約80倍的速度[41]。
最後,對於正在努力研發自動駕駛功能的汽車系統設計人員來說,FPGA與SoC元件的靈活能為他們提供可擴展的平台,以滿足美國汽車工程學會(SAE)各種完全自動駕駛道路的標準。
除了元件運算資源的彈性,FPGA的各種形式之I/O彈性能確保元件無縫整合至既有的基礎架構,例如在不使用主機CPU的情況下,直接連接到網路或儲存設備[42]。此外,I/O彈性還允許平台針對基礎架構的變化或更新進行調整。
如表2所示,這種龐大的晶片內建記憶體快取,代表著多數的工作負載記憶體需求是透過晶片內建記憶體提供,來降低外部記憶體存取所帶來的記憶體瓶頸,以及如HBM2這類高頻寬記憶體的功耗和成本問題。例如,針對多數深度學習網路技術(例如GoogLeNet)的係數/特性圖都可存在晶片內建記憶體中,以提高運算效率和降低成本。晶片內建存取能消除晶片外記憶體存取所引起的巨大延遲問題,將系統的效能最大化。
針對需要高頻寬記憶體的情況下,FPGA元件提供HBM,以便工作負載有效的映射到元件和可用記憶體頻寬,將效能和運算效率最大化。
在新的運算時代,系統設計人員面臨許多困難選擇。FPGA和SoC為系統設計人員提供最低風險,來協助其滿足未來系統的核心需求與挑戰,同時提供足夠的彈性以確保平台在未來不會落伍,堪稱兼顧雙重需求。在深度學習領域,UltraScale架構中DSP架構固有的平行性透過INT8向量點積的擴展性效能,為神經網路強化卷積和矩陣乘法傳輸率,使得深度學習推論達到更低延遲。快速DSP陣列、最高效率的Block RAM記憶體階層及UltraRAM記憶體陣列的組合可達到最佳功率效益。
(本文作者皆任職於賽靈思)