目前市面上的智慧型手機,不論是iPhone還是Android手機,內部處理晶片中都含有嵌入式圖形處理器(Embedded GPU),提供遊戲與介面呈現所需的圖形處理能力。這樣的產品規格也慢慢地滲透到如電視或機上盒(STB)等的其他電子產品上。可以預見的是,未來只要有搭載顯示螢幕的電子產品,多將搭載嵌入式繪圖處理器,以提供即時三維(3D)互動應用。
然而,由於3D應用工作量(Workload)的不規則性,以及繪圖處理器(GPU)設計原則(需要高記憶體頻寬)與中央處理器(CPU)設計原則(需要低記憶體存取延遲)不同等因素,讓系統單晶片(SoC)的軟硬體開發者遭遇新的整合開發難題。針對以上所面臨的情況,以下介紹嵌入式繪圖處理器市場潛力與目前解決方案現況,並概述在嵌入式繪圖處理器整合上可能的解決方式。
嵌入式繪圖處理器市場看好
嵌入式繪圖處理器近幾年的需求量越來越高,其主要動力來自於蘋果(Apple)的iPhone與Google的Android裝置迅速地席捲智慧型手機(Smart Phone)市場。在iPhone推出前,雖然已經有某些硬體如OMAP3等支援3D加速,然而因缺乏足夠且吸引人的內容,因此還無法讓終端裝置開發商願意採用這些硬體。
蘋果的iPhone與其App Store是推動3D遊戲開始普及到行動裝置的關鍵。而開放的Android平台與Android Market上越來越多的應用程式(App),則讓裝置品牌廠與白牌廠商紛紛採用Android系統,進而快速推升Android平台的市占率。
對Android平台而言,繪圖處理器是加速其圖形介面系統(GUI)處理速度的必要硬體。因此Android平台市占率的不斷擴大,也意謂著搭載嵌入式繪圖處理器硬體平台的出貨量不斷增加。
此外,蘋果與Google進一步地擴展其產品線至平板電腦與智慧型電視(Smart TV)領域上,則把嵌入式繪圖處理器的需求帶入平板電腦與新一代的聯網電視(Connected TV)與機上盒,甚至是DVD播放器等市場。
嵌入式繪圖處理器也被應用到車載資通訊(Telematics)系統中的儀表板(Dashboard)與導航系統上,包括富士通(Fujitsu)、瑞薩(Renesas)等皆推出具嵌入式繪圖處理器之車載資通訊系統硬體解決方案。輝達(NVIDIA)亦宣布其Tegra平台被奧迪(Audi)、寶馬(BMW)、Tesla等車廠採用為其車載資通訊系統的硬體。
根據資策會資訊市場情報中心(MIC)相關市場調查報告,包括智慧型手機、功能性手機(Feature Phone)、平板電腦、機上盒(含OTT、數位地面廣播與數位衛星)、數位相框、數位相機(DSC)與車載資通訊系統等產品,在2015年將會有約二十一億台的出貨量是搭載有嵌入式繪圖處理器。
OpenGL ES新規格呼之欲出
嵌入式繪圖處理器的功能取決於其所支援的3D應用程式介面(Application Programming Interface, API),目前在行動裝置等嵌入式產品市場中,3D API的主流為由Khronos Group所制定與維護的OpenGL ES。現行的OpenGL ES有兩個版本,包括支援固定繪圖功能(Fixed Function)的OpenGL ES 1.x與可程式化(Programmable)的OpenGL ES 2.0。其中,OpenGL ES 2.0是中高階電子裝置之3D API主流。
新一代的OpenGL ES 3.0規格若無意外應該在今年SIGGRAPH會議中公開,但因為不像DirectX是由微軟(Microsoft)單一家公司所制定,在眾多公司的折衝下,OpenGL ES 3.0規格的進步幅度,恐不若DirectX 9.0演進至DirectX 10那樣順利。
目前嵌入式繪圖處理器的繪製架構大致可分為兩種,一種統稱為立即模式描繪(Immediate Mode Rendering)(圖1),另一種則是磚牆式延緩描繪(Tile Based Deferred Rendering)(圖2)。Immediate Mode Rendering架構是指當繪圖處理器收到一個繪圖命令(Draw Call)時,會立即將它處理完畢。該繪圖命令與其相關的資料進入嵌入式繪圖處理器的繪圖管線(Rendering Pipeline)中,經過頂點處理(Vertex Shader)、繪製三角形(Rasterization)、像素處理(Pixel Shader)等運算過程後,直接把結果輸出到繪圖緩衝儲存區(Frame Buffer)之上。
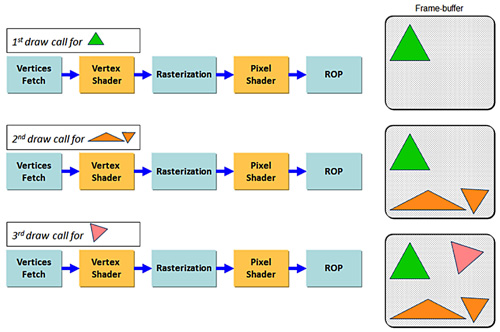 |
| 圖1 Immediate Mode Rendering架構示意圖 |
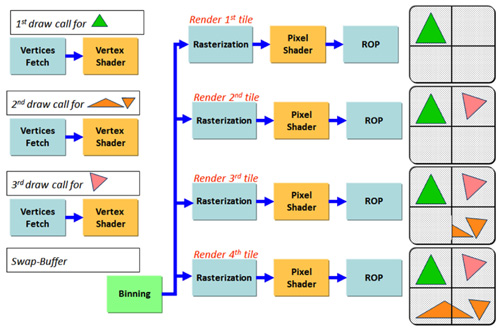 |
| 圖2 Tile Based Deferred Rendering架構示意圖 |
Tile Based Deferred Rendering則是先將繪圖命令運算至繪製三角形(Rasterization)階段前先暫存起來,待累積足夠的繪圖命令後(通常是一個Frame的資料),再逐一針對各螢幕區域(Tile)所含蓋的繪圖命令進行後續的繪製運算。
Immediate Mode Rendering架構與Tile Based Deferred Rendering架構各有擅長,在不同的3D應用程式下,效能與記憶體耗用量的表現各有優劣。Immediate Mode Rendering架構通常都能支援多個繪圖命令在嵌入式繪圖處理器中被執行,而有較好的繪製效能;Tile Based Deferred Rendering架構則可以在快取記憶體(On-chip Cache)上完成一個螢幕區域上的像素處理動作,因此通常有較低的記憶體耗用量。但是,Tile Based Deferred Rendering架構因為須要把讀入的頂點(Vertex)資料在處理過程中先寫至晶片外(Off-chip)記憶體,然後進行螢幕區域繪製前再讀回來,增加了不少頂點資料的記憶體耗用量。
IP商各展所長競爭白熱化
目前市場上嵌入式繪圖處理器的矽智財(Soft IP)提供商主要有Digital Media Professional(DMP)、Imagination Technologies、安謀國際(ARM)、圖芯技術(Vivante)、Takumi等(圖3)。根據Jon Peddie Research的資料,目前以Imagination Technologies市占率最高,其次則是圖芯技術與DMP。其中僅Takumi尚未推出OpenGL ES 2.0的解決方案。
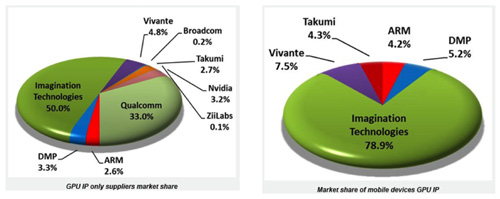 |
資料來源:http://www.eetimes.com/electronics-news/4304118/Imagination-outstrips-all-other-GPU-IP-suppliers)
圖3 Embedded GPU Soft IP提供商市占率 |
在這些嵌入式繪圖處理器矽智財提供商中,以日商DMP最不為台灣產業所熟悉,但若提到任天堂(Nintendo)新一代的掌上型遊戲機3DS,其精緻的立體3D內容的繪製就是透過DMP的嵌入式繪圖處理器繪圖的運算能力,就能夠讓人體認到DMP精湛的技術能力。
DMP的嵌入式繪圖處理器方案(代號SMAPH-S),除了能夠支援所有主要的3D與向量(Vector Graphics)繪圖API與OpenCL運算API外,其彈性(Scalable)與模組化(Modular)的架構設計,使其能有足夠的產品組態(Configuration),讓SoC客戶可以藉由挑選Shader Processor數量與Pixel Pipe數量等組態之方式,找到一個最合乎其產品能力與成本需求的繪圖處理器方案。
值得一提的是,DMP在今年5月初發表一個代號為SMAPH-S Lite的組態(圖4)。SMAPH-S Lite僅有一個Shader Processor,DMP透過對Shader Processor執行緒管理方式的調校,以及對Shader Processor內容運算精確度的調整,讓SMAPH-S Lite不但是目前市面上晶片面積最小且OpenGL ES 2.0功能完整的嵌入式繪圖處理器矽智財,並且仍然可以提供好的3D效能表現。
 |
| 圖4 DMP SMAPH-S產品組態圖 |
DMP的SMAPH-S採用一個名為分享串流(Shared Stream)的架構,透過排程器(Smart Scheduler)有效率的管理,讓繪圖處理階段的資料與Shader Processor中的執行緒資料(Thread Context)都存放在一個共用的記憶體中,因此讓SMAPH-S所占用的晶片面積非常的小,而有非常好的效能(Performance)/區域(Area)表現。
 |
| 圖5 MAESTRO技術所產生之效果 |
DMP另一個獨門技術則是稱為MAESTRO的遊戲特效加速技術,這也是讓任天堂在3DS上採用DMP嵌入式繪圖處理器矽智財的原因。MAESTRO能夠針對常用如凹凸貼圖(Bump Mapping)、柔和陰影(Soft Shadow)等的遊戲特效,以及細分曲面(Subdivision Surface)或算法紋理(Procedural Texture)之類的遊戲運算功能進行加速,因此能夠以更短的時間與更低的耗能,繪製出更精緻的3D內容(圖5)。MAESTRO業採用模組化設計,讓客戶可以在任何SMAPH-S組態上加入所需的MAESTRO功能。
可以預見,在DMP和Imagination Technologies等嵌入式繪圖處理器矽智財提供商的良性競爭下,未來電子裝置上都將能有今日遊戲機般的3D繪圖效能與顯示品質,此將進一步激發出更多創新的人機互動應用。
整合門檻高 CycProfiler套件有解
隨著系統晶片技術的進展,系統晶片的複雜度越來越高。多媒體平台系統晶片因為消費性電子產品的需求高漲而競爭激烈,從高階到低階平台,手機到電視等產品,都是戰況慘烈的戰場。
高階多媒體晶片不但須提供高解析度的影音應用,還必須要能夠聯網,並執行各種的第三方的App,走向智慧型的多媒體平台,如此系統必須包括多核心CPU外,還需要多核心的繪圖處理器來處理圖形的應用。這樣複雜系統不但設計規格要高,整系統的效能也是影響產品成功的主要原因。
系統晶片對於成本,系統效能,耗電量等等都很有幫助,但是因為系統的複雜度不斷地提升,使得系統晶片內的矽智財(IP)越來越多,記憶體系統越來越龐大,資料溝通的成本提升,使得系統效能下降。將各種功能的IP整合到一個晶片電路變成只是基本的工作,整體系統效能才是最重要的,如何在非常複雜的系統內找出效能瓶頸點,再加以調校,也必須要花費相當多的人力和時間成本。
過往系統晶片的功能很單純,設計通常是從紙上談兵開始的,只須要統計並分析各個IP的規格和需求,計算終端應用軟體所需要資料頻寬。基於量化的統計分析來設計系統晶片的規格和架構。這個方法套用在簡單的系統晶片,只須要有經驗的工程師經過仔細的分析,便可以設計出一個符合效能需求的系統晶片。但是,現今要應付的廣泛應用,系統晶片可能是多核心CPU,還有許多會消耗大量資料頻寬的多媒體IP,加上Network Based Bus System,如此複雜的系統行為是很難預測的。
繪圖處理器的角色也越來越重要,除了協助3D圖形的處理,還須擔負二維(2D)影像的疊合混色與顯示,效能規格越來越高,複雜度也超越CPU,並同時進入多核心的時代。GPU IP的平行運算能力相當的高,但同時會消耗十分巨量的資料,所需要的頻寬相當多,一旦無法供給足夠資料頻寬,整體效能便會快速下降。多核心繪圖處理器的整合已經變成現今的系統晶片的主要問題。
在現今的SoC的設計中,軟體所扮演的角色重要性日益顯著,尤其在加入繪圖處理器的圖形應用後,繪圖處理器的應用須要撰寫OpenGL ES的程式,而現在更邁入OpenGL ES 2.0,搭載Programmable Shader Core,不但要搭配OpenGL ES的API,還得撰寫繪製語言(Shading Language),在在都使驗證與測試的困難度升高。原本的方法已經難以應付這樣複雜系統的設計,必須有更先進的設計方法提供支援,且最佳化系統架構設計,將系統效能往上提升。
電子系統級(Electronic System Level, ESL)設計方法,已經在IC設計業界推行多年,ESL並非是一個全新名詞,即是所謂的系統級設計(System Level Design),問世已有10多年的歷史,這個技術也在國外眾多設計大廠使用多年,但是在台灣仍不是很普遍,許多的IC設計公司仍採用過往的方式來設計系統晶片。主要原因可能是導入ESL的成本太高,加上台灣廠商即時上市(Time to Market)的產品壓力很大,所以沒有資源導入ESL重新設計架構。
但是,系統晶片規格越來越高,越來越複雜,產品卻沒有時間重新設計,導致功能問題與效能不佳,只好投入更多的人力於後期做有限的處理,導致惡性循環,問題越來越多。
資策會DeltApex團隊針對系統晶片的繪圖處理器圖形處理子系統,提出一個介於中間的解決方案來最佳化系統架構的設計--CycProfiler套件。這個套件毋須重新建立ESL的基礎元件,可以直接在系統晶片嵌入一個監控效能的元件,將監控的數據再交給分析軟體,進行問題分析,然後根據分析結果調整設計。並且,可以建構在模擬環境及現場可編程閘陣列(FPGA)環境,得到不同層次的分析資料。比起ESL,這個方法能夠植入現有的系統晶片設計中進行分析和調整,以減少建構ESL的成本。CycProfiler套件的架構如圖6所示。
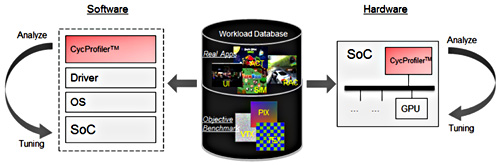 |
| 圖6 CycProfiler套件架構圖 |
從前面的描述可知,圖形應用的軟硬體驗證與測試的困難度高,問題在於圖形應用的類型十分廣泛,所以Workload的行為差異相當的大,要應付各式的Workload,首先要有這些行為的資料,所以這裡也收集了各式應用並建立相關的資料庫,讓效能調校時有完整的測試資料可用。
CycProfiler套件的特色包括:具有完整的3D應用資料庫,可提供不同面向的剖析;可用於各個層級的開發環境,從硬體平台到軟體系統,提供完整的圖形子系統的效能剖析。在應用軟體開發階段,可剖析使用平台之圖形運算與輸出能力,並提供軟體開發過程的使用圖形的效率分析,揭示效能瓶頸處。若是SoC平台整合階段,則能剖析圖形子系統的運算能力、輸出能力以及頻寬使用,提供效能調教準則;此外,CycProfiler套件用途十分廣泛,從GPU IP選擇到SoC平台調校,甚至應用軟體調校皆皆可使用。
因為系統晶片影響效能最大的因素往往在於資料的傳輸,特別是複雜的應用環境會產生晶片內部複雜的動態行為,對此資策會Deltapex團隊針對資料匯流排相關的效能指標建立相關的監控規則,如連接埠傳輸(Bus-transaction)、利用效率(Utilization)、延遲(Latency)、競爭(Contention)和頻寬(Bandwidth)等。這些指標經過監控元件的訊號分析可以記錄在內部緩衝區中,再經由軟體分析這些行為,反饋給系統設計者調整系統架構與相關組態,藉由此套件的分析反覆調整,最佳化系統晶片的設計。
(本文作者任職於資訊工業策進會)