消費者對具備互動式介面的科技設備需求越來越高。從手機、汽車、家用網路到工作場所的機器,越來越多設備都須整合直覺、簡單易用的使用者介面(UI)。此外,消費者也期望設備能以更簡潔的方式執行複雜任務。
在上述發展要求下,設計師面臨如何創建能細緻執行直覺式使用者介面的壓力。觸控介面技術的擴散,促使手機、平板電腦、顯示器和銷售端點(POS)、ATM與資訊服務站等,迅速成為由人機介面(HMI)推動的創新產品。更新的語音識別未來也將成為各項工作和個人設備的標準配備。雖然嵌入式應用產品採用語音識別仍處在早期階段,然而使用者介面終將廣泛採用語音識別功能,如汽車產業正計畫推出更複雜的模型,改良嵌入式語音識別的效能。
嵌入式產品採用語音識別的發展較慢部分原因是,更直覺的使用者介面需要更強大的處理能力及記憶體功能,而這將需要更創新的快閃記憶體技術。愈直覺的使用者介面,需要愈複雜的技術平台和設計,且人機介面技術需要更密集的演算及先進的記憶體,以達成高性能的處理能力,同時保持最佳的用戶體驗。
解決方案之一是建構專用協同處理器,該處理器內建下一代記憶體,且結合邏輯和靈活的軟體演算法。協同處理器可做為分立的硬體加速器,同時降低主應用處理器負荷,讓產品得以實現豐富的用戶體驗。
語音辨識為新崛起人機介面
人機介面從電腦滑鼠問世以來已走過一段很長的時間。在科技史上,使用者介面的創新促成設備成功發展卓有貢獻,如從舊手機的輸入按鈕到智慧手機觸控式螢幕。工程師要發明引人入勝的使用者介面深具挑戰,不僅需要複雜的系統創建功能性強、可親性高、合乎邏輯和令人愉悅的用戶體驗,這些複雜的系統也需要可靠、高性能的硬體,進一步滿足處理和記憶體頻寬的需求。
隨著終端產品核心功能的創新愈趨成熟,越來越多消費者正轉向依據產品的工藝設計和使用者介面進行採購決定,迫使注意到此趨勢的廠商、快閃記憶體製造商和設計師須迅速創新以反應市場,而語音辨識正是下一波人機介面的重點。
隨著技術的發展,消費者期望日常使用的設備能具有簡單、無縫的互動功能。先進的人機介面已是許多消費性電子產品的標準配備,高效能處理能力已成為嵌入式系統的關鍵性能。當科技不斷進展,原始設備製造商(OEM)和設備製造商將須優先考慮將其所需的下一代人機介面納入新嵌入式系統(Embedded System)設計。
語音辨識處理可分為三步驟
一般而言,語音辨識可細分為三個步驟(圖1)。第一階段是聲音處理,系統將傳入的語音訊號從類比轉換成數位,並進行篩選和雜訊抑制,目的是產出獨特的數位聲音流又稱為特徵向量,通常耗費少於5%的處理器負載。第二階段為系統從聲音資料庫或稱語音模型來比對聲音,此匹配過程稱為語音評效,須耗費50~70%的系統處理頻寬。由此產生的聲音評效進入第三階段,經由搜尋語言和字典模型系統將聲音轉換為文字,此語音搜尋階段會消耗30~50%的處理負載。
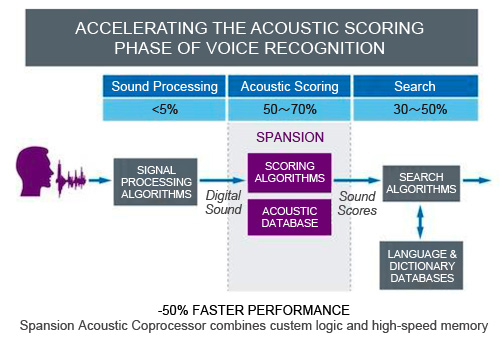 |
| 圖1 語音辨識處理三步驟 |
語音協同處理器減輕CPU負擔
傳統上,語音辨識處理過程是由同時肩負其他任務的中央處理器(CPU)負責。
由於人機介面如語音辨識受記憶體和頻寬演算的限制,使用傳統共用資源的中央處理器將損及終端用戶的體驗品質,例如在語音辨識階段,共用資源的嵌入式系統讓設計者不得不在速度和準確性之間做權衡。較大的語音模型可獲得更好的準確性,但需要更多的處理能力,以避免令人無法接受的回應延遲。
隨著使用者開始期待功能更強大的語音處理介面,如支援區分性別、雜訊、方言、口音和多種語言等,這些多元功能的語音模型需求將大幅成長,而可靠且快速存取的記憶體將是提高性能的關鍵。但現今受資源分享與約束的硬體平台無法提供目前最大語音模型可接受的處理能力。業界不得不發展精簡的語音模型,在尚可接受的回應時間內,提供較低水準的語音準確性。
為克服這一點,業者發展一套簡潔的解決方案,即藉由專用的硬體協同處理器提升處理能力,加快某些階段的語音辨識過程。語音協同處理器管理語音評效階段(第二階段)的語音辨識功能,可降低中央處理器的負擔和延遲最高達50%。
雖然嵌入式語音辨識系統引領目前人機介面的風潮,在納入自然語言理解、圖像識別或情緒感應功能方面,目前仍處於真正先進人機介面的初始階段。然而,快閃記憶體的高度發展已使業界的創新能量達到高點。
專用的協同處理器硬體,配備先進的快閃記憶體技術和邏輯,可使工程師設計更接近未來尖端的人機介面。
(本文作者任職於Spansion)