語音控制市場正經歷可觀的成長:在2020年為107億美元,預計到2026年將達270億美元以上。這項技術的優點顯而易見:免持操作和大幅簡化的介面。使用者不用瀏覽選單,只要直接說出需要的內容即可。
但正如人們都有過的經驗,聲音可能有其本質上的不利因素。當使用者在一個安靜的空間裡,直接並靠近麥克風說話時,這項技術會呈現良好的運作效果。但如果使用者在一個吵雜的超市中,透過無線耳機對手機說話呢?效果就不盡如人意了。AI指令辨識能力很重要,但清晰的語音訊號更是辨識功能得以順利運作的重要開端。如果沒有清晰的音訊輸入,使用者的辨識器往往就會誤判指令。這會讓使用者感到困擾,因而很快就不再使用這項功能。
音訊前端處理技術突顯主要聲源
視覺辨識技術也面臨類似的問題,但是只要在條件尚可的光線下,一般影像不會有太多的模糊地帶。然而,聲音偵測卻必須應對更多的干擾。持續的背景噪音:風扇、空調、道路噪音。以及其他較難預測的背景噪音:音樂、對話、狗吠、汽車喇叭、警車鳴笛。要從這串混雜的聲音中提取語音實屬不易。但是,只要使用正確的技術,就有可能達成。
這種過濾技術提供的優點不僅限於語音控制。它也能提升電話通話或電話會議的清晰度。另一端的接聽者能在背景噪音中更清楚聽見使用者和其他發言者的聲音。
要實現這個目標,需要依靠音訊前端處理(AFE),這是在辨識或通訊前的訊號處理階段組。這種AFE可清理原始音訊訊號,強調最顯著的發言者聲音,使其超越其他類型的輸入,同時減少訊號周圍的音訊雜波。
聲音活動和到達方向偵測
許多擁有語音辨識功能的裝置都透過電池供電,諸如電話、手表和遙控器,因此必須盡可能降低耗電。語音活動偵測(VAD)屬於非常低的功率級,專門用於偵測發言者。在觸發此偵測前,其他一切功能都可保持斷電狀態。那麼,人類的聲音與狗吠或其他非人類噪音有何不同?要區別這些聲音,需採用一些巧妙且具決定性的過濾方式。首先要進行到達方向(DOA)偵測,裝置(電話、遙控器等)必須配備超過一個麥克風,通常會是數個麥克風。然後,透過每個麥克風上的聲脈波到達時間的些微差異,來推論到達方向(在套用人聲過濾後)。若要讓音訊前端處理得以在聽覺上放大發言者聲音,DOA檢測是非常重要的一環,針對這點,本文將在接下來的段落中說明。
運用DOA檢測降低噪音
有多種方法可以降低噪音,部分為空間敏感式,部分則以單聲道過濾為基礎。空間法能透過波束成形技術放大發言者聲音。這與無線技術優先選擇某個行動通訊基地台而不是其他基地台的機制相同,但此處的機制用於聲波而不是無線電波。在這裡,訊號處理會使用來自多個麥克風的聲音輸入,並對來自特定方向的聲音優先進行最佳化。上述程序必然由DOA偵測引導。
單聲道過濾則更趨近於頻域中的傳統過濾方式。最簡單的方式可能是帶通濾波器,但也有更複雜的選項。這個方法的問題在於:它往往會造成字詞偵測和自動語音辨識的觸發能力打折扣。出於這個原因,部分雲端平台會在使用者使用其語音辨識服務之前,要求停用此類濾波器。不過,在語音辨識之外,單聲道濾波器在語音通訊上仍具有其價值,能為通話接聽者降低噪音干擾。
AEC技術助力環境回音消除
在任何封閉空間(房間、車廂)中,聲音會以多種方向傳遞,然後從牆壁、窗戶和家具產生回聲,而回聲會比直接訊號稍晚到達麥克風。另一種情況則是,揚聲器到麥克風之間可能產生循環,進而讓接聽者聽到刺耳的音訊回授。回音消除(AEC)的目的便是消除這些小至噪音,大至回授的惱人聲音。AEC技術會將參考訊號(意即麥克風接收到第一個來自直接路徑的最強訊號)與稍後接收到的回音進行比較(圖1)。這些回音的形式相似但強度減弱,因此能輕易區分並從訊號中去除。
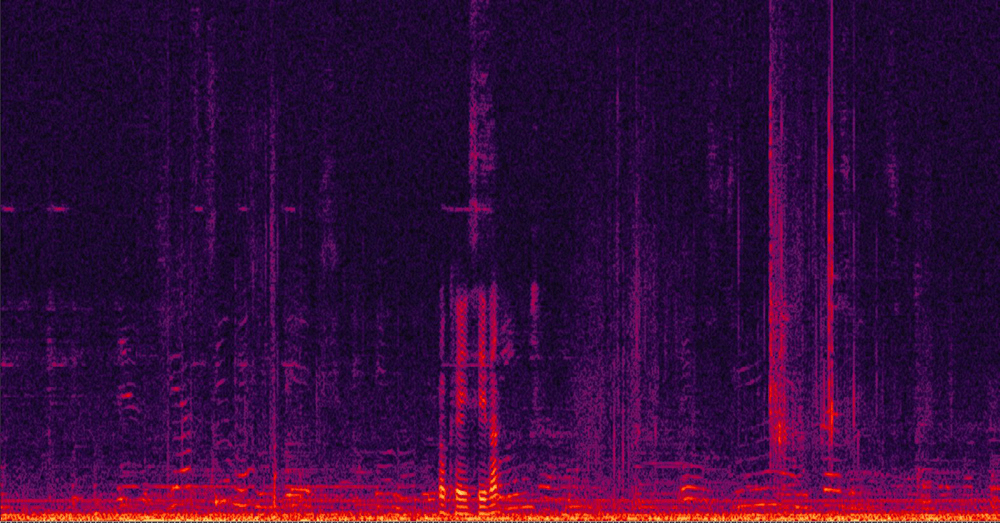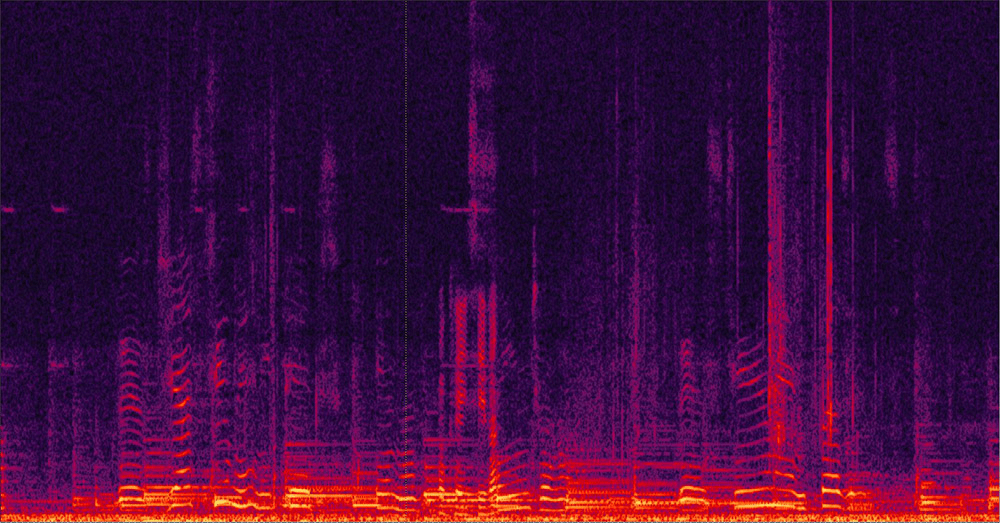 圖1 回音消除範例:AEC啟動前後的2個訊號光譜
圖1 回音消除範例:AEC啟動前後的2個訊號光譜
唯有高品質的音訊前端處理,才能實現高精確度語音辨識。這需要一些非常複雜的音訊前端處理技術,從人類聲音活動偵測,到DOA偵測、波束成形、回音消除和適當的過濾。上述所有技術都以精密的訊號處理演算法為基礎。視使用者對高階技術與大眾市場訂價之間的平衡偏好而定,可能有多種組合變化。
從背景噪音中接收清晰聲音訊號的方法,是對可靠的語音控制功能的基本要求,即使是在吵雜的環境中,仍能透過裝置進行高品質通訊。如果能在問題上投入大量技術,那麼超清晰收音的問題很好解決。只要運用高階聲音活動偵測、多麥克風波束成形及回音消除技術,就能為高階市場提供頂級產品。但是,一個更有意思的挑戰是:業者是否能針對中階市場,以更吸引人的價格,提供近乎高品質的收音效果?以下會進一步說明這兩個不同市場的技術。
語音活動偵測
這個步驟是收音程序的起點:在充滿聲音的背景中,某個人是否正在說話?第一個步驟就是查看訊號,從背景中分離出具有清晰活動的音框(圖2)。
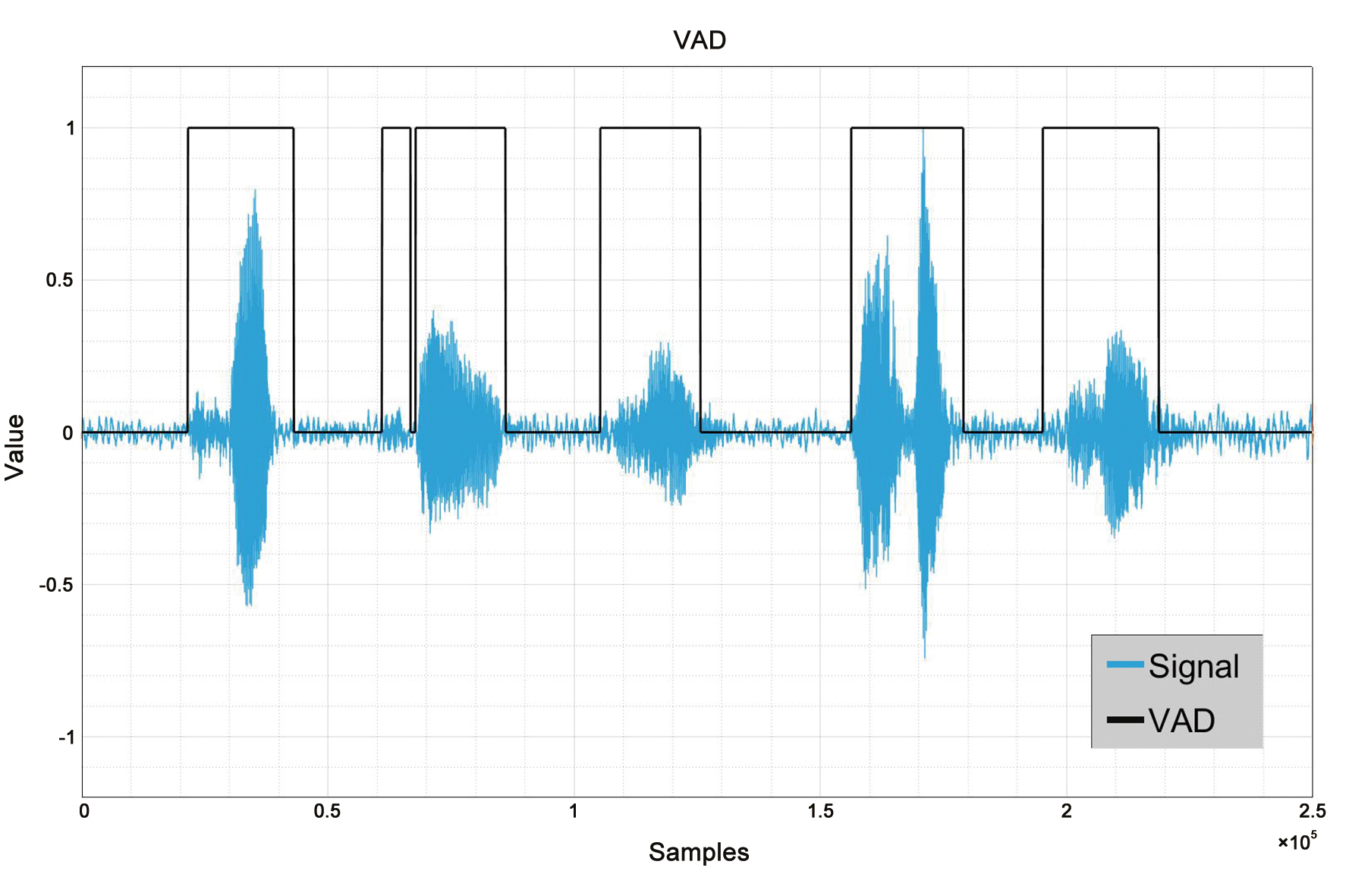 圖2 範例訊號上的VAD功能
圖2 範例訊號上的VAD功能
只查看原始偵測器訊號,部分偵測為真,部分則為誤判。為訊噪比(SNR)設定一個適當的臨界值,有助於進行妥善的取捨。在低價產品中,單純的能源式偵測(在窗框內整合)可能足矣。頂級產品則可能會使用類神經網路來增加適應性偵測。這兩種設定檔在穿戴式裝置和耳塞式耳機中都很常見。這些技術常見的比較分析方式,是在接收者操作特徵(RoC)曲線上繪製真陽性與偽陽性。這種偽陽性和真陽性偵測間的取捨,能協助使用者決定調整產品的方式(圖3)。
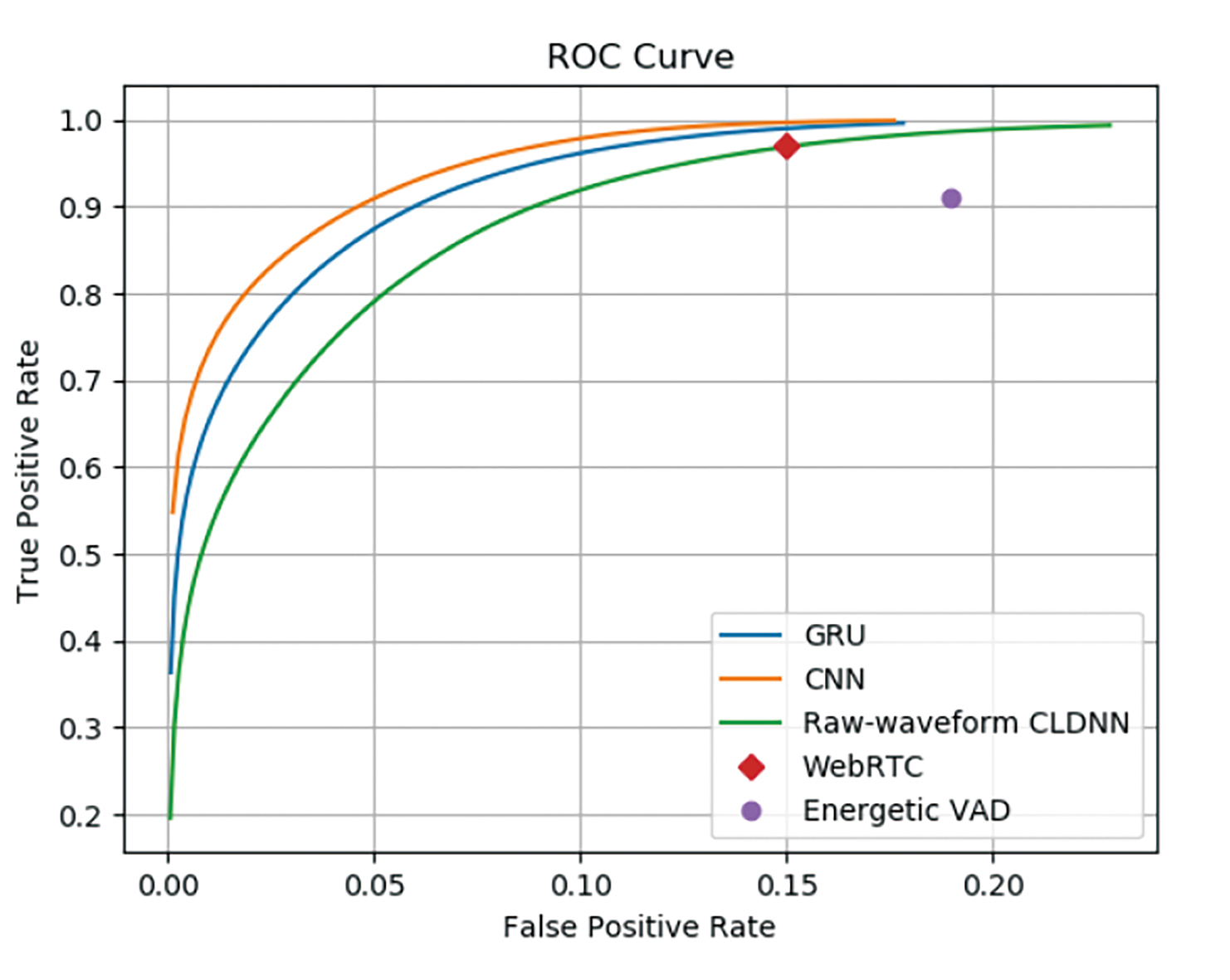 圖3 多種VAD解決方案的RoC圖表
圖3 多種VAD解決方案的RoC圖表
到達方向偵測
這種演算法會針對在不同麥克風偵測到的訊號,比較到達時間的些微延遲。每個麥克風的自然收音應該都能針對人聲設定檔進行選擇。然後,偵測的準確度將取決於使用的麥克風數量和這些麥克風的分布方式。
對於智慧型揚聲器或智慧型電視等高階裝置來說,通常可以假設發言者對裝置的距離較遠,因此DOA會相當準確。但中階市場產品通常會更接近發言者,而且幾乎肯定會使用較少的麥克風,因此必須做出相應的調整。波束成形技術應該特別考慮這項因素,這對於下一節談到的「降低噪音」相當重要。
自DOA使用波束成形降低噪音
空間式可謂具有最佳降噪效果的方法,這種方式是運用波束成形技術來放大發言者的聲音。這同樣需要多個麥克風,並將DOA作為起點來選擇要放大的聲音區域。使用者可以使用的麥克風越多,就越能準確放大發言者的聲音,並有效抑制所有其他噪音來源。即使只使用兩個麥克風,也可以建立比一個麥克風更高的區別能力(圖4)。
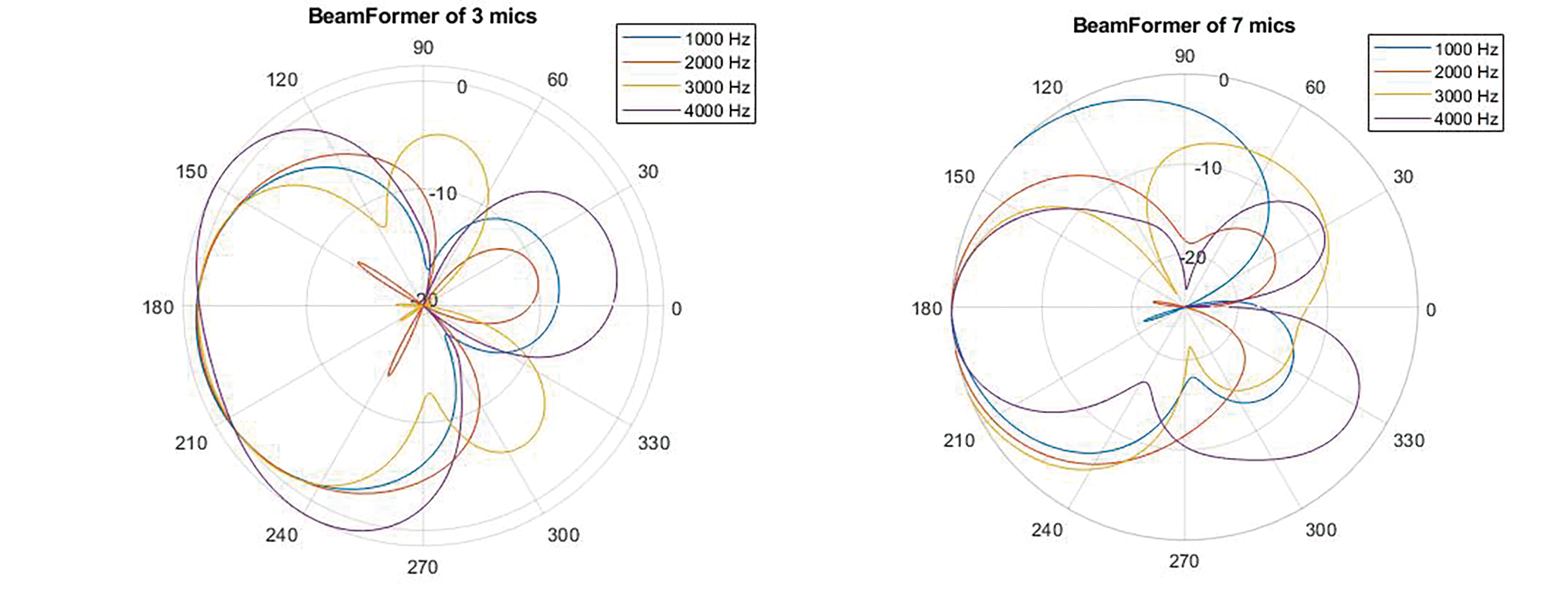 圖4 使用3個麥克風和7個麥克風的波束成形濾波器圖形
圖4 使用3個麥克風和7個麥克風的波束成形濾波器圖形
單一麥克風無法做到波束成形。但如果發言者能自然地靠近麥克風,這可能就不成問題。例如,那些使用骨傳導(Bone Conduction)技術的耳塞式耳機,其收音的無噪音程度可能已經夠高。另外要記得,針對語音辨識,雲端供應商建議不要使用濾波器來消除噪音,因為這也會降低辨識的準確度。
AEC演算法調和環境以消除回音
回音主要來自房間周遭的固定表面,會產生與發言者訊號相關的背景噪音尾音(圖5)。在低階裝置上,裝置的擴音器和塑膠收音頭往往會增加噪音,甚至會增加非線性效應。這表示AEC演算法必須能調和環境回音,同時能處理任何可能來自裝置外殼的噪音(圖6)。 如上文所見,想要獲得準確的收音時,單一規格無法滿足所有需求。解決方案必須經過精心打造,以符合不同市場的需求,達成高階與大眾市場各自的目標。業者如CEVA可協助使用者同時滿足這兩個目標:採用NN輔助演算法與可放大音訊的多支麥克風,實現高階產品,獲取最大價值;或採用能源式VAD並僅配備兩個甚至單一麥克風的低價產品。
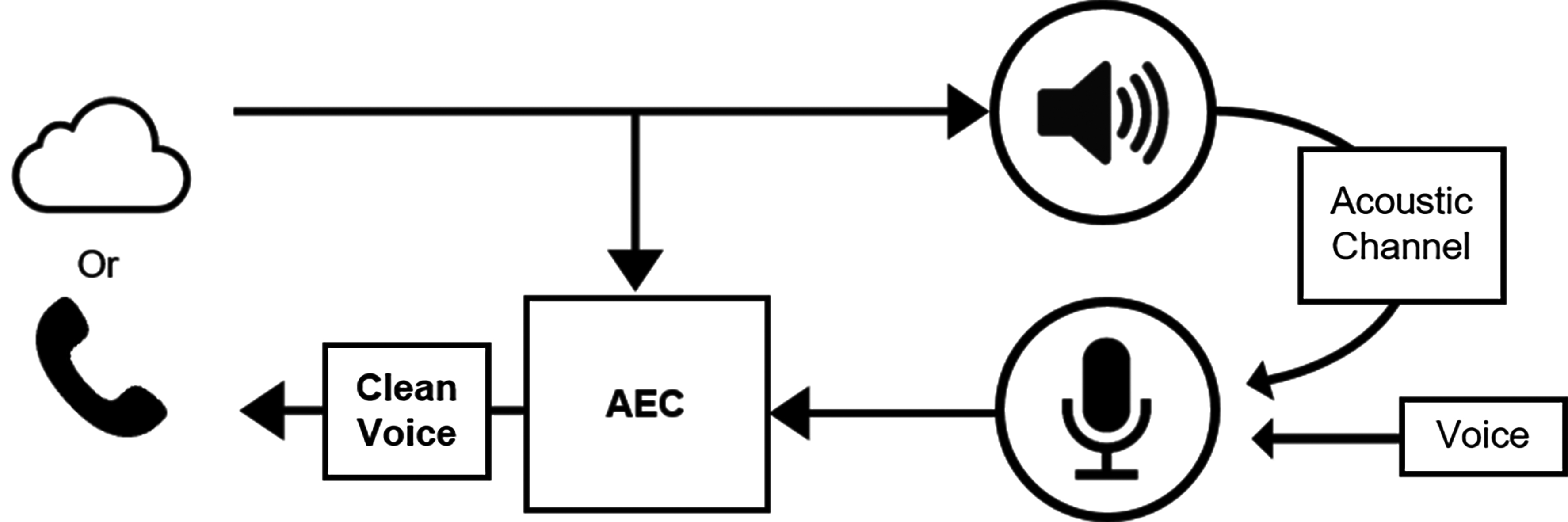 圖5 AEC使用的標準程序
圖5 AEC使用的標準程序
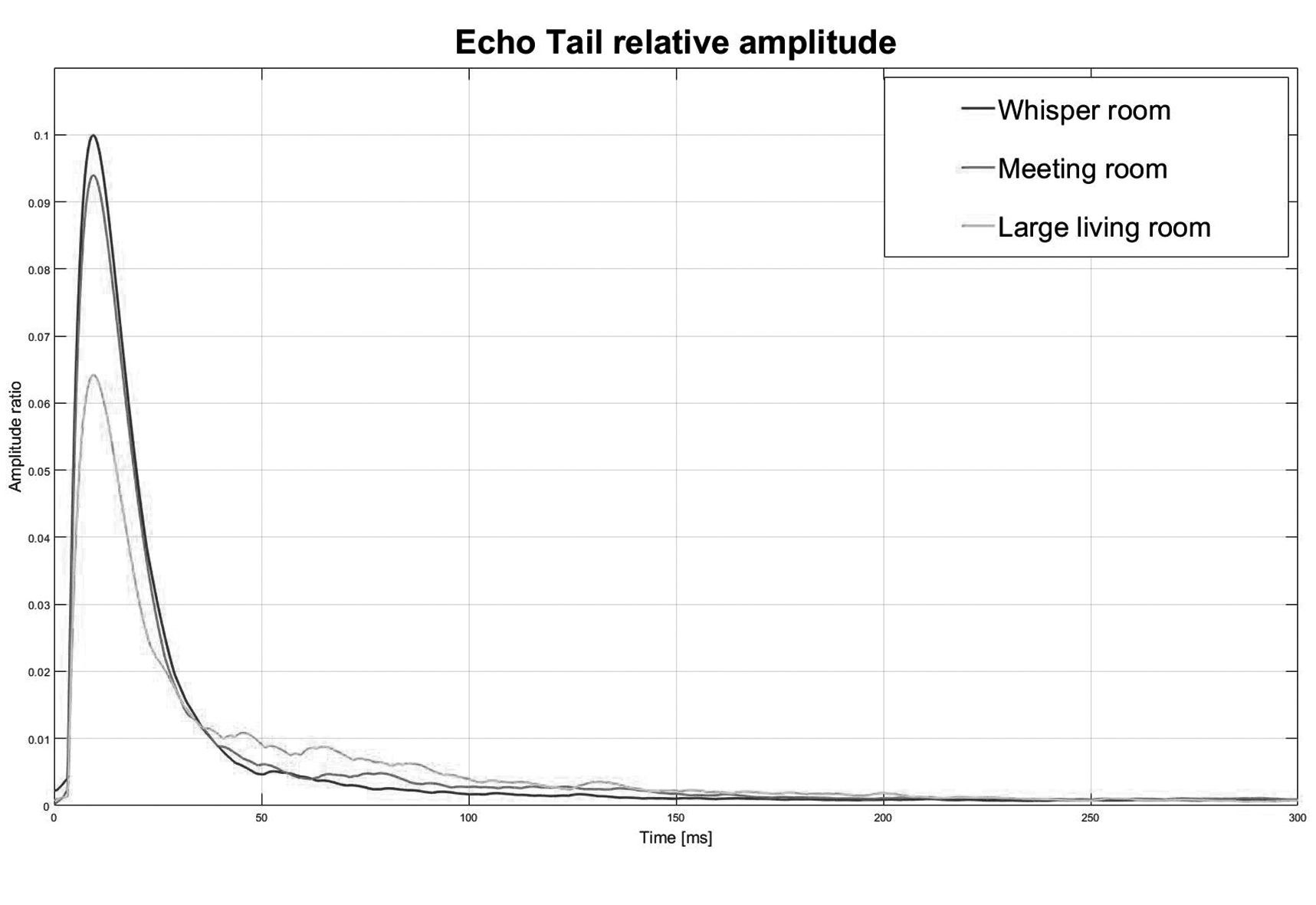 圖6 在3個不同房間中,隨時間變化的回音尾端振幅比。
圖6 在3個不同房間中,隨時間變化的回音尾端振幅比。
(本文作者為CEVA聲音技術部門聲音增強算法工程師)