聖經以賽亞書50章4節:「……主每早晨提醒,提醒我的耳朵,使我能『聽』……。」對一般人來說,上帝賦予人類聽得見的能力,是與生俱來再自然不過的基本能力,很少人為此白白得來的恩典獻上感恩;因為對聽障者而言,「想要聽得清楚」似乎是一種遙不可及的奢侈,特別在多人交談的吵雜環境中,雞尾酒效應(Cocktail Party Effect)[1]成了聽障者最大的挑戰。
洞見未來科技RelaJet Tech(以下簡稱RelaJet)創辦人陳柏儒(Blue Chen)患有先天性雙耳重度聽障,深知聽障者的心聲,與哥哥一起創辦RelaJet,試圖改善傳統助聽器因價格昂貴以及人多吵雜環境聽力品質差的問題。
助聽器現有技術:對特定的頻率成分進行降噪
現實生活中,大部分的聲音對使用者是無意義的。例如車輛在街上所發出的噪音以及陌生人的交談聲,一般來說其中並沒有與使用者相關或使用者會感興趣的資訊。換言之,大部分的聲音都不是所謂需要使用者關注的聲音訊息。
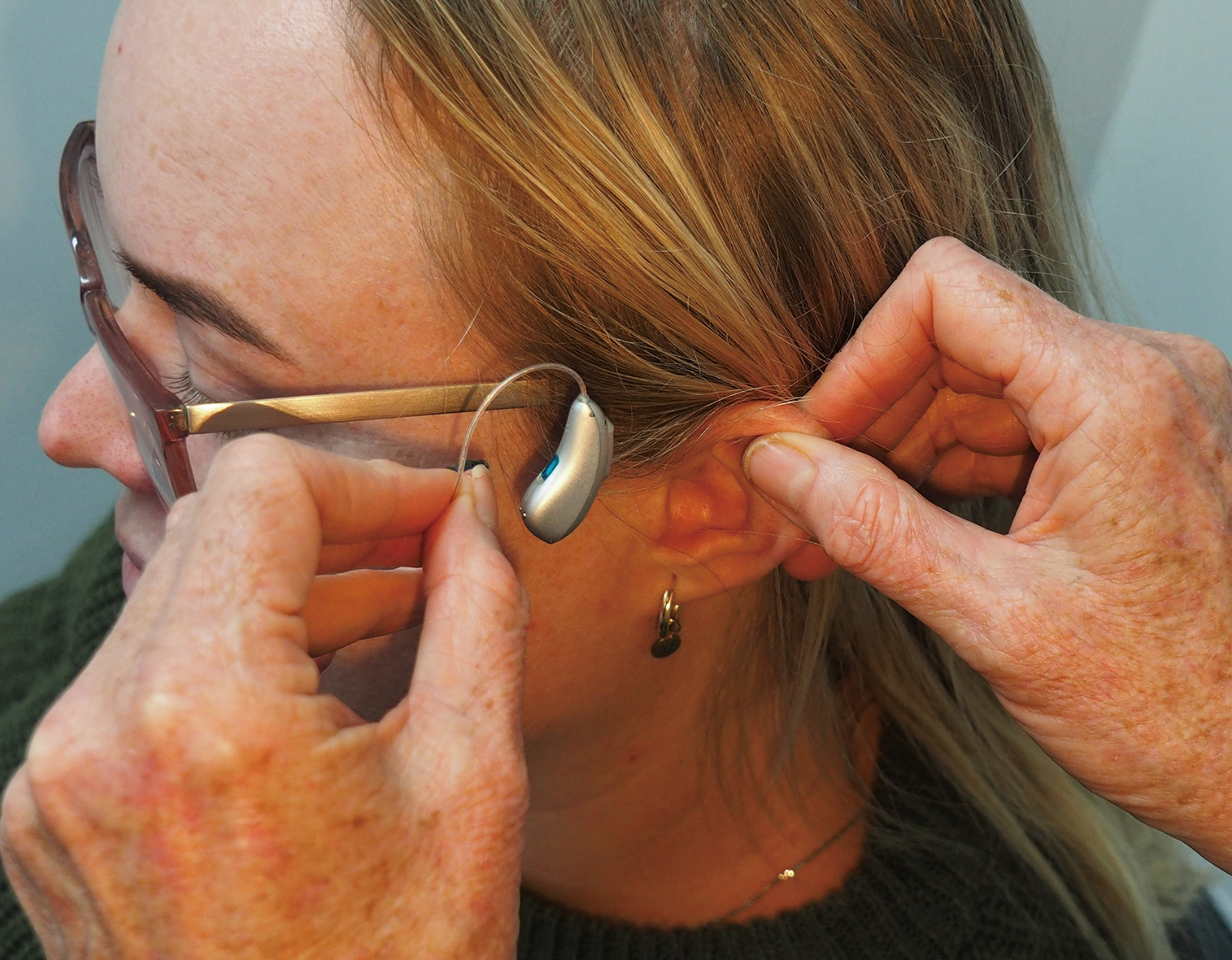 全球聽力受損須配戴助聽器的人口數高達5億,聆聽體驗優化技術的市場潛力相當可觀。
全球聽力受損須配戴助聽器的人口數高達5億,聆聽體驗優化技術的市場潛力相當可觀。
圖片來源:Mark Paton on Unsplash
現有技術中的個人聽力裝置對從外界環境所接收到的聲音,並無判斷其中是否可能含有使用者需要關注的聲音訊息。縱使外界環境聲音的來源並非單一,現有技術的做法僅將所有從外界接收到的聲音(即實際上是將來自不同來源而被混合過的聲音)視為一整體來進行處理或優化,例如美國專利公開號US20180115840和US20140023219涉及將所接收到的混合聲音中特定的頻段或頻率成分全部過濾掉。
然而,這種做法不是針對與使用者需要關注的個別聲音訊息進行處理,因此雖然可以針對整體的頻率成分進行過濾,但也會讓使用者所需要聽到的聲音訊息失真,例如若要將陌生人交談聲以人聲分布的頻段加以過濾,則連熟人朋友說話的聲音也會受到影響的狀況。特別是對於聽力有障礙的使用者而言,這種狀況會造成生活上的困擾。
「人聲分離引擎」核心技術:低延時、通話降噪
為協助聽障者擁有更好的聆聽體驗,Relajet以「多人聲分離」作為研發重點,採用「人聲分離引擎」的核心技術,企圖讓聽障者可以專注聆聽特定對象談話。Relajet透過神經網路引擎(Neural Network Engine),聲音的輸入及輸出都是透過脈波編碼調變(Pulse-code Modulation, PCM),將人聲從吵雜環境中抽離並分割,細分不同對象的聲音紋路,並靠助聽器屏蔽過濾背景噪音,經由深度學習的方法,在人多吵雜情境中也能在10毫秒(ms)[2]內完成「多人聲分離」而分離出一個最主要的人聲,藉此找出聆聽對象的聲音特徵值,讓聽障者能專注地接收特定聲音並與其溝通,有別於傳統助聽器,各種聲音混雜、無法給予使用者有意義的資訊。
自動偵測與使用者相關或感興趣的聲音訊息
為訴求可以自動偵測與使用者較相關或使用者會感興趣的聲音訊息,RelaJet於2019年申請一種基於該訴求之個人聽力裝置的專利[3],並根據使用者的需求進行適當的處理後,再播放給使用者聆聽。其判斷從外界環境所接收到的聲音是否含有與使用者相關資訊的做法,是以音訊來源進行區分,而非單純以頻段進行區分,不僅能夠保留聲音訊息的完整性,也可減少聲音訊息失真的情況。
圖1顯示該專利之一實施例中助聽器100的方塊圖。助聽器100包括一音訊輸入級110、一音訊處理電路120以及一音訊輸出級130。音訊輸入級110係包括一麥克風111及一類比數位轉換器(Analog-to-Digital Converter, ADC)112。
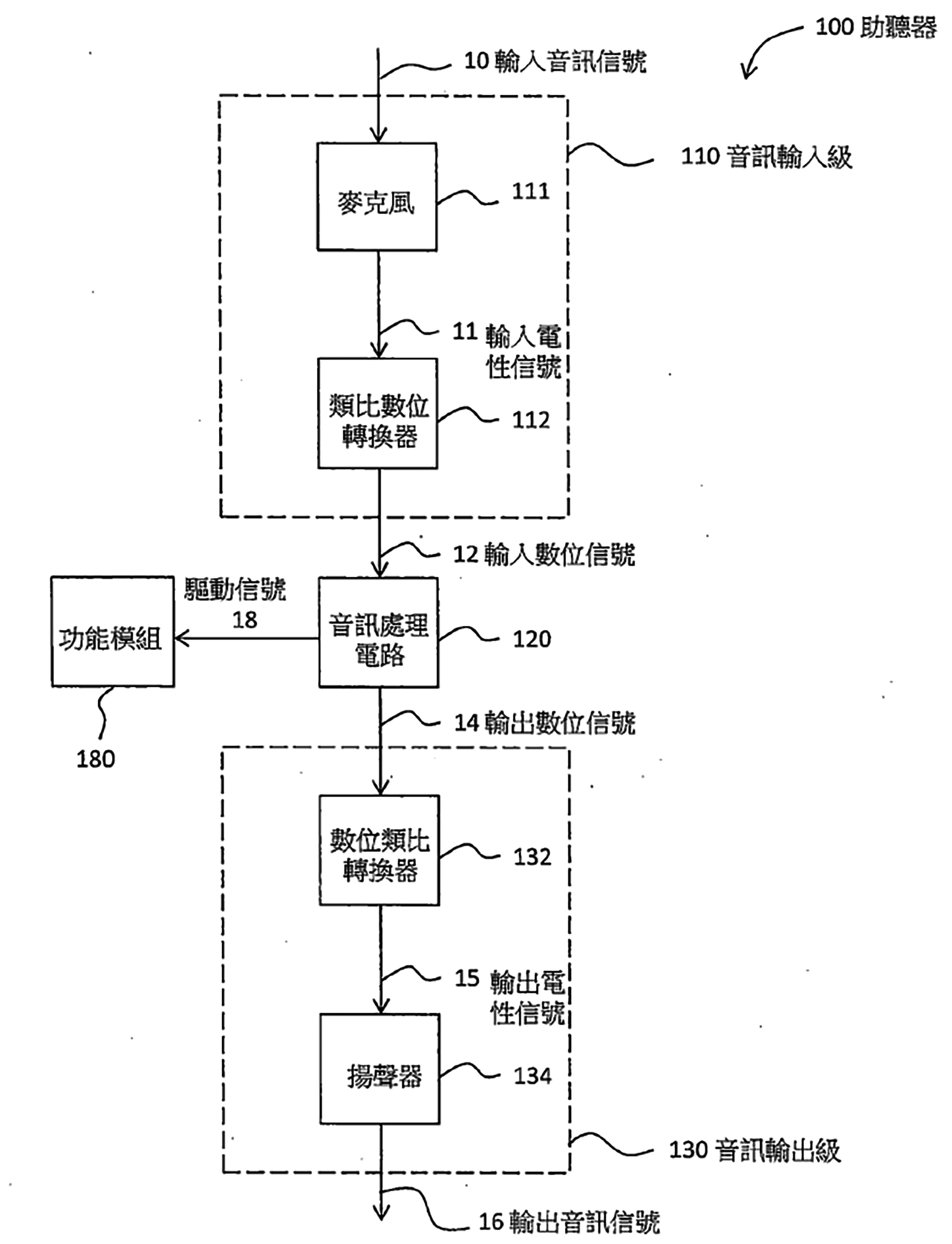 圖1 台灣專利申請號108118414之個人聽力裝置方塊圖
圖1 台灣專利申請號108118414之個人聽力裝置方塊圖
麥克風111係用以接收一輸入音訊訊號10(例如是一類比音訊訊號),並將該輸入音訊訊號10轉換為一輸入電性訊號11;類比數位轉換器112係將該輸入電性訊號11轉換為一輸入數位訊號12做為音訊處理電路120之輸入。音訊處理電路120係對該輸入數位訊號12進行音訊處理以產生一輸出數位訊號14,其中音訊處理電路120可以是一微控制器(Microcontroller)、一處理器、一數位訊號處理器(DSP)或是特殊應用積體電路(ASIC)。音訊輸出級130例如包括一數位類比轉換器132與一揚聲器134,數位類比轉換器132係用以將音訊處理電路120所產生之輸出數位訊號14轉換為輸出電性訊號15;揚聲器134則可將輸出電性訊號15轉換為輸出音訊訊號16(例如是一類比音訊訊號)並進行播放以供使用者聽取輸出音訊訊號16。
RelaJet在音訊處理的技術上分為二個階段,分別為識別階段與調整階段:
識別階段
在識別階段,為了要判斷從外界環境所接收到的聲音其中是否可能含有與使用者相關的資訊的做法,區分為採用聲紋分析與非聲紋分析兩大類。
此部分可分成「利用說話人獨有的聲紋特徵進行識別」及「根據特定詞語或聲音片段的聲紋特徵進行識別」做說明。首先是「利用說話人獨有的聲紋特徵進行識別」,由於每個人發音器官的尺寸以及肌肉使用方式的不同,使得每個人說話都有獨特可供辨識的聲紋特徵。採用聲紋特徵分析的做法,係利用說話人獨有的聲紋特徵進行識別,也就是將聲音轉換為頻譜聲紋,然後根據聲紋特徵進行識別。關於聲紋辨識的技術目前已經是成熟的技術,例如可參考美國專利US 8036891, 且聲紋辨識也有產業的標準,例如中國的《自動聲紋識別(說話人識別)技術規範》(編號SJ/T11380-2008),以及《安防聲紋確認應用算法技術要求和測試方法》(編號GA/T 1179-2014)。在進行聲紋特徵分析之前,需要對聲紋分析的演算法進行訓練。一般常用的訓練方法,可參考美國專利US5850627和US9691377。當採用對說話人獨有的聲紋特徵進行識別的做法,由於所要識別的對象因人而異,因此通常需要使用者提供樣本才能進行訓練。但對一般的助聽器使用者而言,要針對相關的說話人(例如親朋好友)累積大量樣本並不容易,因此較佳的方式是透過單樣本學習(One Shot Learning)的訓練,因為僅需要收集其親朋好友少量的說話樣本即足以進行辨識。至於「根據特定詞語或聲音片段的聲紋特徵進行識別」,另一實施例,乃是根據特定詞語或聲音片段(例如自己手機的電話鈴聲或是消防警報聲)的聲紋特徵進行識別,可參考現有技術中的語音轉文字的輸入技術(Voice to Text Input)。這種實施例的做法,在進行聲紋特徵分析之前,同樣需要對聲紋分析的演算法進行訓練,但差異在於不一定需要使用者提供樣本才能進行訓練,而可以使用通用的樣本。一般來說,說話人聲紋識別技術可先將人聲與環境噪音加以區分,之後再對人聲進行識別。但需要注意的是,若後續還需要從聲紋資料中將特定的聲音訊息進行回復、抽取或分離,以對其進行個別的調整,則宜使用適當的聲紋特徵分析演算法,例如美國專利US 5473759所揭露的短時距傅立葉轉換(Short-time Fourier Transform, STFT)。
非聲紋分析的做法,並非從聲紋或頻率成分分析找出音訊來源獨有的特徵進行識別,而是根據音訊來源所發出之聲音的方位來識別出不同的音訊來源。如圖1所示的麥克風111可具有左右聲道,因此可以根據左右聲道接收同一聲音的時間差來定位出音訊來源的方位。
調整階段
在判斷出從外界環境所接收到的聲音含有與使用者相關的資訊(或含有使用者須關注的聲音訊息)之後,音訊處理的下一個階段乃是將所辨識出的聲音訊息從整體所接收到的聲音抽取出來並加以個別調整,以符合使用者的聽力需求。
在台灣專利申請號108118414之一實施例中,乃是將所辨識出而被抽取的聲音訊息音量增大,或是將所辨識出的聲音訊息以外其他的聲音減少或濾除。若為了特殊的需求,例如要刻意忽略針對特定的聲音訊息,也可以將所辨識出的聲音訊息音量減小或濾除,或是將所辨識出的聲音訊息以外的聲音增大。除了音量,亦可針對所辨識出而被抽取之聲音訊息的頻率進行調整(即移頻),例如把說話人原本較尖銳的語調降頻為較低沈的語調,但其他的聲音保持其原有的頻率。
此外,對聲音訊息的調整亦可根據識別結果而有所不同。舉例來說,當辨識出是使用者自己手機的電話鈴聲時,則可將使用者自己手機的電話鈴聲音量放大,但當辨識出是隔壁同事桌上的電話鈴聲時,則將同事桌上電話鈴聲的音量降低或濾除。
圖2係配合圖1個人聽力裝置來說明本發明例示性實施例的流程圖。其中,步驟34係透過圖1中音訊處理電路120來判斷從外界環境所接收到的聲音中是否含使用者須關注(或要刻意忽略)的聲音訊息。判斷方法如前所述,除了可透過根據特定詞語或聲音片段(例如自己手機的電話鈴聲或是消防警報聲)的聲紋特徵來判斷是否為使用者須關注的聲音訊息外,還可透過識別出音訊來源的方式來做判斷,而此部分可透過該音訊來源獨有的聲紋特徵或是該音訊來源的方位進行識別。
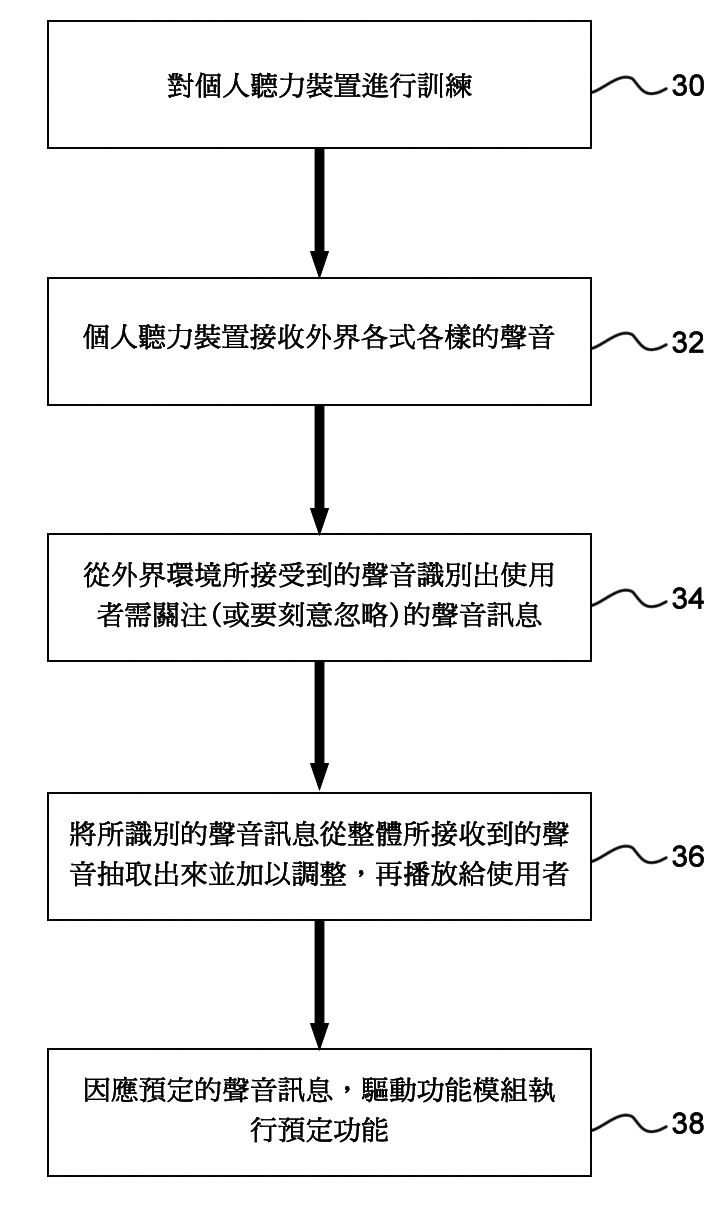 圖2 台灣專利申請號108118414之個人聽力裝置實施例流程圖
圖2 台灣專利申請號108118414之個人聽力裝置實施例流程圖
國際專利分類號(IPC)是用於專利文獻分類和檢索的國際標準,依此可略看出專利之技術分布。該專利之國際專利分類號(IPC)為H04R 25/00(涉及助聽器)和G10L 21/00(涉及為改變語音或聲音訊號品質或其可理解性處理語音訊號以產生其他可聽或非可聽的訊號)。再者,該專利主張之申請專利範圍包括三個獨立項,分別主張個人聽力裝置,與該個人聽力裝置無線連結的外部音訊處理裝置,以及儲存在一電腦可用媒體上之電腦程式產品。
以一種個人聽力裝置的權利主張而言,其包含:一麥克風,用以接收一輸入音訊訊號,其中該輸入音訊訊號係混合有一第一音訊來源所發出之聲音與一第二音訊來源所發出之聲音;一揚聲器;以及一音訊處理電路,用以自動地從該輸入音訊訊號區分出該第一音訊來源所發出之聲音。其中,該音訊處理電路更將該輸入音訊訊號進行處理,以將該第一音訊來源所發出之聲音以及該第一音訊來源所發出之聲音以外的聲音個別進行不同的調整,藉此產生一輸出音訊訊號於該揚聲器播放給使用者。
對環境中說話人的人數及人數變化進行辨識
現有技術雖然可做到說話人的辨識以及單字或語句內容的識別,並透過聲紋辨識來識別出說話人的數目,但仍有不足之處。例如Google Home聲紋辨識的做法,必須仰賴用戶先將其聲紋進行註冊,使用上並不方便。此外,目前已有金融機構以用戶的聲紋作為身分驗證工具,因此某些用戶可能會擔心聲紋資料外洩遭濫用而不願輕易提供。
其次,縱使用戶願意預先註冊其聲紋,然而當同時有不特定的多數用戶進行交談或同時說話時,也就是俗稱「雞尾酒會問題(Cocktail Party Problem)」的情況下,透過預先註冊的聲紋進行比對來判斷當下環境中說話人的數目並不容易,而在人數無法確定的情況下,要進一步將各個聲紋一一區分而加以辨識其內容,或是要分離各個說話人的聲音就更為困難。有鑑於此,Relajet體認透過對於環境中說話人的人數以及人數變化進行辨識,可以合理地推斷出環境的特性(Profile)以及環境中用戶的行為模式,提供更符合用戶需求的服務。
於是Relajet在2019年申請一種電腦執行的語音處理方法與資訊裝置的專利[4],其可採用深度學習(Deep Learning)的做法,特別是生成對抗網路(Generative Adversarial Network)模型,在不需要用戶預先提供其聲紋(即預先註冊聲紋)的情況而從所接受到的混合語音訊號中估計所在環境中不預先特定說話人的人數。再者,在估計出環境中不特定說話人的人數之後,可再依此推斷出環境的特性以及環境中用戶的行為模式,並可提供適合的服務。對此,可根據預定時程或按照特定的條件來重複地採集環境中說話人的語音樣本,以觀察其變化的趨勢。
舉例來說,如果每天都可採集到充分之說話人的語音樣本,則可推斷所在的環境可能為住家;相對地,如果只有在工作日才能採集到充分之說話人的語音樣本,則可推斷環境所在的可能為辦公室。而進一步可從所估計環境中說話人的人數與其變化趨勢,則可進一步推斷出例如家庭的組成或是辦公室的業務型態。若再搭配其他已知的資訊(例如透過GPS資料或是網路IP位址所推知的地理資訊),可對用戶所在環境的特性進行更精確的判斷,進而提供客製化的服務。
圖3係依據該專利之實施例的方法流程圖。步驟200是麥克風對環境中用戶說話或交談所發出的語音訊號持續地進行採集。在步驟202中,採樣的語音訊號其被切割成每秒數千到數萬個片段,並且再經過量化,即是把該片段聲波的振幅以數字表示。將採樣的語音訊號轉換為數字資訊後,音訊處理程式(ADP)可進一步利用轉換後的數字資訊進行說話人分離(Speaker Separation)的運算,以分離出個別說話人的語音資料,並可依此決定出個別說話人的數目。
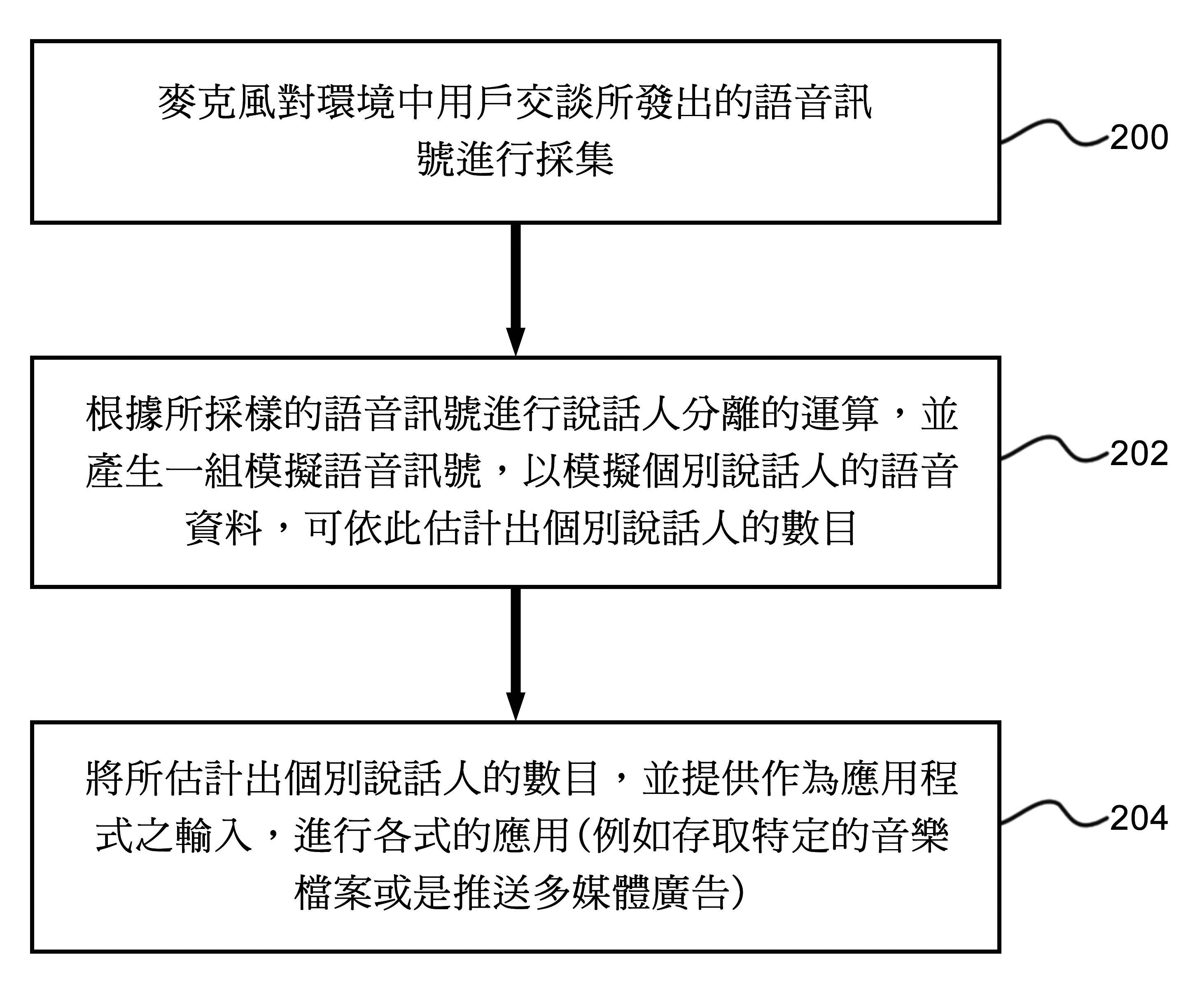 圖3 台灣專利申請號108130535的方法流程圖
圖3 台灣專利申請號108130535的方法流程圖
而步驟204,將步驟202中所估計出的說話人數作為資料輸入,而可進行各式的應用,舉例來說,資訊應用程式AP1可為類似Spotify之音樂串流服務程式,資訊應用程式AP1即可根據當下所估計的說話人數選擇播放不同的歌單(Playlist),例如當人數少的時候,自動選擇音樂類型較為平靜的歌單。根據環境類型來存取特定的多媒體資料的相關技術可參考美國專利公開號US20170060519。
該專利之國際專利分類號(IPC)為G10L 15/02(涉及語音識別之特徵提取)和G10L 15/08(涉及語音分類或檢索)。再者,該專利主張之申請專利範圍包括二個獨立項,分別主張一種電腦執行的語音處理方法,以及一種儲存在一電腦可用媒體上的電腦程式產品。
以一種電腦執行的語音處理方法的權利主張而言,係涉及一生成對抗網路,該生成對抗網路包含一個生成網路與一個判別網路,其中該方法包含:(a)透過一麥克風取得一混合語音訊號,其中該混合語音訊號至少包含複數個說話人在一時段內發出之複數個語音訊號;(b)提供該混合語音訊號給該生成網路,該生成網路以一生成模型來根據該混合語音訊號加以產出一組模擬語音訊號,以模擬該複數個語音訊號,其中該生成模型中的參數係由該生成網路與該判別網路不斷對抗學習而決定;以及(c)決定該組模擬語音訊號的訊號數目,並提供作為一資訊應用程式之輸入。
全球聽力受損人口漸增 助聽科技發展迫在眉睫
助聽器產業發展的挑戰,除了本文提及的技術受限於10毫秒的問題外,原本預期美國食品藥品監督管理局(FDA)在去年會開放非處方(Over-the-Counter, OTC)助聽器上路,不但能大幅減低實驗與認證的成本,讓助聽器更平價化,且購買管道也會更加開放,不再有那麼繁瑣的驗配流程。然而,FDA錯過了一個重要的法定截止日期,所以目前助聽器仍然是受限制的設備,為此必須進行銷售遵守適用的美國聯邦和州要求[5]。
此外,還有用戶數據難以取得的問題。就用戶數據的取得而言,基於醫療數據是高度隱私性的資訊,十分受到保護,助聽器用戶進行聽力檢查,使用一段時間後,需要把助聽器拿回醫院、聽力中心進行參數調校,這些用戶數據都是留在醫療機構,就算取得也要價非常昂貴,再加上號稱史上最嚴格個資保護法的歐盟一般資料保護規範(GDPR)法案已經上路,導致醫療數據的取得更加困難。 然而,根據世界衛生組織2018年數據顯示,全球聽力受損須配戴助聽器的人口數高達5億,到了2050年,全球恐有近10億人口因長時間暴露在高分貝環境下而聽力受損,相當於每10人中就有1人患有聽覺障礙,對學習、工作、社交各方面都將產生極大影響。Relajet創辦人除親身經歷聽障的痛苦與帶給他的不便之外,也從數據中嗅出市場無限,預見多人聲分離引擎的潛力無限,能應用之產業領域亦相當廣泛,應積極跨出聽障領域讓應用場景再延伸。例如多人聲分離引擎,除了用於幫助聽障者外,未來在夜店、工廠、大型活動現場等吵雜環境中亦有發揮空間。此外,亦可能用在協助分離多人討論音軌,結合語音轉文字(Speech to Text, STT)的技術提供自動繕寫會議記錄、客服中心、逐字稿音檔等特殊用途。甚至於周邊相關服務,包括使用者可將特定型號錄音筆之音檔丟上雲端,後台即能自動辨識不同人聲,並將其分離成相對應音軌供用戶使用等多元用途,擴大實現Relajet創業初衷,希望可以透過技術幫助到更多的人,讓使用者更加便利。

(本文作者任職於工研院技術移轉與法律中心)