從古至今,在全面生產環境中,機器操作人員的經驗是企業最寶貴的資產之一,他們能預測出何時須要進行維護,並且向工廠經理報告任何異常行為,例如機器內的叮噹聲或碰撞聲,促使維護人員展開檢查。
如今因自動化水準的提升嚴重影響操作人員察覺即將發生的故障的能力,並且大部分維護工作都是按計畫進行,而非預測性維護,如果某些情況下未被發現或被忽視,則會引起不必要的工廠停工。
然而,近來席捲全球的新冠疫情迫使更多機器採用無人看守或遠距看守的方式執行,將現場執行降至最低水準,並縮減維護團隊規模。因此,對工廠經理而言,為輕鬆預測故障而提高機器設備的自動偵測與自我診斷能力成為眼下的策略優勢。
預後與健康管理(Prognostics and Health Management, PHM)等方法與預測性維護4.0(PdM4.0)等計畫已問世數年,但工廠經理現在才將此從觀察名單轉為當務之急。目標是為自動執行和遠距看守機器設備提供人工參與式決策,進行最佳且即時的維護操作。
PHM旨在蒐集和分析資料,透過演算法偵測異常和診斷即將發生的故障,以提供設備的即時健康狀態,進而估算其剩餘使用壽命(Remaining Useful Life, RUL),其相關成效包括延長設備使用壽命,以及降低營運成本。
PdM4.0是組成工業4.0和工業物聯網(IIoT)計畫的一部分,其目的是進一步提高設備自動化水準,為設備配備更多的資料擷取感測器,使用數位訊號處理、機器學習和深度學習作為預測故障的工具並觸發維護活動。
各項標準與配套的詞彙、展示和指南已制定完成,如IEEE 1451、1232以及ISO體系的13372、13373、13374、13380、13381,皆為預測性維護奠定共同的基礎。
圖1為從計畫維護向PdM4.0轉型的演變。顯然,隨著轉型PdM4.0不斷深入,複雜性也隨之增加。
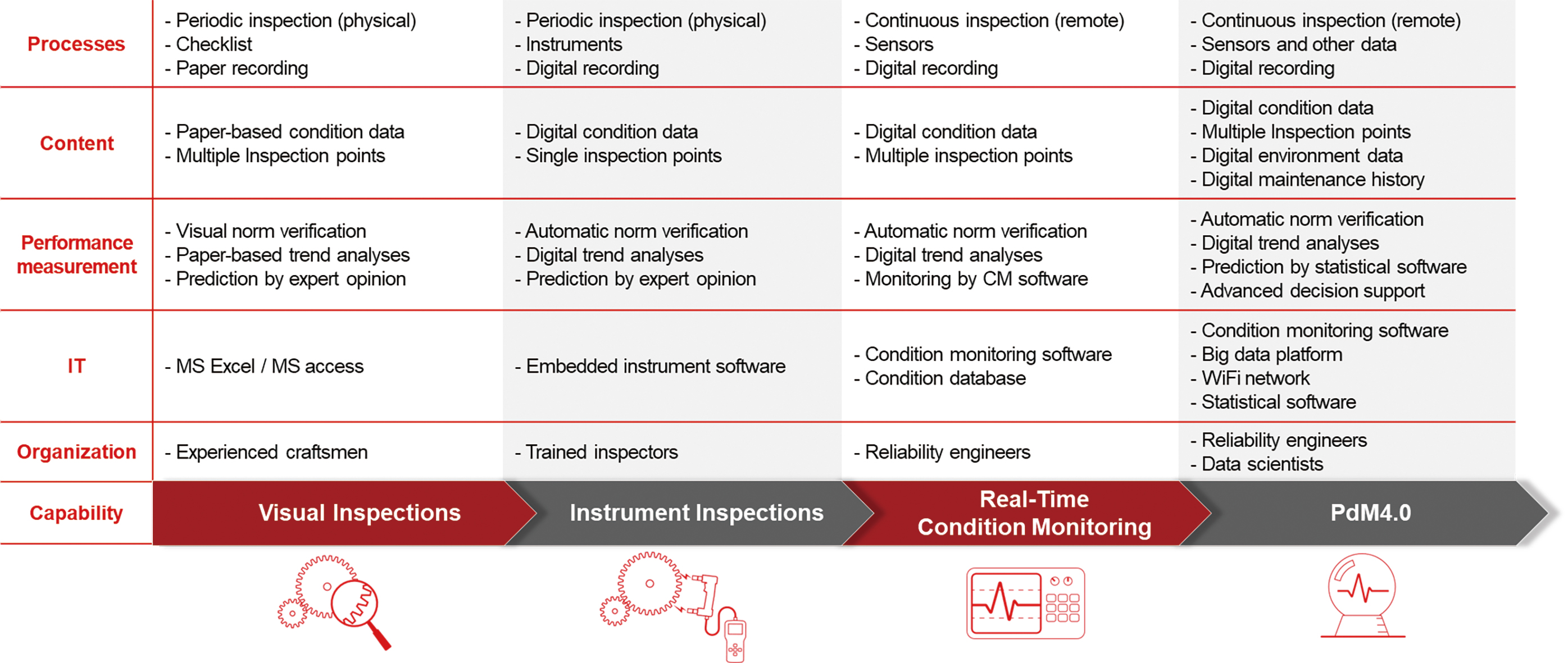 圖1 PdM4.0為最高預測性維護水準
圖1 PdM4.0為最高預測性維護水準
資料來源:資誠聯合會計師事務所(PwC)
思考三大問題 發揮PHM/PdM4.0優勢
然而,雖然PHM和PdM4.0的意圖清晰並提供一般性建議,但它們的實際實施並未完全實現,這是因為工廠經理或維護經理尚不具備所需的組合技能。要充分發揮PHM和PdM4.0的優勢,必須思考以下問題:
首先,在建立預測性維護實現的業務案例時,應重點關注能最大限度降低風險的具體問題。思考問題:「最容易出現問題的關鍵資產是什麼?」
其次,很多工廠的機器設備連結性仍然有限,因此不容易獲取資料。思考問題:「如何在不降低機器設備的可靠性、安全性與保障性的前提下,在機器設備上配備更多能夠連接到資訊技術(IT)基礎設施的感測器?」
第三,在蒐集資料、建立通訊後,下一個挑戰是如何使用它們。思考問題:「如何進行資料分組,以便偵測、預測故障並最大限度減少故障的發生?」
大多時候不會有明確答案,最原始且簡單的想法是蒐集工廠和機器設備產生的所有資料,將這些資料傳遞到雲端的本地端資料中心,並嘗試使用資料分析從中提取資訊,這也被視為批次處理資料。
圖2所示為導向雲端的資料漏斗以及有助於形成預測性維護的不同資料來源。
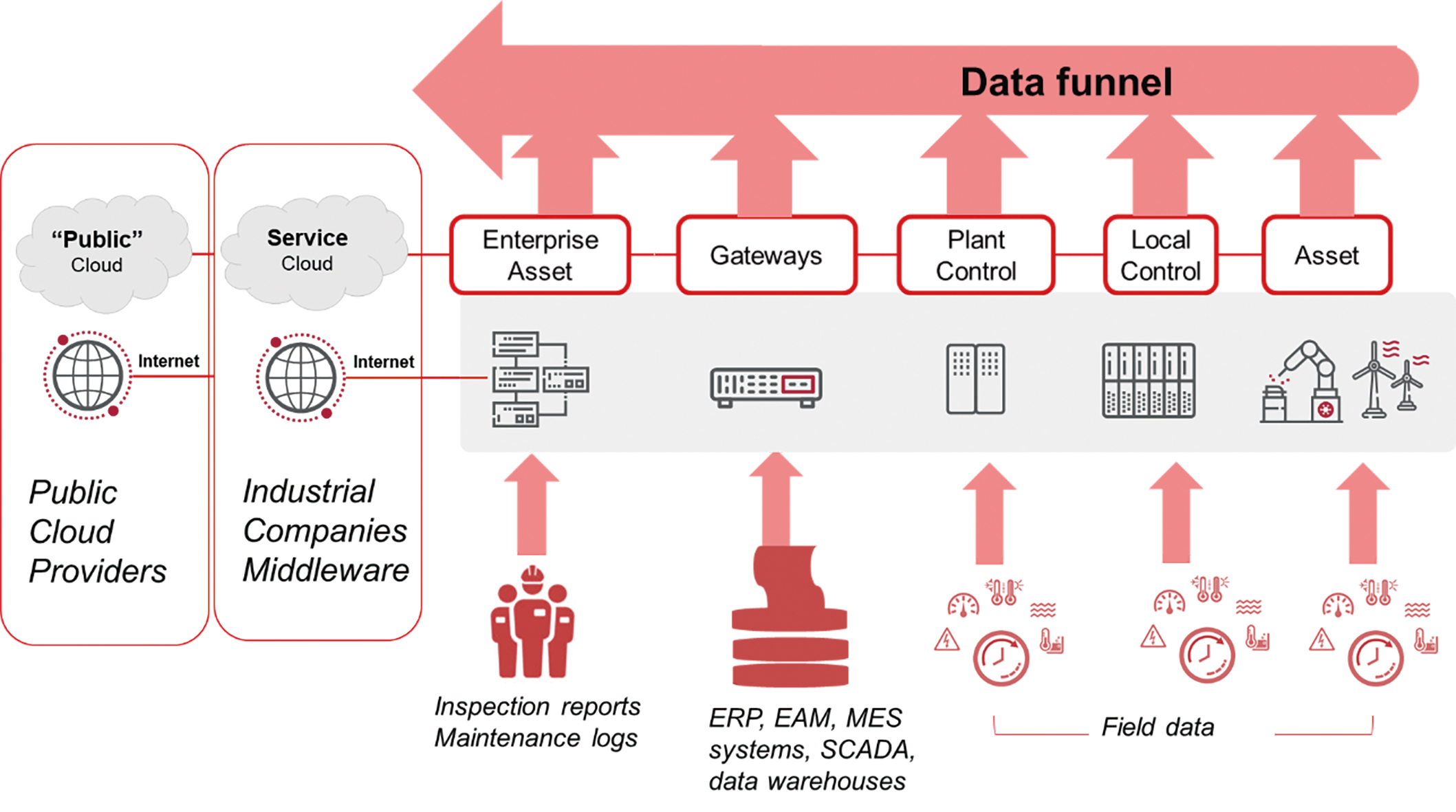 圖2 從現場到雲端的預測性維護流程資料
圖2 從現場到雲端的預測性維護流程資料
並非所有的工廠和機器設備資料都相同,也有一些非結構化資料,如檢查報告、維護日誌、原始材料和批次組織,這些資料與用於預測性維護的資料相互關聯。此外,也有來自企業風險管理(Enterprise Risk Management, ERM)、企業資產管理(Enterprise Asset Management, EAM)以及製造執行系統(Manufacturing Execution System, MES)等企業自動化技術的結構化資料,它們提供另一個資訊來源,用於檢驗機器設備狀況、工作量和使用情況,這也稱為批次處理資料。
大多數非結構化資訊來自與邊緣裝置相連的感測器,因為資料流程經常以毫秒(ms)為週期大量產生。
PdM4.0推薦的分析框架,則如圖3所示。
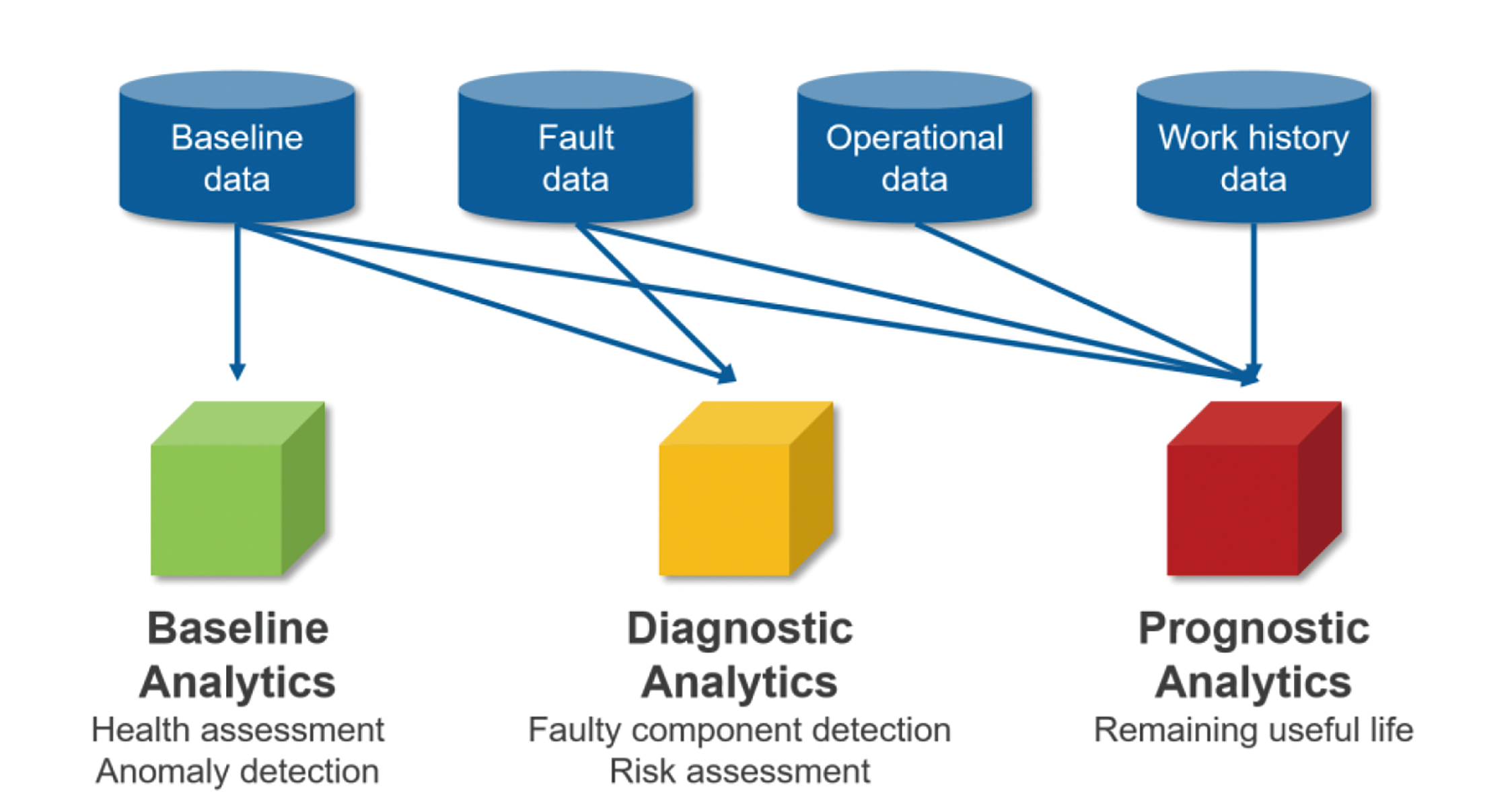 圖3 為PdM4.0提取資料的分析框架
圖3 為PdM4.0提取資料的分析框架
基線分析功能可在實際事件發生後的幾毫秒內偵測到資產的異常行為。用於執行這些分析的資料通常屬於相關資產的本地端資料,並且依賴資產正常工作時蒐集的資料。
診斷分析功能用於確認異常的根源,例如電機軸承失效,這須要具備故障狀態的相關知識。診斷結果會在幾分鐘內回報。
告知軸承剩餘使用壽命的預後分析可能需要數小時才能回報結果,並且需要存取來自多個來源的多種類型資料,才能做出預測。
兩大主要架構 實現預測性維護
結構化資料和非結構化資料、批次處理和串流處理資料、速度和容量,這些都是工業4.0計畫的宏大分析架構組成部分,而預測性維護則搭載在此類框架上。有兩種主要架構正在興起,包括Lambda架構與Kappa架構。
Lambda架構是一種用於資料處理的部署模型,將傳統的批次處理管道與高速即時的串流管道相互結合,在面對快速產生的海量資料時,可提供資料驅動和事件驅動的資料存取。圖4所示即是Lambda架構。
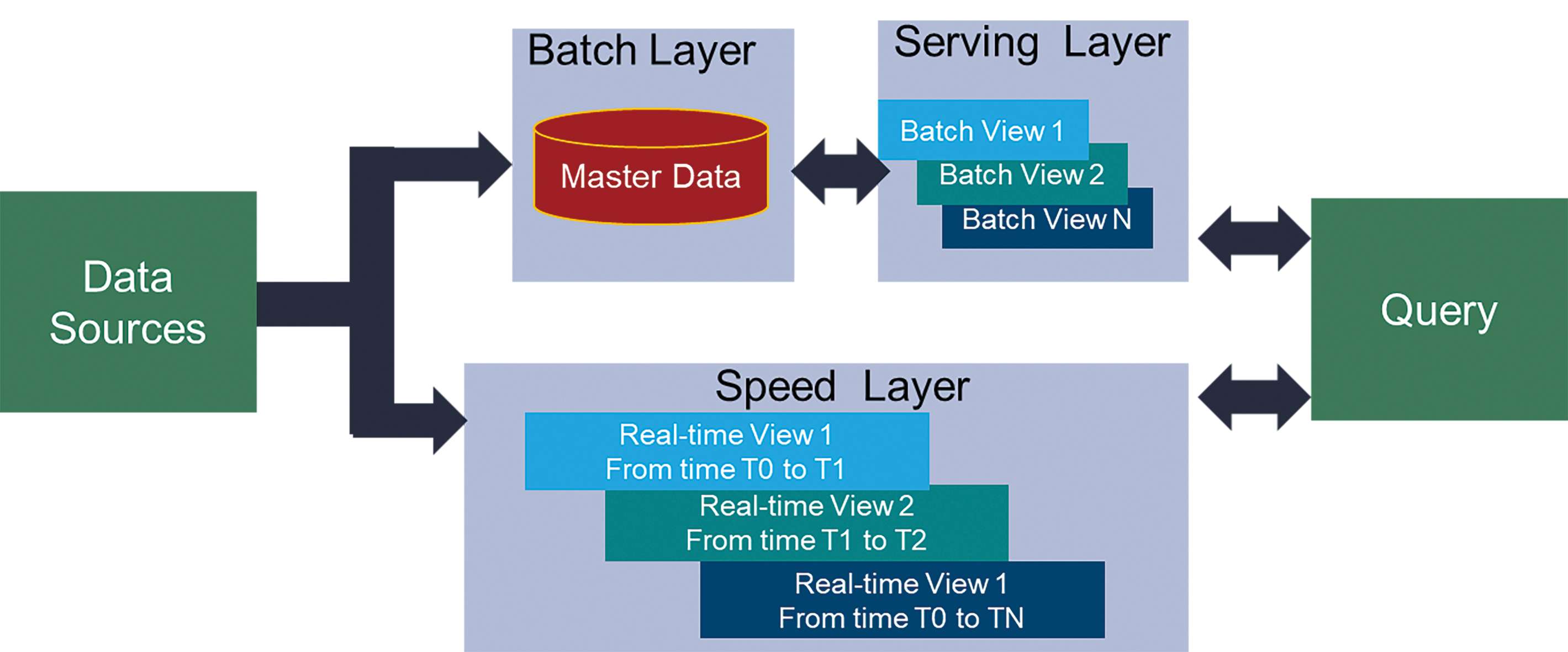 圖4 Lambda架構
圖4 Lambda架構
Apache Kafka是一種用於實現資料來源(Data Source)的框架。它是一種分散式資料儲存,針對即時、順序和增量擷取以及處理串流資料進行優化。它充當中間儲存,可以保存資料並支援Lambda架構的批次處理層和速度層。
批次處理層(Batch Layer)通常使用如Apache Hadoop技術來實現,以便能經濟高效地獲取和儲存資料。為了確保所有傳入資料具備可信歷史紀錄,這些資料為不可變且僅允許追加。
服務層(Serving Layer)會對最新的批量視覺圖進行增量索引,以允許終端使用者進行查詢。處理過程以一種極度平行化的方式完成,以最大限度縮短資料集的索引時間。
而速度層(Speed Layer)透過索引最新添加、尚未被服務層完全索引的資料來補充服務層,速度層作用通常應對最接近現場串流資料的現場閘道。它們擷取訊息、過濾資料、提供身分映射、日誌訊息並可連結到雲端或本地端閘道。如果這些閘道也能執行本地端分析和機器學習,那麼移動資料到上游就沒有優勢,而且在確認現場閘道平台的大小時,此功能須要考慮CPU和記憶體大小的影響。
查詢層(Query Layer)則是資料科學家、工廠專家和管理人員查詢所有資料(包括最近添加的資料)所需的,以提供近乎即時的分析系統。
許多機構可能同時擁有批次處理、即時以及非常嚴格的端對端延遲需求,要求可以在資料流程層中採用包括資料品質技術的複雜轉換。因此,Kappa架構是一種串流優先的架構部署模式。Apache Kafka的功能是擷取資料,並將資料傳遞到Apache Spark、Apache Flink等串流處理引擎中進行轉換,然後將豐富化後的資料發布回服務層,以達報告和儀表板功能。
找尋合適硬體 打造PdM4.0邊緣裝置
要部署Lambda或Kappa架構,屬於嵌入式系統的裝置和邊緣閘道需要足夠的運算效能和足夠的記憶體。以Apache Kafka為例進行重點講解,Apache Kafka可以部署到這樣的嵌入式系統中,為Lambda和Kappa架構提供支援。Apache Kafka可以採用不同的設定進行部署,包括裸機、虛擬機器(VM)、容器等。以最低設定執行Apache Kafka的最低硬體要求是單核心處理器和幾個100MB的隨機存取記憶體(RAM)。然而,這種小規模的實施方案不足以為Lambda和Kappa架構提供適當的服務品質。
具體而言,在Apache Kafka的系統概念中,訊息串流被劃分成名為「話題」(Topic)的特定類別。這些訊息使用名稱為「生產者」(Producer)的專用進程發布給特定話題。發布後的訊息隨後被儲存在名為「中介者」(Broker)的伺服器叢集中。從根本上說,Kafka「中介者」期望客戶端「生產者」(現場裝置)發送訊息給系統,客戶端消費者(邊緣裝置)拉出訊息,管理客戶端工具(在現場裝置和邊緣裝置內)允許創建話題、刪除話題,並設定安全設置。僅從這些對「中介者」、「生產者」、「消費者」以及「管理工具」的基本要求,就可以洞悉需求的多樣性。
對於「生產者」來說,增加互聯功能和資料獲取功能後,運算效能和記憶體占用會造成嵌入式系統的嚴重問題。因此,要讓這樣的嵌入式運算系統提供合理水準的服務品質,應具備下列特性:異構密集型I/O蒐集與處理、能夠執行數位訊號處理以過濾/提取分量頻譜並減少冗餘資訊、能夠執行VM和容器、能夠即時執行機器學習和深度學習推論、能夠支援營運資料聯網和資訊技術互聯。
可以在系統單晶片(SoC)、CPU或GPU中找到一些上述功能,但某些元件I/O能力不足,某些元件的機器學習和數位訊號處理能力有限,還有些元件不具備足夠的互聯能力。綜合所有這些技術,另一種技術類別正異軍突起。自行調適運算加速平台(ACAP)整合上述所有功能,包括導向機器學習和深度學習推論的向量處理、導向執行相關框架的純量CPU、導向即時資料蒐集和I/O密集型處理的緊密耦合可編程邏輯(PL)。這些功能結合高頻寬網路晶片(NoC),能提供存取全部三種處理元素類型的記憶體映射、存取蒐集和處理資料的記憶體(圖5)。
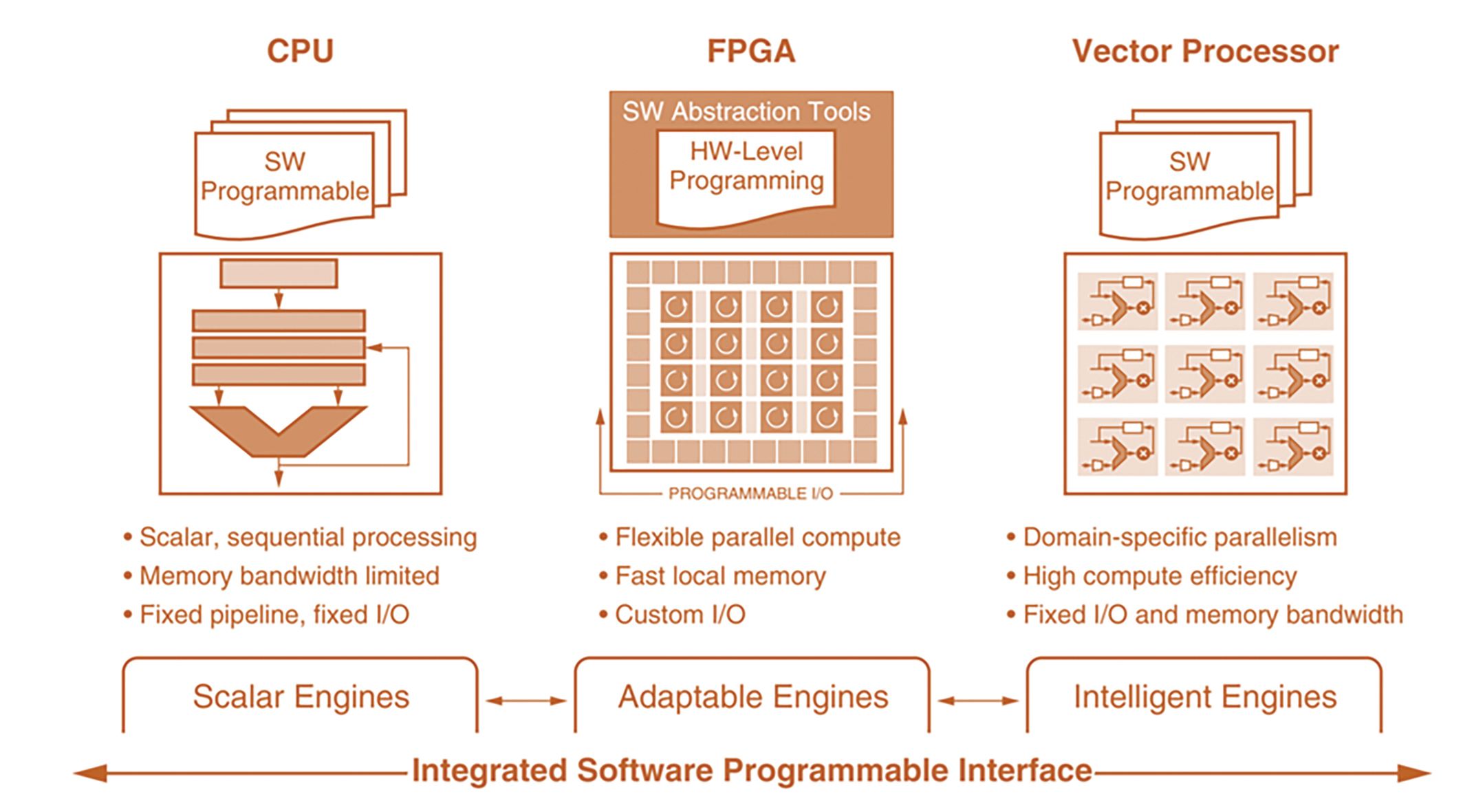 圖5 ACAP架構
圖5 ACAP架構
ACAP隨後提供實現基線分析所需的資源和接近資料來源的診斷分析功能,並能夠整合Apache Kafka和其他叢集系統等串流處理框架。
總歸來說,預測性維護是一項頗具挑戰性的工作。本文介紹如何讓資料和分析要求與可用功能合理銜接,但因篇幅有限,未能涵蓋該架構的全部詳情,但透過Lambda和Kappa架構的介紹,揭示一條讓速度層元件與批次處理層元件協調執行的實現途徑。為滿足邊緣端所需的算力,可充分發揮如廠商賽靈思(Xilinx)的ACAP等新型自行調適運算元件的效力來管理海量資料,在邊緣嵌入式系統層面提供必需的服務品質。
(本文作者為AMD工業、視覺、醫療與科學首席架構師)