工智慧(AI)及其子集機器學習(Machine Learning, ML)均代表著人類生存時代的重要階段性變化,雖然還有一些具爭議性的道德問題,但它們所提供的潛在效益實在令人難以想像(圖1)。
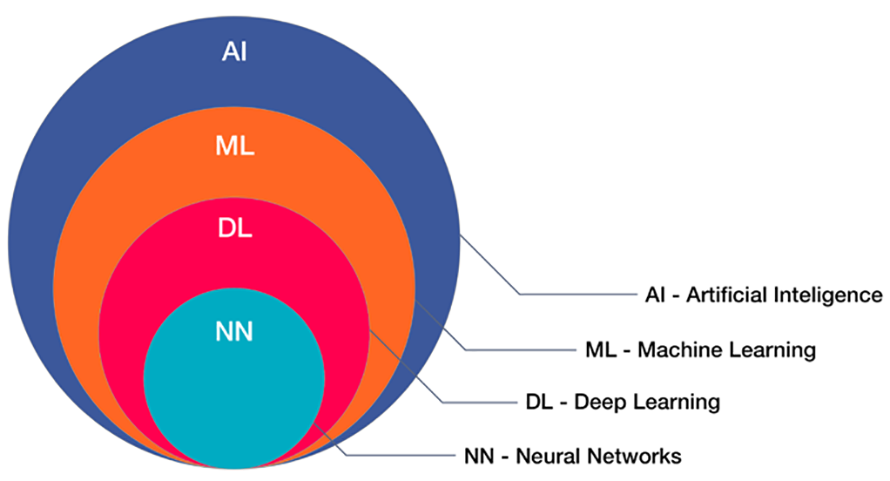 圖1 圖解AI、ML、DL與NN
圖1 圖解AI、ML、DL與NN
AI是一個非常廣泛的主題,所以本文將焦點集中於詳細介紹ML,特別是ML如何從雲端走到網路的邊緣。
何謂機器學習 從操作方式說起
「機器能思考(Thinking)嗎?」,這個問題促使偉大的科學家Alan Turing開發出「圖靈測試(Turing Test)」,到了現在,這仍然是回答上述問題的基準。如果機器可以學習,那麼證明完畢(QED)是它們所思考的嗎?顯然,這仍然是關於定義「思考」的諸多爭議的主題。機器需要一個開始學習的基礎,不過隨著時間推移,它們現在已能夠自主學習及發展出更強的理解能力。
真正引發ML爆炸性發展的是雲端運算和大數據中幾乎無限的容量和存取。後端系統可以大量獲取資料,然後在雲端伺服器上運行演算法。從雲端,可以獲得洞見並做出決策。因此,ML收集資料,再依據雲端中的演算法和訓練集來處理資料,進而採取行動,同時還在整個過程中開創出新的學習路徑。人為干預並非絕對必要。
ML的操作方式分成四類,包括監督式學習、非監督式學習、半監督式學習以及增強學習。
監督式學習使用帶有特徵的標記資料集,然後在訓練過程中將其提供給學習演算法,在此一過程中,學習演算法將會弄清楚所選特徵與標籤之間的關係。然後,人們使用學習的結果對新的未標記資料進行分類。
通常在不知道正確答案是什麼時,就會發生非監督式學習,因此資料集是未經標記的。在這種情境下,人們預期可找到資料本身就表明自然分組的操作模式,但答案並不明顯。此外,正確答案可能有許多組合,這取決於所考慮的變數。
對於僅有部分標記的大型資料集,可以做些什麼呢?要麼完成標記其餘資料的過程,要麼嘗試使用半監督式學習演算法。許多現實世界的機器學習問題都屬於這種類型,因為將整個資料集進行標記,用於完全監督式學習的方法通常過於昂貴和耗時。另一方面,非監督式學習方法可能是不需要的。因此,透過結合這兩種學習方法,理論上應該可以提供兩全其美的效益。研究顯示,同時使用標記和未標記資料,實際上可為學習提供最佳長期結果。
增強學習是最複雜的方法,但與人類實際學習的方式最相似,這種複雜的學習方式從博弈論和行為心理學獲得啟發。
這種學習方法通常涉及代理(正在進行操作的機器)和解譯器,代理將會暴露於執行操作的環境中,然後,解譯器將根據該操作的成功與否來獎勵或懲罰代理。
代理的目標是透過以不同的方式與環境反覆運算互動,從而找到將獎勵增加至最高的最佳方式,資料科學家在這種學習方法中唯一提供的是量化代理績效的方法。
這種方法已行之多年,早已被許多開發機器人和自動駕駛車輛的公司所採用。它通常與監督式學習等其他學習技術一起部署,開創出一種整體式學習模型(Ensemble Learning Model)。
藉資料分組分類 由異常值檢測事件
所獲取的資料需要分類成相關的物件,「二項式分類(Binomial Classification)」是指資料會被歸類在兩類中的其中一類,例如「在溫度範圍內」和「超出溫度範圍」。「多級分類」則可以有多種分類,例如對於溫度分類,它可以有「在範圍內」、「關斷高」、「臨界高」、「高警報」、「低警報」、「臨界低」、「關斷低」等類別。
異常檢測是一種單一等級分類演算法的類型,其唯一目標是找出資料集中的異常值或出現在常態分布之外的異常物件,這可用來檢測故障設備中奇怪瞬變之類的事件。
活用學習模型 研習相關技術
說明與學習模型有關的幾項技術。
這項技術長期以來一直是統計學家的主要工具,而資料科學和統計學在各個領域都有很多的相似之處。線性回歸也已應用到機器學習,作為在自變數改變時顯示因變數和自變數之間關係的一種標準方法(圖2)。
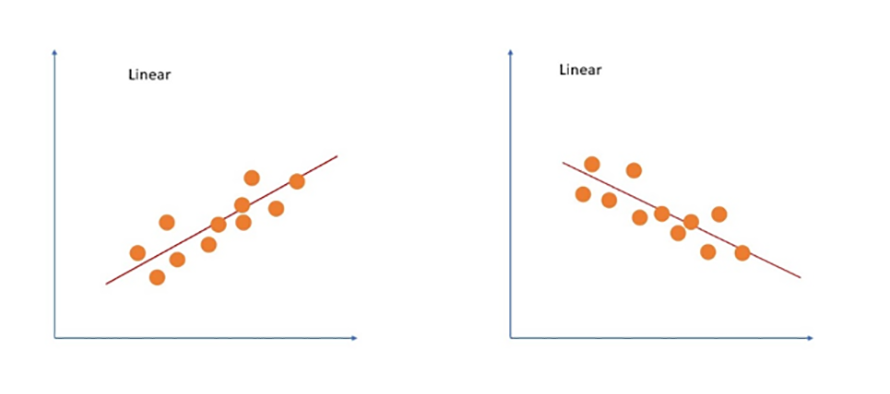 圖2 線性回歸
圖2 線性回歸
這種演算法具有很高的可解釋性,可以很好地處理異常值和遺漏觀察值(Missing Observation)。可以將多個決策樹協同工作,以創造出一種稱為整體樹(Ensemble Tree)的模型。整體樹可以提高預測準確度,同時在一定程度上減少過度擬合(Overfitting)(圖3)。
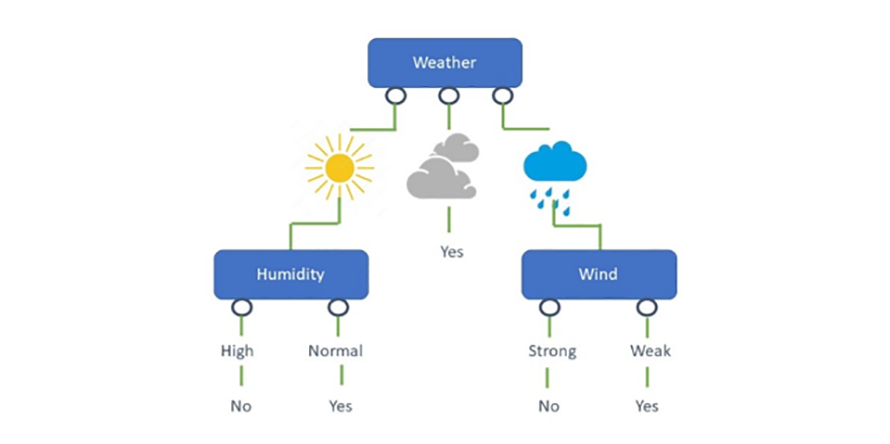 圖3 決策樹
圖3 決策樹
支援向量機(Support Vector Machines, SVM)通常用於分類,但也可以轉換為回歸演算法(圖4)。憑藉找到最佳超平面(不同資料類型之間的劃分),SVM可以在分類問題上帶來更高的準確度。為了找到最佳超平面(Hyperplane),此一演算法將在資料類型之間繪製出多個超平面。然後,演算法將會計算從超平面到最近向量點的距離,通常稱為餘裕(Margin)。然後,它會選擇使用產生最大餘裕的超平面,即最優超平面。最後,在分類過程中選取最優超平面。
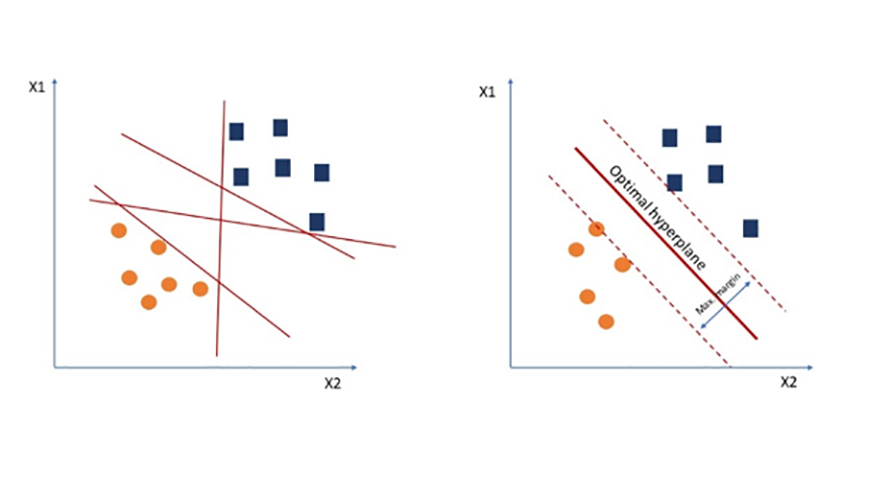 圖4 支援向量機
圖4 支援向量機
K平均數叢集(K-Means Clustering)可用來尋找資料點之間的相似性,並將它們分類成多個不同的組別,K是組別的數量(圖5)。
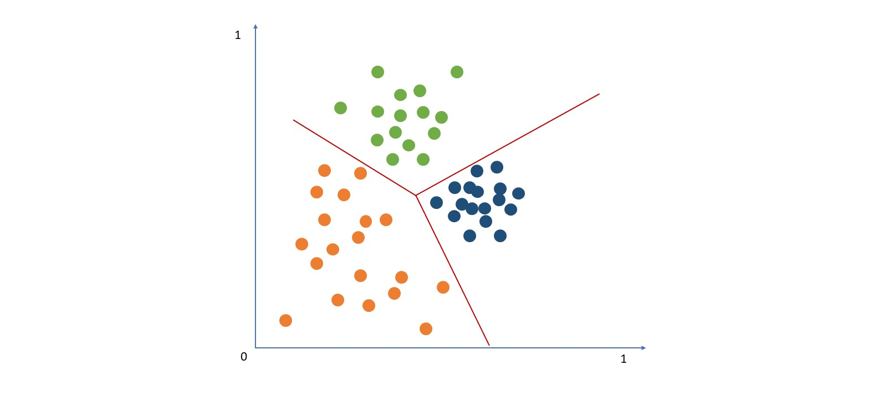 圖5 K平均數叢集
圖5 K平均數叢集
階層式叢集(Hierarchical Clustering)是沿著階層樹來創造已知數量且不同大小的重疊叢集(Overlapping Cluster)以組成分類系統,這種叢集可以通過各種方法來實現,最常見的方法是聚合和分裂。分裂過程會一直重複,直到獲得所需數量的叢集。
神經網路與機器人和神經科學的關係十分緊密,因此它自然成為最令人想要探索的演算法(圖6)。神經網路,特別是人工神經網路,由三個層級組成:輸入層,輸出層和一個或多個隱藏層,隱藏層可用來檢測資料中的模式。透過在每次處理一組資料時,為隱藏層內的神經元分配權重來完成此一工作。
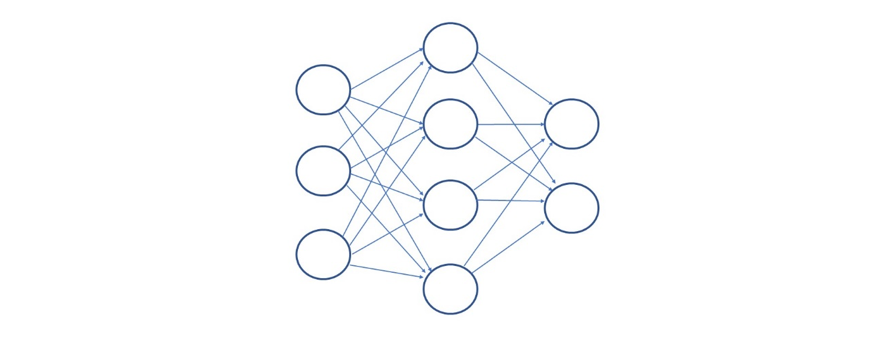 圖6 神經網路
圖6 神經網路
善用系統單晶片 網路邊緣也能ML
那麼,現在對於ML究竟是什麼有了一點基礎,這與在數十億個產品中的小型嵌入式單元裡的微控制器(MCU)有什麼關係呢?
當ML科學在突發猛進的發展時,其效率的提高和適用於某些使用案例的ML的調諧元素(Tuned Element)也同樣在快速發展。那些先前不得不在雲端完成的工作,現在已有可能在Nordic的nRF52840系統單晶片(SoC)這類具有1MB快閃記憶體和256kB RAM的微控制器上完成。在這類空間受限設備中,沒有人說這是易事,但它已被證明是可行的,而在其頂端的無線嵌入式系統單晶片具有更大的處理能力,ML工具和演算法更適用於這樣的平台。
當然,局限性是有的,nRF52840之類的元件永遠無法與建基於雲端系統的絕對優勢能力相競爭。但是,它能夠做到在沒有雲端連接的情況下執行即時且本地化的特定應用的機器學習。此外,它也可以與建基於雲端的系統(如Matillion或許多其他系統)結合使用,以提供具有許多效益的混合式ML學習方法。
各方前仆後繼投入 催生ML可用學習集
現在,有某些工具可以為ML開發出學習集。Tensorflow與其相關的Tensorflow Lite可能是最廣為人知的工具。這款在谷歌(Google)開發的工具是為ML所設計的開源庫框架。谷歌將它應用於該公司以人工智慧為目的的用途上,具有足夠強大的影像識別能力。
工作流程遵循使用Python和程式庫來建構模型和訓練集的多個階段。然後,Tensorflow將產生可在設備或系統上實施的C++代碼。用戶可從Apache MXNet、微軟(Microsoft) CNTK和PyTorch獲得其他的ML程式庫。
機器學習造就風潮 延續發展未來可期
到目前為止,ML仍然是一個尖端的領域,還有一段很長的路要走。但是,未來數年將可看到ML出現在大量的嵌入式系統中,其中,有些是比較陽春的,但有些則非常複雜。聲音和語音辨識應用顯然很具有吸引力,而機器中的語音辨識也是如此。在這些機器應用中,可以利用語音辨識發現軸承或電機可能已接近使用壽命的終點,需要更換了。
(本文作者為Nordic產品行銷經理)