IEEE P802.3ba 40G與100G乙太網任務小組已著手進行40G和100G乙太網標準的制定工作。2008年10月,該小組取得重大進展,推出IEEE Std 802.3-2008標準的第一版修正草案;也開發出一個可同時支援40G與100G乙太網的架構,並對實體層作出規範以實現背板、銅纜、多模/單模光纖乙太網間的通訊。
30多年來,為了滿足業界對封包交換網路日益成長的需求,乙太網路(Ethernet)技術也不斷進化。時至今日,透過網際網路協定,乙太網已經成為聯絡網際網路與其他網路的統一技術。事實上,由於其低成本、可靠度以及易用性,目前絕大多數的網路通訊不是從乙太網路開始,就是結束於乙太網路中。高度普及化的發展使得乙太網的生態體系變得非常複雜,電信網路、企業網路、消費者網路都是其生態體系中的一環,而且彼此共生。
在2006年,IEEE 802.3工作小組下成立了高速研究小組(Higher Speed Study Group, HSSG),並發現乙太網的生態體系需要某種比10G乙太網更快速的通訊技術,因為網路整合應用所造成的頻寬需求成長速度高於10G乙太網所能提供的容量成長速度。HSSG對這項議題進行研究後,發現運算與網路整合應用對頻寬需求的成長速度並不一致,因而使得乙太網的發展歷史上首度出現需求分歧的局面,並使HSSG必須針對不同需求規畫不同標準:伺服器與運算應用使用40G乙太網,網路整合應用使用100G乙太網。
2008年1月,IEEE P802.3ba 40G與100G乙太網任務小組正式成立,以統合40G與100G乙太網的發展,並凝聚共識形成40G與100G乙太網的標準草案。實體層(Physical Layer, PHY)規範開發是標準化的重要一步,因為標準化的實體層是實現背板、銅纜、多模/單模光纖網路間通訊的關鍵。2008年10月,該小組的工作取得重大進展,推出了IEEE Std 802.3-2008標準的第一版修正草案。本文將針對該任務小組所進行的專案內容與其所使用的技術進行介紹。
40G/100G乙太網規範出爐 穩健邁向標準化
該任務小組的專案目標希望未來的40G和100G乙太網標準應僅支援全雙工操作,並透過使用802.3媒體存取控制器(MAC)的方式保留802.3/乙太網的訊框格式,而且保留現行802.3標準所規範的最大與最小訊框尺寸。
此外,媒體存取控制器與實體層服務介面的誤碼率(BER)至少要低於10-12,且應妥善地支援光纖傳輸網路(OTN),並支援40Gbit/s的媒體存取控制器資料傳輸率。
至於在實體層規範方面,未來40G/100G乙太網的實體層至少應滿足的條件如表1所列。
表1 IEEE P802.3ba實體層規範概觀 |
| 距離(使用媒體) \ 網路類型 |
40G乙太網 |
100G乙太網 |
至少1公尺(背板) |
ˇ |
|
| 至少10公尺(銅纜) |
ˇ |
ˇ |
至少100公尺(OM3多模光纖) |
ˇ |
ˇ |
| 至少10公里(單模光纖) |
ˇ |
ˇ |
| 至少40公里(多模光纖) |
|
ˇ |
圖1為IEEE P802.3ba 40G與100G乙太網任務小組預定的工作時程。早在2006年起,乙太網聯盟(Ethernet Alliance)內的成員就已經開始籌畫並討論相關規範。因此當該任務小組正式於2008年1月成立時,該小組的工作進展相當順利,預計在2010年6月可完成標準確認的工作。
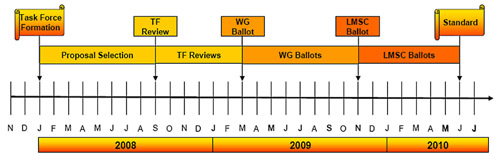 |
| 圖1 IEEE P802.3ba的發展時程預估 |
40G/100G乙太網延續OSI架構
IEEE P802.3ba修正案提出一個可支援40G與100G乙太網的混合式單一架構(圖2)。所有的實體層規範都還在發展階段。對應到第二層開放系統互聯(OSI)模型的媒體存取控制層則透過模型中的第一層實體層元件與媒體(光纖或銅纜)連結,該實體層由實體媒體依賴(Physical Medium Dependent, PMD)子層、實體媒體附加(Physical Medium Attachment, PMA)子層及實體編碼子層(Physical Coding Sublayer, PCS)三個子層所組成。若是背板或支援銅纜連結的實體層,還要再加上自動協議(Autonegotiation, AN)子層與向前糾錯(Forward Error Correction, FEC)子層。
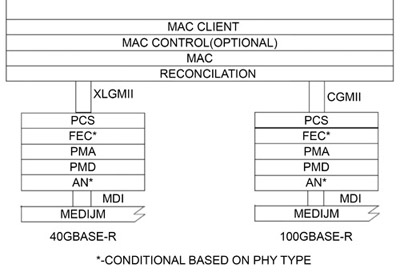 |
| 圖2 IEEE P802.3ba架構 |
PCS為實體與邏輯通道對應關鍵
如圖2所示,PCS層負責在各自的媒體獨立介面(Media Independent Interface, MII)與PMA子層間進行轉譯的動作。PCS層會將資料位元編碼成碼群(Code Group),再透過PMA子層傳送出去。PCS也會將接收自PMA子層的碼群解碼成原始資料。任務小組提出了一個稱為多通道分布(Multilane Distribution, MLD)的低必要負荷(Overhead)機制,並以此作為40G和100G乙太網PCS的基礎。
PCS中的MLD機制是一個彈性可延伸的架構,除了可支援目前所有的40G與100G乙太網實體層類型外,未來也將支援所有在IEEE P802.3ba專案下開發的新實體層,因此這個機制可以隨著持續演進的電子與光傳輸技術一同發展。PCS還具備其他功能,如提供訊框描述(Frame Delineation)、傳輸控制訊號、確保電子或光物理傳輸所需的必要時脈轉換密度、分割原始資料以利用多重通道進行傳輸,或反之將來自多重通道的資料重組成原始資料。
PCS結合了目前應用在10G乙太網中的64B/66B編碼機制。這個機制具備許多有用的特性,諸如低必要負荷、具備充足的編碼空間來支援必要的字碼等,而且與目前的10G乙太網一致。
在PCS中所實作的MLD機制以橫跨多重通道的66位元區塊切割為基礎。多重路徑分配指派到實體電子與光通道的實作會因為兩種介面的技術發展速度不一致而變得更複雜,因此PCS路徑概念的提出,讓光介面寬度的進展跟電子介面寬度的進展彼此脫鉤,將有助於降低實作的複雜度。
因此,傳輸PCS會在循環分配66位元區塊到不同PCS路徑前,在集合通道(40Git/s或100Gbit/s)上開始64B/66B編碼的動作(圖3)。
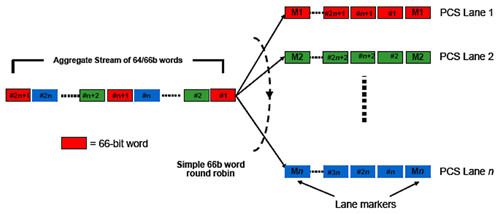 |
| 圖3 PCS路徑分配概念 |
PCS通道的需求量跟傳輸媒體是光纖或銅纜無關,如100G乙太網就固定使用二十個PCS通道。這個架構可支援的電子或光介面寬度等同於總PCS通道數量,因此二十個PCS通道可支援的介面寬度可以是一、二、四、五、十與二十個頻道或波長。在40G乙太網的情況下,四個PCS通道支援的介面寬度為一、二、四個頻道或波長。
一旦PCS通道建立後,它們就可以被任何可支援的介面寬度多路傳輸出去,且每條PCS通道都有一個定期被插入的獨特通道標記。所有的多路傳輸都在位元層級進行,而循環式的位元級傳輸將使得PCS通道在同一條實體通道中進行多路傳輸。這項獨特的特性使得每條PCS通道都會利用同一條實體線路來傳送位元資料,不受系統的總PCS通道數量與介面寬度影響。這讓接收器可以透過解多路傳輸的方式重建PCS通道,同時對訊號歪斜進行補償校正,從而正確地重組整條集合通道。獨特的通道標記也有助於接收器執行解歪斜功能(圖3),至於通道標記的頻寬則是由週期性地刪除封包間距(Interpacket Gap, IGP)所產生。
在接收端部分,PCS會接收所有的PCS通道,利用內嵌的通道標記重新對齊,然後重新將PCS通道排序成原有的順序,以重建原本的集合訊號。
採用MLD有兩大優勢,一是所有的編碼、擾頻(Scrambling)與解歪斜功能都可以由放置在主機元件旁的互補式金屬氧化物半導體(CMOS)元件執行,並減少資料位元的處理工作,不像在光模組中嵌入高速電子元件來進行位元多路傳輸(Bit Muxing)。這種做法可以簡化功能設計的複雜度,進而降低高速光通訊介面的成本。
PMA子層樣貌多變
PAM子層負責連接PCS與PMD子層,並肩負起傳輸、接收、碰撞偵測(視實體層類型)、時脈訊號恢復以及歪斜校正功能。本文將著重描述PMA子層的傳輸、接收與時脈訊號恢復功能。由於此一架構可支援多種介面,且實作方式非常多樣化,因此要完整解釋PMA的功能之前,必須先深入探討PMA子層的本身。
圖4是100G乙太網的典型架構,同時也是兩種100G乙太網架構--100GBASE-LR4與100GBASE-SR10的實作案例。100GBASE-LR4是一種在單模光纖中使用四波長,每個波長傳輸速率達25Gbit/s的100G乙太網實作架構;100GBASE-SR10則是採用十種波長,並透過十條平行光纖路徑來傳輸資訊的100G乙太網實作方式,這種架構所採用的光纖為多模光纖。這兩種實作方式可以說明PMA子層為了支援使用在40G與100G乙太網中的多重PMD所必須具備的架構彈性。
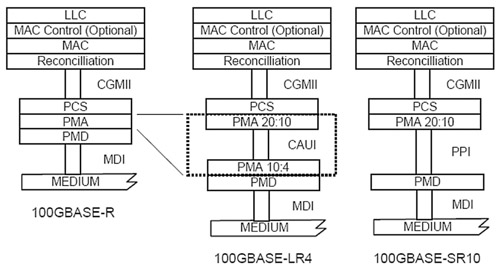 |
| 圖4 100GBASE-R的兩種架構 |
本文先前已經提及100G乙太網的PCS會創造出二十條PCS通道,以圖4實作案例來看,PMA子層的功能會分割成兩部分,以兩個透過電子介面互連的PMA元件來達成。這個電子介面稱為100Gbit/s附加單元介面(CAUI),是一種由十條單一通道速率可達10Gbit/s的實體通道所構成的介面。在這個案例中,在CAUI上方的PMA子層會把二十條PCS通道透過十條實體通道多路傳輸出去。在CAUI下方的PMA子層則必須將接收到的電子訊號重新定時,然後還原成原本的二十條PCS通道,然後再將其透過100GBASE-LR PMD所要求的四條通道傳送出去。
但100GBASE-SR10架構的實作方式就不是如此。這個架構的實作方式是採用一個主機晶片直接連接到一個光收發器,然後再連接到十條雙向平行式光纖路徑。因此PMA子層和PCS共存在同一顆元件上,並將二十條PCS通道多路傳輸到十條平行實體介面(Parallel Physical Interface, PPI)。這些連接PMA子層與PMD子層的電子介面不具備重新定時功能。
總之,PMA一定會具備多路傳輸和時脈恢復功能,但實際的實作方式則依所使用的特定PMD類型而定。
圖4也說明了IEEE P802.3ba修正案所提出的多種晶片介面。其中有些介面以往是晶片間的實體介面,但在IEEE P802.3ba修正案中將變成晶片內部的邏輯介面。邏輯介面的規範只會定義這些介面的訊號與行為,但實體介面則會對訊號的電子和時序參數進行規範。
邏輯/實體介面規範涇渭分明
邏輯介面將有助於實現系統單晶片(SoC)的實作,可將不同的供應商所提供的核心與不同子層整合到單晶片中。在IEEE P802.3ba修正案的規範下,這些不同的核心整合到單晶片的方式就跟以往採用不同供應商的獨立晶片兜出一套系統的方法一樣。雖然實體介面規範能涵蓋邏輯介面規範,但在部分案例中,有些介面似乎不可能被實作成實體介面,因此對這類介面進行電子和時序參數規範是不必要的。
有三種晶片介面的定義可以單一架構支援兩種速率。媒體獨立介面(MII)是一種可以連結媒體存取控制器與實體層的邏輯介面,而附加單元介面則是一種可以延伸PCS與PMA子層連接的實體介面。這些介面的命名方式延續自10G乙太網,也就是IEEE Std 802.3ae的傳統,例如10G乙太網的XAUI介面與XGMII介面中的X,所指的是羅馬數字的十。而羅馬數字的四十寫作XL,一百寫作C,因此40G乙太網所使用的附加單元介面與媒體獨立介面便命名為40Gbit/s附加單元介面(XLAUI)與40Gbit/s媒體獨立介面(XLGMII)。以此類推,100G乙太網的附加單元介面與MII介面也就被命名為100Gbit/s附加單元介面與100Gbit/s媒體獨立介面(CGMII)了。以下會進一步討論的平行實體介面則是用以連接40GBASE-SR4和100GBASESR10的PMA子層和PMD子層的介面。
分別可支援40Gbit/s與100Gbit/s資料傳輸率的40Gbit/s附加單元介面與100Gbit/s媒體獨立介面被定義為連接媒體存取控制與PCS的邏輯介面,兩種介面規範除了時脈要求不同之外,其他地方都是一樣的。
這種介面可提供由八條8位元通道所組成的64位元收發資料路徑,每一條通道各自有一個控制位元來表明其所傳輸的訊號是資料或控制資訊(如定義符號或閒置)是否在時脈週期間被傳送。接收路徑與發送路徑各有單一的時脈,其速度為資料傳輸率的六十四分之一,亦即625MHz(40G乙太網)或1.5625GHz(100G乙太網)。由於這種高速、高寬度的介面不會被實作成連接不同實體晶片的介面,因此被定義成邏輯介面,僅運用在晶片內部的資料傳遞。
分別可支援40Gbit/s與100Gbit/s資料傳輸率的40Gbit/s附加單元介面與100Gbit/s附加單元介面則是一種低接腳數的實體介面,以允許媒體存取控制器與實體層的子層得以切割開來,就像10G乙太網所使用的10Gbit/s附加單元介面(XAUI)。這種介面會自行產生時脈訊號,具備多重通道,並使用64B/66B編碼序列鏈路技術。每條通道的有效資料速率須達10Gbit/s,因此在加計64B/66B編碼的影響後,其實際訊號速率必須達到10.3125Gbit/s。
這些通道採用低擺盪交流耦合平衡差動訊號技術,以確保訊號能傳遞約25公分左右的距離。以40Gbit/s附加單元介面為例,這個介面由收發各四條通道所組成,每條通道的資料速率為10Gbit/s,因此其實際的訊號路徑數量為八對(十六條);而100Gbit/s附加單元介面則是由收發各十條速率為10Gbit/s的通道所組成,因此總共使用了二十對(四十條)訊號路徑。
這些介面是主要被用來當成晶片間的連接介面,例如數位電路與實體層(通常是類比電路)所使用的技術是不同的,因此在進行系統晶片設計時,會將數位電路整合到系統晶片中,把實體層獨立成另外一顆元件。此外,由於在IEEE P802.3ba修正案中並未具體定義40Gbit/s附加單元介面與100Gbit/s附加單元介面的連接器機構設計,因此未來有可能會出現可插式的設計規範,以方便單一主機系統可以透過模組插拔的方式支援不同類型的實體層。目前的介面規範為訊號必須能在使用FR4材料的印刷電路板上傳輸約25公分,並支援一個連接器。至於可插式模組的標準化,因為不屬於IEEE 802.3工作小組的負責範圍,因此將交由其他產業組織進行。
平行實體介面是一種連接PMA與PMD子層的短距離實體介面。這個介面是40G乙太網與100G乙太網共用的介面,差別僅在於所使用的通道數。平行實體介面與附加單元介面有許多共通特性,如都採用64B/66B編碼,實際訊號速度為10.3125Gbit/s,具備各四條/十條收發通道等。
PMD設計決定媒體與傳輸距離
目前任務小組正在發展不同的實體層定義,以滿足運算與網路整合應用的不同需求。對運算應用而言,為了能滿足資料中心的應用需求,實體層解決方案的傳輸距離須達100公尺,才能適合不同伺服器類型,如刀鋒式、機架與直立式使用;針對網路整合應用,實體層的傳輸距離與支援的媒體類型除了要滿足資料中心網路之外,還須能運用在辦公室內部及辦公室之間的環境。表2為針對不同媒體存取控制器速率所制定的實體層規範。
表2 IEEE P802.3ba所定義的實體層規範 |
| 距離(使用媒體) \ 網路類型 |
40G乙太網 |
100G乙太網 |
至少1公尺(背板) |
40GBASE-KR4 |
|
| 至少10公尺(銅纜) |
40GBASE-CR4 |
100GBASE-CR10 |
至少100公尺(OM3多模光纖) |
?40GBASE-SR4 |
100GBASE-SR10 |
| 至少10公里(單模光纖) |
40GBASE-LR4 |
100GBASE-LR4 |
| 至少40公里(多模光纖) |
|
100GBASE-ER4 |
40GBASE-KR4 PMD是一種針對背板傳輸應用所開發出來的實體層規範,而40GBASE-CR4與100GBASE-CR10 PMD則是用來支援銅纜傳輸的實體層。這三種實體層都沿用Ethernet 10GBASE-KR背板傳輸所採用的架構,並且已針對通道與PMD子層有明確的要求。
這些實體層類型的架構如圖5所示。這三種實體層均採用標準40GBASE-R與100GBASE-R的PCS與PMA子層,但值得注意的是BASE-CR與 40GBASE-KR4還包含了自動協議子層,並可選擇採用向前糾錯子層。
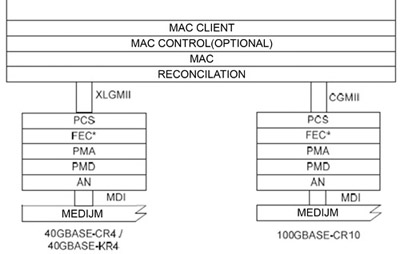 |
| 圖5 背板與銅纜架構 |
BASE-CR與40GBASE-KR4的通道規範也沿用了一些背板乙太網專案(Backplane Ethernet Project),亦即10GBASE-KR通道規範,以確保能穩固地以10Gbit/s的速度傳送資料。40G乙太網與100G乙太網的實體層重複利用了這些開發成果,並將通道數分別提升為四通道與十通道。BASE-CR規範也沿用了10GBASE-CX4規範中的纜線組合定義,例如40G BASE-CR4便選擇則支援兩種連接器:可支援銅纜或光纖的模組QSFP連接器,以及10GBASE-CX4連接器。支援後者將可確保設備使用者能夠從現有的10GBASE-CX4升級成新一代乙太網。
40GBASE-KR4與40GASE-CR4 PMD子層可將40G乙太網的訊號利用四對差動線路進行雙向背板傳輸,或是使用雙軸銅纜媒體,而100GBASE-CR10 PMD子層則可透過以雙軸銅纜構成的十對差動線路傳輸100G乙太網的資料達10公尺。
支援光纖的PMD子層也擁有共通架構(圖6)。由於要以單一架構支援不同實體層類型,因此PMA子層在此扮演將PCS通道轉換到PMD子層所要求的對應實體通道數量的關鍵角色。
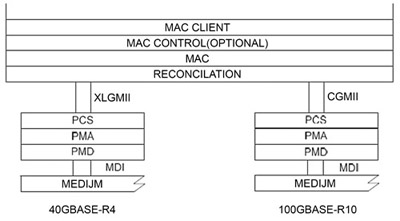 |
| 圖6 40GBASE-R與100GBASE-SR架構 |
在40GBASE-SR4與100GBASE-SR10規範中,其所使用的PMD子層採用波長850奈米的光通訊技術,並可在OM3平行光纖中傳輸100公尺。由於每個通道的頻寬為10Gbit/s,因此40GBASE-SR4採用四條平行OM3光纖來進行雙向傳輸,而100GBASE-SR10則使用十條平行OM3光纖。
至於40GBASE-LR4的通訊波長則為1,310奈米,並採用粗波分割多工(Coarse Wave Division Multiplexing, CWDM)技術,以達到能以單模光纖雙向傳輸至少10公里的目標。其光柵符合ITU G.694.2規範,一共可使用1,270、1,290、1,310與1,330奈米四種波長。每個波長的有效頻寬為10Gbit/s,實際頻寬則為10.3125Gbit/s(因為採用64B/66B編碼)。這種PMD子層設計盡可能地重複利用了現有的10G PMD技術。
100GBASE-LR4一樣使用1,310奈米波長進行通訊,但採用的是高密度分波多工技術(Dense Wave Division Multiplexing, DWDM),其傳輸距離同樣為10公里(使用單模光纖)。其光柵採用ITU G.694.1規範,所使用的波長組合為1,295、1,300、1,305與1,310奈米。每個波長的有效頻寬為25Gbit/s,實際頻寬28.78125Gbit/s。因此100GBASE-LR4的PMD子層可以透過四個波長實現雙向傳輸的100G乙太網。
100GBASE-ER4則是100GBASE-LR4的延長版,兩者所採用的光柵、波長與多工技術相同,但為了將傳輸距離延長至40公里,因此在實際部署時應該會採用半導體光放大器(Semiconductor Optical Amplifier, SOA)。
40G/100G乙太網分進合擊
乙太網在經過多年發展之後,已經變成最普遍的網路通訊技術,幾乎所有使用網際網路通訊協定的網路,都採用乙太網技術。然而,由於其應用領域廣泛,涉入的生態體系錯綜複雜又彼此共生,因此標準的分歧發展在所難免,也導致兩種次世代高速乙太網標準同時誕生。
未來,在資料中心、伺服器等運算領域,40G乙太網將成為應用的首選;在網路整合應用方面,業界預計將選用100G乙太網。這些新標準的出現,將強化乙太網技術低成本、高可靠度與架構簡單的優勢,並鞏固乙太網無所不在的領導者地位。
(本文作者John D'Ambrosia任職於Force10 Networks、David Law任職於3Com、Mark Nowell任職於思科。本文由乙太網聯盟提供,文中所陳述之意見僅代表作者個人意見,不代表其所屬公司或組織之立場。)