為改善利用反矩陣計算幾何精度因子耗時的缺點,基於可變學習率類神經網路的架構近似幾何精度因子,不僅適用於GPS,也適用於WSN及無線通訊系統。且經過模擬後,透過可變學習率類神經網路幾何精度因子的四種架構對於估測幾何精度因子有較高的精確度,並且可大幅地減少訓練的次數。
幾何精度因子(Geometric Dilution of Precision, GDOP)可用以顯示量測誤差和定位誤差關係的幾何效應。若量測單元的變異數都均等,幾何精度因子是挑選最佳量測單元的一個重要法則。本文目標是從所有可用的量測中挑選最適當的量測單元,量測單元挑選的法則是利用幾何精度因子最小的子集合所形成的量測單元進行定位。在計算幾何精度因子的方法中,最大體積法並不能保證所選出的量測單元是最佳的;而利用反矩陣求解則會產生巨大的計算量,進而造成即時應用上的負擔。
利用可變學習率倒傳遞類神經網路(Variable Learning Rate Back-Propagation Neural Network, VLRBPNN)進行幾何精度因子之近似,提出兩個新型架構,實現可變學習率演算法估測幾何精度因子,並進行二維及三維環境中的模擬。由結果顯示,本文提出的架構能提供優越預測精度,而且比傳統的反矩陣方法更能大幅減少計算複雜度。除此之外,本文提出的架構所挑選的量測單元個數沒有限制,不僅可適用於全球衛星定位系統(GPS),而且也可用於無線感測網路(WSN)與蜂巢式通訊系統(Cellular Communication System),如全球微波存取互通介面(WiMAX)、長期演進計畫(LTE)。
GDOP可提高GPS定位精準度
幾何精度因子的概念,最初用於三維(3D)環境中,是選擇衛星幾何分布較佳的法則。當有足夠的量測資訊時,利用幾何精度因子較小的子集合所形成的量測單元,可降低幾何分布不佳時所產生的誤差,並提高定位精度,因為多餘的量測資訊會大幅增加計算負擔,並無法顯著改善定位精度,所以在進行位置估測前,快速而正確選擇最合適的量測單元非常重要。
幾何精度因子通常是假設所有的量測單元有一致的誤差模式,即每個單元的量測精確度相同。許多論文提出利用幾何精度因子的概念以提高GPS的定位精度。而這些方法幾乎都是利用反矩陣計算幾何精度因子,雖然可保證取得最佳子集合,但計算複雜度太高以致於並不實用。
幾何精度因子幾乎和四個衛星與使用者所形成的四面體體積成反比。當這四顆衛星分布均勻時所形成的四面體體積會比較大,因此幾何精度因子會較小,而可獲得較高的定位精確度。最大體積法則是利用四面體體積取代幾何精度因子以進行最佳量測單元的挑選,雖然只需較小的計算量,但並不保證所挑選的衛星是最佳的,此無法被接受。
倒傳遞類神經網路為監督式學習網路,普遍用於分類與預測技術,參考資料11與12中提出兩種網路架構以便利用倒傳遞類神經網路近似幾何精度因子。倒傳遞類神經網路藉由學習量測矩陣與其特徵值倒數間的輸入/輸出關係以估測幾何精度因子,但倒傳遞類神經網路收斂速度緩慢且容易陷入局部極小值(Local Minimum)。為考慮效能與效率,本文提出兩個新的架構,利用可變學習率(Variable Learning Rate)倒傳遞類神經網路以近似二維(2D)及三維環境中的幾何精度因子。
由模擬結果顯示,以可變學習率演算法為基礎的架構,可提供更快的收斂,並且大幅減少訓練迭代的個數。這種以可變學習率演算法為基礎的架構可精確地選擇量測單元,可應用於GPS、WSN及無線通訊系統,而這三個系統的量測單元分別是衛星、感測器及基地台。
在蜂巢式通訊系統選擇最適合的基地台進行行動台(MS)位置的估測,將使定位誤差變小。由於行動台會一直與提供服務的基地台進行通聯,所以可優先選擇提供服務的基地台,再加上任意三個基地台以形成不同的子集合,如此子集合的數目會從35(C47)個降為20(C36)個。接著估測所有子集合的幾何精度因子並挑選出最小的子集合,最後,利用這個子集合中的量測單元進行位置的估測。由模擬結果顯示,本文提出的可變學習率為基礎的架構比其他的架構能提供更精確的預估,無論要挑選多少個量測單元,這些架構都可用於近似幾何精度因子,另外,本文只先選擇有四個量測單元的子集合進行模擬。
選擇最小GDOP子集合
幾何精度因子廣泛用於表示三維空間中衛星的幾何分布情形。為提高定位精度,必須選擇最小的幾何精度因子所形成的子集合。在三維座標系統中,第i個衛星與使用者之間的距離可以表示成:
………………………………………………………(1)
其中(x,y,z)和(Xi,Yi,Zi)分別是第i個衛星與使用者的位置。C是光速,tb表示時間偏移量,vri)則為量測雜訊。將(1)式利用泰勒展開式在使用者位置(x,y,z)附近展開,並忽略高階的項次,則可以獲得:
………………………………………………………(2)
其中δx,δy,δz分別是x,y,z座標的修正量,
………………………………………………………(3)
(ei1,ei2,ei3),i-1,2…,n,表示從使用者到衛星的視線傳播(Line-of-Sight, LOS)向量。
這些線性化的方程式可以用向量形式表示成:Z = H δ + V ……………………………(4)
其中
而
為一幾何矩陣。
向量變數δ在(4)式中,可以利用最小平方法(LS)求解,即
再假設所有的量測單元都是非相關的,而且具有相同的變異數σ2,則誤差協方差矩陣可以表示為:
………………………………………………………(5)
這些變異數是(HT H)-1矩陣對角元素的函數。所以幾何精度因子可以定義成:
………………………………………………………(6)
類神經網路應用廣泛
類神經網路屬於人工智慧領域,具有「自我學習」的能力,是一種用來模仿生物神經網路的資訊處理系統。類神經網路主要是由許多的人工神經元(Artificial Neuron, AN)組成,亦可稱為處理單位(Processing Element, PE)。
類神經網路的運作過程主要可分為學習過程(Learning)與回想過程(Recalling)。學習過程是指網路可依不同的學習演算法,從學習範例中進行調整網路權重值與偏權值的過程;回想過程則是將待推測的範例轉換為輸入,與學習過程中所調整的加權值作運算,得到網路輸出值,並和目標輸出值進行比較,以評估類神經網路的學習成效。
隨著科技的進步,類神經網路廣泛應用於各個領域,因為網路本身具有學習記憶、高度平行處理、容錯與複雜模式簡單化等能力。類神經網路的種類繁多,依網路架構可分為前饋式網路(Feed-Forward Network)與回饋式網路(Feed-Back Network),依學習方法則可分為監督式學習網路(Supervised Learning Network)與非監督式學習網路(Unsupervised Learning Network)。
倒傳遞類神經網路用於分類/預測
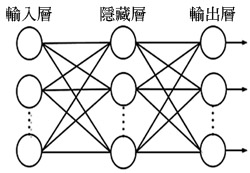 |
| 圖1 倒傳遞類神經網路架構 |
倒傳遞類神經網路屬於監督式學習網路,普遍應用於分類與預測技術。倒傳遞類神經網路能夠學習與實現線性與非線性函數,屬於多層神經網路,主要由輸入層(Input Layer)、隱藏層(Hidden Layer)、輸出層(Output Layer)組成(圖1)。輸入層用以表現網路的輸入變數,並沒有計算能力,神經元個數視問題情況而定。隱藏層用以表現輸入處理單元之間的交互影響,其影響程度則可使用多種函數進行計算。輸出層用以表現網路的輸出變數,神經元個數亦視問題而定。
倒傳遞類神經網路是以最陡坡降法(Gradient Steepest Descent Method)為基本學習法則。最陡坡降法利用學習速率乘以負梯度,以決定權重值和偏權值的變化量。每當輸入一個訓練範例,類神經網路即會調整連結權重值,調整的幅度和誤差函數對權重值的偏微分值大小成正比,故
………………………………………………………(7)
其中,ε為學習率,wij表示連結第i個神經元到第j個神經元的權重值。倒傳遞演算法主要在於降低網路輸出值與目標輸出值之間的差距,因此必須定義一個誤差函數F,如(8)式所示。其中Tk為第k個神經元的目標輸出值,Ok為第k個神經元的網路輸出值。
………………………………………………………(8)
學習率的大小,將會影響網路收斂的情形。如果學習率設定太大,訓練過程容易造成反覆振盪,使網路變得不穩定。如果學習率設定太小,則須花費較長時間才能完全收斂,而且易陷入局部最小值中,無法達到最佳效能。
可變學習率演算法為較佳修正方式
傳統倒傳遞演算法的學習率在訓練過程中是固定不變的,學習過程需要大量的計算時間與訓練迭代次數。為了改學習速度與收斂情形,可變學習率演算法是理想的修正方法,讓學習率在網路訓練過程中視情況變化。
首先,計算初始網路輸出和誤差。在每一次訓練循環中,使用目前的學習率計算新的權重值和偏權值,接著,計算新的輸出和誤差。若新誤差超越舊誤差的1.04倍,則新的權重值和偏權值就排除不使用,而將學習率減少為原來的0.7倍。否則,新的權重值和偏權值將保持不變;若新誤差遠少於舊誤差,則增加學習率為原來的1.05倍。
在訓練過程中,若學習率比較大,卻仍可使網路保持穩定學習,則持續增加學習率;若學習率過大而無法降低誤差時,則應減少學習率,直到網路恢復穩定學習,而學習率的初始值設為0.01。具有適應性學習率的倒傳遞演算法,也運用動量(Momentum)的概念,加入動量的目的是為了提升倒傳遞類神經網路調整權重值的效率,若權重值更新的方向錯誤,則動量係數可以進行修正權重值更新方向,本文在三維空間的模擬也加入動量以協助網路收斂,動量的值設為0.9。
以近似GDOP提出四種網路架構
在不同的系統中,幾何精度因子是一種評估定位精度的標準,然而,傳統的反矩陣計算方法會造成計算的負擔,而最大體積法則無法確認所選擇的量測單元最佳。因此,研究人員曾參考資料11與12提出利用傳統倒傳遞類神經網路學習量測矩陣與特徵值(Eigenvalue)倒數的關係,以估測三維空間的幾何精度因子。在本文中,將這兩種架構改用可變學習率演算法來近似,另外,在二維及三維環境下提出兩個新的對映架構。
若有多個量測單元可供使用時,利用幾何精度因子最小的子集合進行定位,將可避免不好的幾何分布效應,並且可獲得較佳的位置精度。在三維空間中,四顆衛星通常已足夠定位所需,而毋須使用所有的可視衛星(Visible Satellites)。而在蜂巢式通訊網路中,只須要從七個基地台中挑選幾何分布最佳的四個,進行行動台位置的估測即可。從式(6)可知,HT H為4×4矩陣,故會有四個特徵值λi,i=1,2,…4,而(HT H)-1矩陣的特徵值則為λi-1,i=1,2…4。由矩陣的基本理論可知,矩陣的對角線元素和會等於其特徵值相加,因此,幾何精度因子又可以表示成:
………………………………………………………(9)
二維環境中,四個量測單元組成的幾何矩陣為:
………………………………………………………(10)
HT H為一3×3矩陣,所以幾何精度因子為:
………………………………………………………(11)
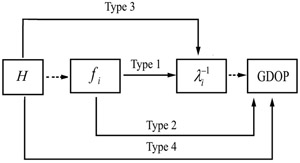 |
| 圖2 四種輸入/輸出的映射架構圖 |
本文將敘述在二維及三維環境中四種輸入/輸出的映射關係,前兩種架構是參考資料11與12中所提出,而後兩種架構則是本文提出,這些架構是都以三層網路架構為基礎,可表示成「輸入層個數p-隱藏層個數-輸出層個數q」。這四種架構的關係,如圖2所示。
| ‧ |
|
| |
(1.A)三維空間,四個輸入/四個輸出的映射關係:
………………………………………………………(12)
此網路架構具有以下的輸入/輸出映射關係:
輸入:(f1,f2,f3,f4)T
輸出:(λ1-1,λ2-1,λ3-1,λ4-1)T
由f到λ-1的映射是非線性且無法確實分析的。經過訓練之後,此種映射關係可以近似幾何精度因子,其值等於輸出值總和的平方根。
(1.B)二維空間,為三個輸入/三個輸出的映射關係。
………………………………………………………(13)
此網路架構具有以下輸入/輸出的映射關係:
輸入:(f1,f2,f3)T
輸出:(λ1-1,λ2-1,λ3-1,)T
網路輸出值的總和即為幾何精度因子的平方。 |
| ‧ |
|
| |
(2.A)三維空間,即四個輸入/一個輸出的映射關係。在這種情況下,幾何精度因子直接作為訓練資料的輸出,此網路具有以下架構。
輸入:(f1,f2,f3,f4)T
輸出:GDOP
(2.B)二維空間,為三個輸入/一個輸出的映射關係。
輸入:(f1,f2,f3)T
輸出:GDOP
|
| ‧ |
|
| |
(3.A)三維空間,為十二個輸入/四個輸出的映射關係。此種映射是直接利用H矩陣元素近似特徵值的倒數。此網路架構具有以下輸入/輸出的映射關係。
輸入:(e11,e12,e13,e21,e22,e23,e31,e32,e33,e41,e42,e43)T
輸出:(λ1-1,λ2-1,λ3-1,λ4-1)T
(3.B)二維空間,八個輸入/三個輸出映射關係。
輸入:(e11,e12,e21,e22,e31,e32,e41,e42)T
輸出:(λ1-1,λ2-1,λ3-1)T |
| ‧ |
|
| |
(4.A)三維空間,為十二個輸入/一個輸出的映射關係,此架構是利用H矩陣的元素直接近似幾何精度因子,並具有以下輸入/輸出的映射關係。
輸入:(e11,e12,e13,e21,e22,e23,e31,e32,e33,e41,e42,e43)T
輸出:GDOP
(4.B)二維空間,八個輸入/一個輸出映射關係。
輸入:(e11,e12,e21,e22,e31,e32,e41,e42)T
輸出:GDOP |
由一些已知輸入向量與相對應的輸出向量,經過訓練過程後,則可建立類神經網路的模型,當有新的輸入向量時,模型即可預估出對應的輸出向量,因此可利用這四種架構近似幾何精度因子。模擬結果顯示,本文所提出的架構三和架構四只需較少的隱藏層神經元個數及訓練次數就會有精確之預估值,因此具有低計算負擔及高精度估測的優點,特別是,以上的架構可適用於挑選任意個量測單元的情況。
透過單一隱藏層架構進行模擬
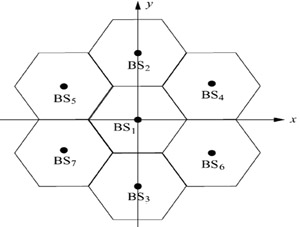 |
| 圖3 七個蜂巢的無線通訊系統架構圖 |
以蜂巢式無線通訊系統為模擬環境,每個蜂巢的大小都相同,而提供服務的基地台位於中間,如圖3所示。每個蜂巢的半徑為5公里,行動台位置均勻分布在中心蜂巢。基地台一是提供服務的基地台,座標在(0, 0, 200m)。基地台二到基地台七的高度分別為150公尺、140公尺、160公尺、120公尺、110公尺及130公尺,而行動台的高度則是均勻分布在(0, 60m)。
無線通訊定位系統的誤差主要來自於非視線傳播效應的影響。本文採用均勻分布誤差模式(Uniformly Distributed Noise Model),假設所有的基地台的非視線傳播誤差都均勻分布在(0,Ui=300m)間,i=1,2…7,其中Ui是最大誤差值。在不同種類的類神經網路中,單一隱藏層是最廣泛使用的架構,因此,選用這種架構進行模擬。幾何精度因子的差值(GDOP Residual)定義為真實的幾何精度因子與估測的幾何精度因子間的差值,並可衡量估測的準確性。利用嘗試錯誤法則可確定網路架構的參數,圖4和圖5分別表示在三維空間及二維空間時,平均幾何精度因子差值會隨著訓練個數(Epoch)的增加而收斂,也就是當訓練個數增加時,平均幾何精度因子的差值就會降低。不管是在三維空間或二維空間,當訓練個數達兩千筆時就能提供良好的估測精度,因此可變學習率倒傳遞類神經網路只需要較少的訓練個數,但卻能提供更快的收斂速度。
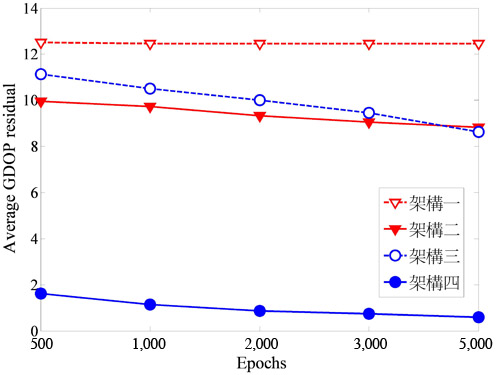 |
| 圖4 三維空間時幾何精度因子差值與訓練個數的變化情形 |
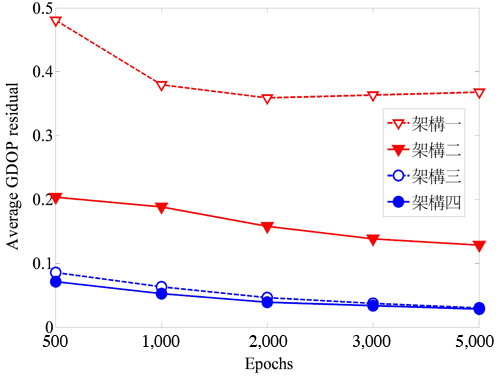 |
| 圖5 二維空間時幾何精度因子差值與訓練個數的關係圖 |
隱藏層神經元的個數也是相當重要。當隱藏層神經元個數太少時,容易產生較大的誤差,增加隱藏層神經元的個數可改善這種情況,但同時也會影響收歛的速度。一般隱藏層神經元個數的設定有幾種,包括輸入神經元和輸出神經元的個數總和取一半、與輸入神經元的個數相同、兩倍的輸入神經元個數加一、三倍的輸入神經元個數加一。圖6和圖7分別表示在三維空間及二維空間時,平均幾何精度因子差值會隨著隱藏層個數的增加而遞減,當隱藏層個數為(2p+1)時就能提供精確的估測結果,其中p代表輸入神經元個數。也就是當隱藏層個數超過(2p+1)時,估測精確度的改善即十分有限。綜合以上的模擬結果可知,經過訓練後,可變學習率倒傳遞類神經網路只需兩千筆訓練資料及(2p+1)個隱藏層神經元即可精確估測幾何精度因子。
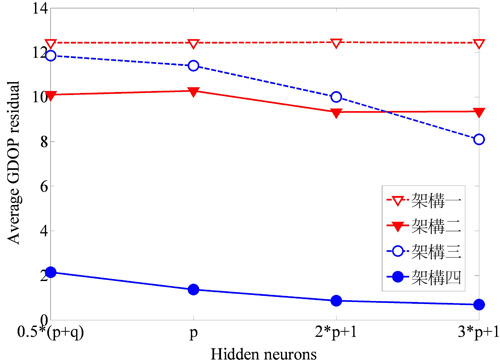 |
| 圖6 三維空間時幾何精度因子差值與隱藏層個數的變化情形 |
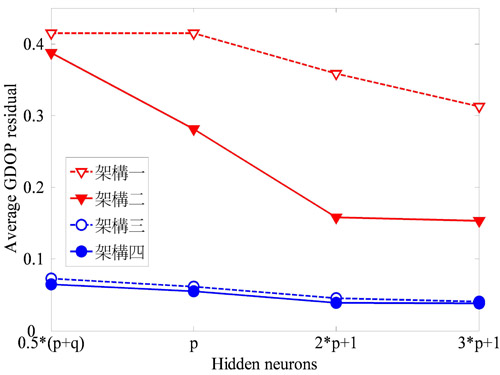 |
| 圖7 二維空間時幾何精度因子差值與隱藏層個數的變化情形 |
圖8表示在三維空間時,四種架構的幾何精度因子的誤差累積分布情形,在三維空間中,架構一及架構三的幾何精度因子等於λi,i=1,2,3,4總和的平方根。一個輸出的架構比四個輸出架構的精確度更高。架構一是由估測特徵值的倒數而獲得幾何精度因子,但結果顯示其效能最差。在四個輸出的情況下,本文提出的架構三能提供較佳效能;而架構四則在一個輸出的情況下能顯示最好的準確度,且只需兩百筆訓練資料及0.5×(p+q)個隱藏層神經元就能勝過其他架構以兩千筆訓練資料及2p+1個隱藏層神經元估測的結果。圖9表示在二維空間時,幾何精度因子差值的誤差累積分布情形,本文提出的架構也展現優越的估測性能,也只需兩百筆訓練資料及0.5×(p+q)個隱藏層神經元就能比其他架構提供更好的估測值。
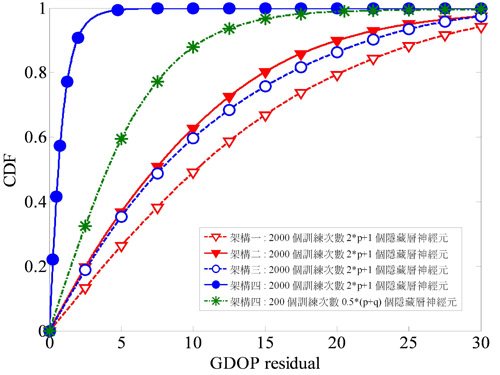 |
| 圖8 三維空間時幾何精度因子差值的誤差累積分布情形 |
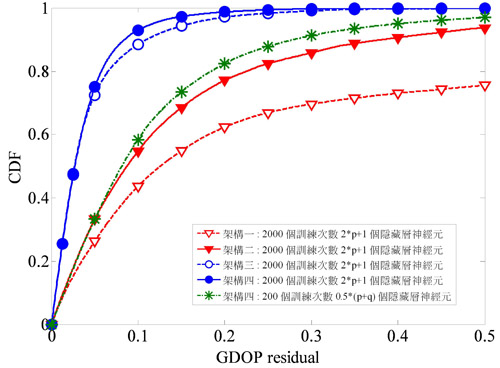 |
| 圖9 二維空間時幾何精度因子差值的誤差累積分布情形 |
圖10和圖11分別表示在三維空間及二維空間時,非視線誤差的大小是否會對幾何精度因子的估測造成影響。由圖形可知,當非視線誤差變大時,幾何精度因子的平均差值並不會有顯著的變化。所以幾何精度因子的差值並不會隨著非視線誤差的增加而遞增,可見這些架構對於非視線誤差敏感度並不顯著。
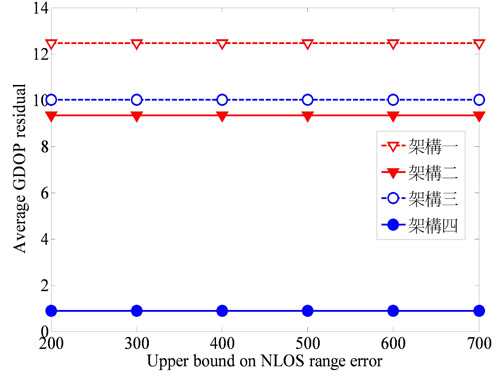 |
| 圖10 三維空間時幾何精度因子差值與非視線誤差大小的變化情形 |
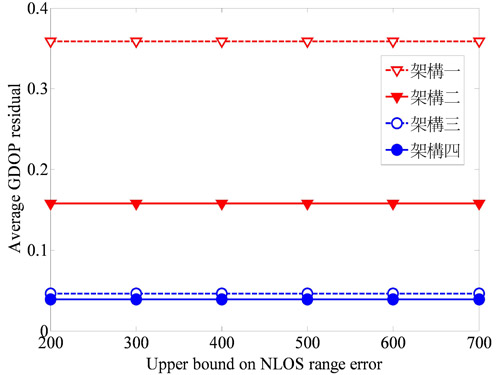 |
| 圖11 二維空間時幾何精度因子差值與非視線誤差大小的變化情形 |
本文模擬結果顯示,使用可變學習率倒傳遞類神經網路能提供更快的收斂速度,並且大幅減少訓練所需的次數。本文提出的架構四只須利用0.5×(p+q)個隱藏層神經元與兩百個訓練次數,其性能表現就會優於其他使用(2p+1)個神經元與兩千次迭代的架構。為減低計算量的負擔,本文建議使用架構四並結合相關參數進行幾何精度因子之估測,就能提供令人滿意的估測效能。
利用反矩陣計算幾何精度因子的方法相當費時,並且會造成計算量的負擔,而最大體積法所選的四個量測單元,並不能保證是最好的。為了消除不好的幾何分布影響並且提高定位精度,本文提出基於可變學習率類神經網路近似幾何精度因子。本文優先選擇提供服務的基地台,再加上任意三個基地台,即可形成擁有四個基地台的子集合,再利用可變學習率類神經網路估測每個子集合的幾何精度因子。接著選出幾何精度因子最小的子集合,最後再利用這些子集合的基地台進行行動位置的估測。
(本文作者依序為台南科技大學資訊管理系助理教授、工研院資通所無線寬頻技術組晶片系統部副工程師)