TWS藍牙耳機經過Apple引領市場,各家晶片廠與耳機廠共同推波助瀾,成功吸引消費者的目光與市場話題,創造龐大商機。本文針對TWS藍牙耳機的麥克風選型與主動式降噪功能進行深入探討。
自從2016年Apple iPhone 7刪除3.5mm插孔,並推出Apple AirPods,這種突破以往機構限制新型態的真無線(TWS)藍牙耳機立刻引爆市場話題,通過藍牙通訊技術形成雙耳獨立的音樂播放裝置,不需要透過音源線連接而消除了不便,讓消費者享受極大的便利性。之後2019年第三代Apple AirPods Pro推出搭載ANC與語音喚醒功能,亦再度成功將TWS耳機市場話題性推向另一個高峰。儘管TWS藍牙耳機仍有進步空間,但這樣極富便利性的產品確實令消費者感到驚艷。
TWS藍牙耳機經過Apple一波又一波引領市場,各家晶片廠與耳機廠共同推波助瀾,成功吸引消費者的目光與市場話題,創造龐大商機。本文即針對TWS藍牙耳機的麥克風選型作一系列探討。
通話麥克風降噪
通話降噪是指TWS藍牙耳機用於通話時,為了讓通話的對方聽得清楚使用者對話而設計。基本原理是把通話麥克風接收到的聲音訊號進行濾波處理,把外界的各類雜音降低,實際上效果一般較為有限。
通話麥克風的主要要求是體積小,低工作電流、低功耗,同時由於在戶外風噪聲不容易以訊號處理的方式克服,因此挑選低頻頻率響應適當衰減的麥克風會有所幫助。
單麥克風降噪
有的TWS藍牙耳機設計了通話以外的麥克風用於收集環境噪聲,稱為收噪麥克風,將通話麥克風收集的訊號,減去收噪麥克風收集的外部噪音,這種降噪效果一般可以比單純的訊號濾波處理要好。
單麥克風降噪的主要要求是頻響與通話麥克風相同,頻域訊號相減可以呈現較正確的結果。
雙麥克風陣列降噪
雙麥克風陣列降噪利用麥克風陣列演算法處理達到指向性收音的效果,抑制所收到的環境音。
為了探究雙麥克風陣列選用麥克風要求,本文實驗麥克風陣列設計的不同參數如何影響系統訊噪比(SNR)。利用整體系統的語音與背景噪音比率來評判,類似於評估麥克風單體的SNR相對於單體語音,系統的背景噪音相對於單體背景噪音,以此定義系統SNR。由於訊號經過麥克風陣列的處理後,對於不同頻率的聲音有不同的結果,因此繪製系統SNR與頻率的關係曲線。實驗的語音平均聲壓60dB SPL,環境雜音平均聲壓50dB SPL。
麥克風要求一:高相位響應一致性
Beamforming演算法的基本原理中,麥克風相位響應一致性占據關鍵要素,因此假設使用麥克風具有較高相位響應一致性可以提高麥克風陣列語音識別可靠度。為了測試這個假設,麥克風陣列系統SNR於兩顆麥克風單體相位在1kHz處差0度、5度、10度、15度的組合下進行測試。圖1顯示相位響應一致性好是對麥克風陣列系統SNR造成正面的影響。若在1kHz已經有相當的相位響應角度差異,在高頻段的部分影響會更加顯著。
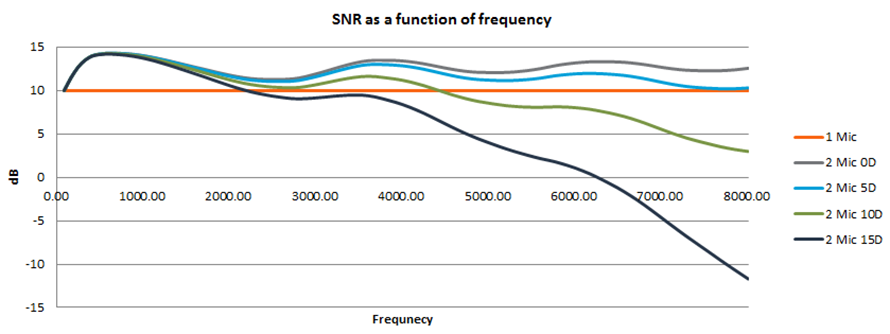 圖1 2顆麥克風相位差對系統SNR的影響
圖1 2顆麥克風相位差對系統SNR的影響
麥克風要求二:高感度一致性
Beamforming演算法的基本原理中,麥克風感度一致性為次要關鍵要素,一般相同型號的麥克風感度通常會因為量產差異而分布在一個範圍±3dB。圖2顯示了麥克風單體感度如何影響雙麥克風陣列的系統SNR。實線表示麥克風單體感度完美感度匹配陣列的結果;虛線表示麥克風單體感度分布±3dB陣列的結果。顯示麥克風陣列使用麥克風單體感度不匹配,亦會對整體系統SNR有明顯的負面影響。
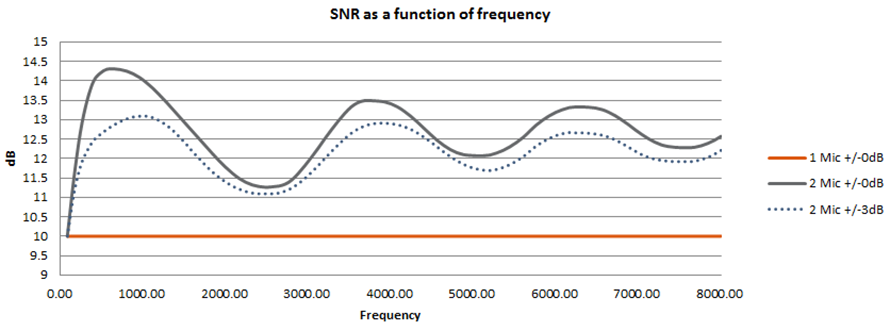 圖2 2顆麥克風感度差對麥克風陣列系統SNR的影響
圖2 2顆麥克風感度差對麥克風陣列系統SNR的影響
單體SNR影響不明顯
開發麥克風陣列應用產品,開發者一般認知提高系統SNR會對語音識別有正面影響,因此假設使用較高SNR的麥克風可以達到這個結果。為了驗證這個假設,使用麥克風陣列系統SNR在麥克風單體SNR 64dB和70dB SNR進行測試,每種類型以雙麥克風的陣列排列。
以系統間SNR相對於頻率的方式來呈現比較結果,軌跡越高的曲線,代表該系統在此頻率區段的表現越好。圖3為麥克風單體SNR對系統SNR的影響圖,實線顯示麥克風單體SNR 64dB陣列的結果;虛線顯示麥克風單體SNR 70dB陣列的結果,使用麥克風單體70dB可將系統SNR提高約0.2dB。但麥克風陣列演算法已將系統環境噪聲降低,系統SNR提高了大約4~7dB,所以麥克風陣列系統再增加約0.2 dB並無明顯的幫助。
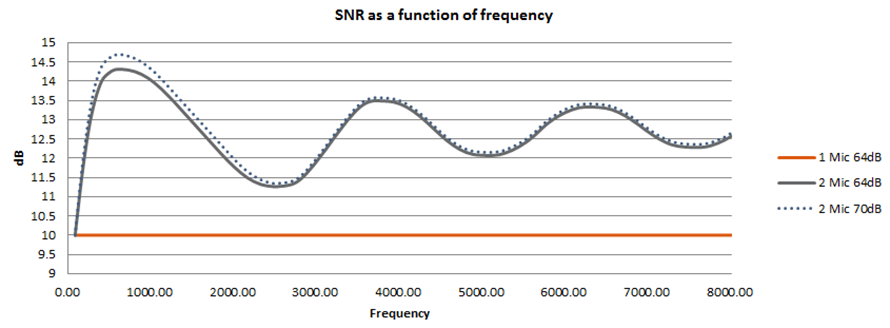 圖3 麥克風單體SNR對系統SNR的影響
圖3 麥克風單體SNR對系統SNR的影響
主動降噪
消費者選擇配戴主動降噪耳機的目的不同,有人是為避免環境噪音影響音質,亦或為避免環境噪音而提高音量傷害耳朵聽力,抑或減少長期置身於充滿噪音環境造成聽力逐漸衰減,這些原因皆會促使主動降噪耳機的市場快速成長。
被動與主動降噪比較
「被動降噪」是指利用物理特性將外部噪音與耳膜隔開,通過隔絕或是吸音材料阻擋噪音,這種方式對500Hz以上的聲音十分有效,一般可使噪音降低大約為15~20dB。被動降噪對於500Hz以下的效果卻不彰,主要原因是低頻聲波有較長的波長,相對高頻聲波較不容易在傳輸的過程中損耗能量或被吸收;若要加強效果必須使用大量的吸音材料而導致體積過於龐大笨重而價格昂貴,不切實際也不符合經濟效益。
被動降噪另一種實現方式為從結構及音場著手,改變噪音傳遞路徑的空間幾何形狀使聲場阻抗改變而減少噪音傳遞的能量,但是設計完成後的降噪系統若需修改造型,則須額外進行聲學模擬工程而墊高費用。一般而言,被動降噪成本低,低頻噪音降噪效果不佳,且由於使用了高密度的隔絕或是吸音材料,耳機較重佩戴不舒服。
主動降噪的基本觀念是聲音在空氣中傳遞,產生一種與噪音頻譜完全相同,相位相反的波形,疊加之後就可將噪音抵消,如(圖4)所示。這種方式首先要檢測外界噪音傳遞波形特點,利用電路產生相位相反的訊號,再通過高還原度喇叭輸出可與噪音相抵消的波形。由於不同的聲波對應不同的反相訊號,在麥克風接受的波形並非簡單的一種波形,每個波形的長短以及振動幅度也有所不同,高頻的波形更短,變化更快,生波傳遞介質來不及動作就被下一段波形所覆蓋,因而較難實現對於1kHz以上頻率的降噪。
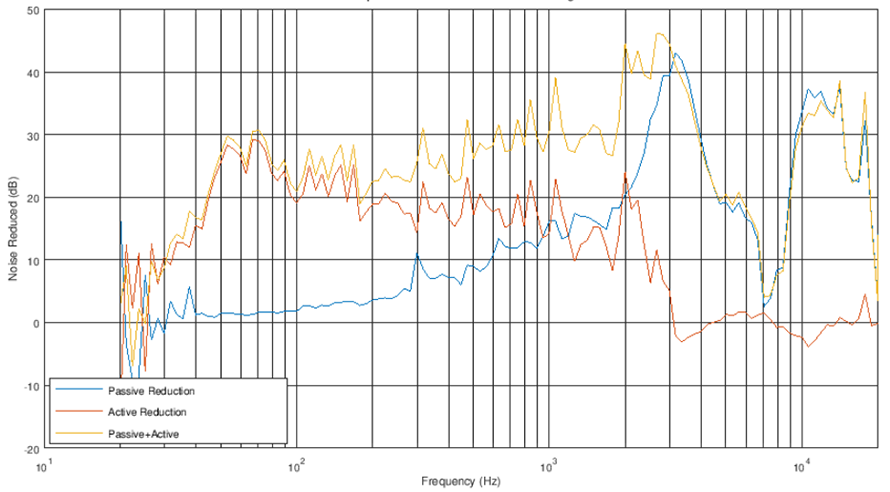 圖4 主動降噪與被動降噪效果與疊合效果分析
圖4 主動降噪與被動降噪效果與疊合效果分析
主動降噪耳機的技術,利用喇叭產生噪音訊號相位相反的訊號來達到降低噪音效果,此種方式具有被動式降噪沒有的優點,包含較好的低頻消噪效果,體積小、價格便宜,更具彈性的設計。
前饋式ANC主動降噪
前饋式ANC結構將收音麥克風暴露在耳機外側的環境噪音中,並與喇叭做物理性的間隔避開,如果喇叭和前饋式ANC麥克風之間的聲學隔離夠好,那麼採用前饋式ANC就不影響播放路徑。採用前饋式ANC結構時,開發者可以對喇叭到人工耳的傳遞響應進行聲學分析,以確定在這種結構下噪音在傳到耳朵時會受到什麼影響。開發者可以為這個環境噪音在此結構的轉換函數,利用麥克風和喇叭之間的應用電路實現。
麥克風要求一:平坦低頻響應
主動降噪麥克風主要用於檢測外界噪音傳遞波形特點,而外界(環境)噪音主要是以50~200Hz居多,若麥克風低頻頻率響應產生衰減,則後級必須使用有限階數的電路或運算資源對其補償,實際上很容易產生有缺陷的頻率響應;若麥克風的低頻頻率響應平坦,則後級不須額外的電路或處理器運算資源在頻率響應的補償上,會實質有效提高降噪效果,如(圖5)所示。
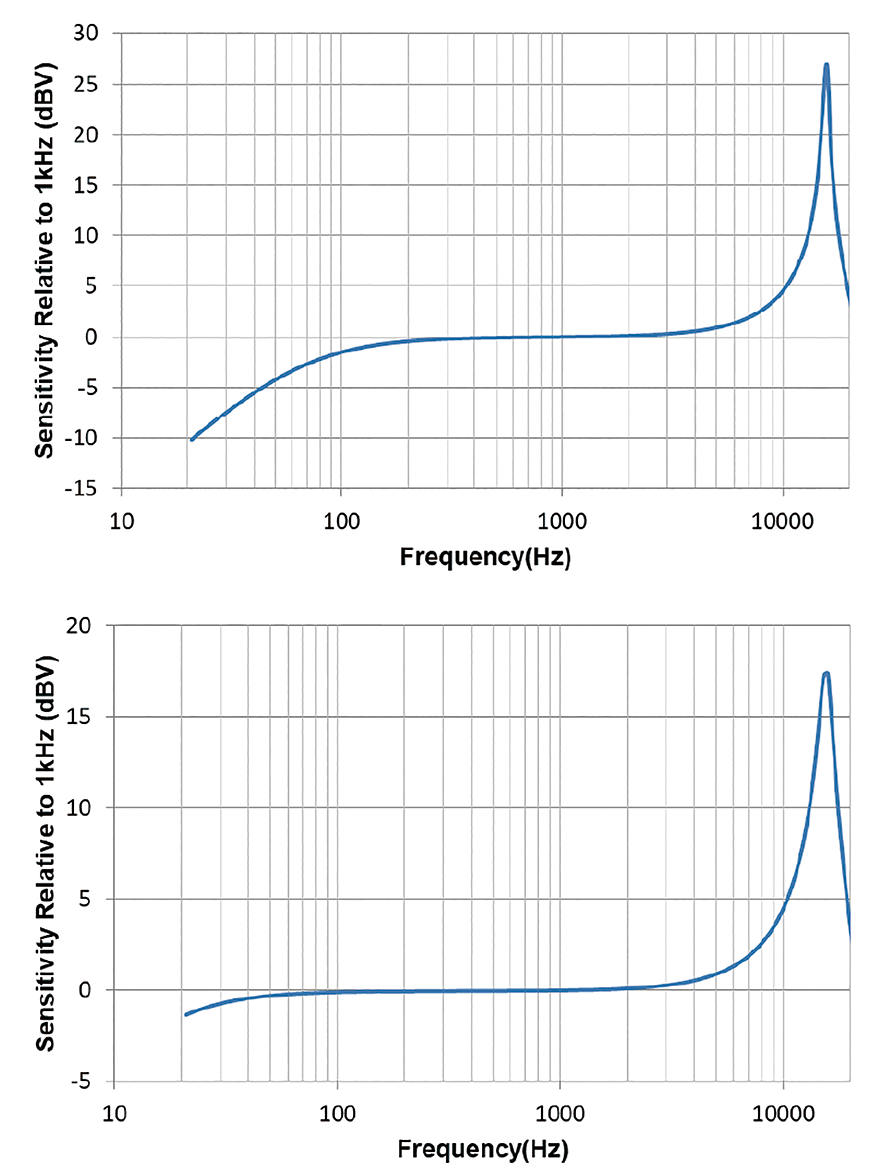 圖5 頻率響應差異比較圖(上圖為一般通話麥克風低頻衰減較多;下圖為前饋式ANC麥克風低頻頻響較為平坦)
圖5 頻率響應差異比較圖(上圖為一般通話麥克風低頻衰減較多;下圖為前饋式ANC麥克風低頻頻響較為平坦)
麥克風要求二:高相位響應一致性
麥克風單體量產的相位響應與感度一致性高(圖6),有助於主動降噪耳機在生產上的良率明顯提升,由於主動降噪耳機的降噪效果是基於理想的麥克風、控制器、喇叭、密閉音腔的總體相位響應與感度所做出的配置,當各項元件量產品的一致性高,整體的降噪效果才能較為一致。
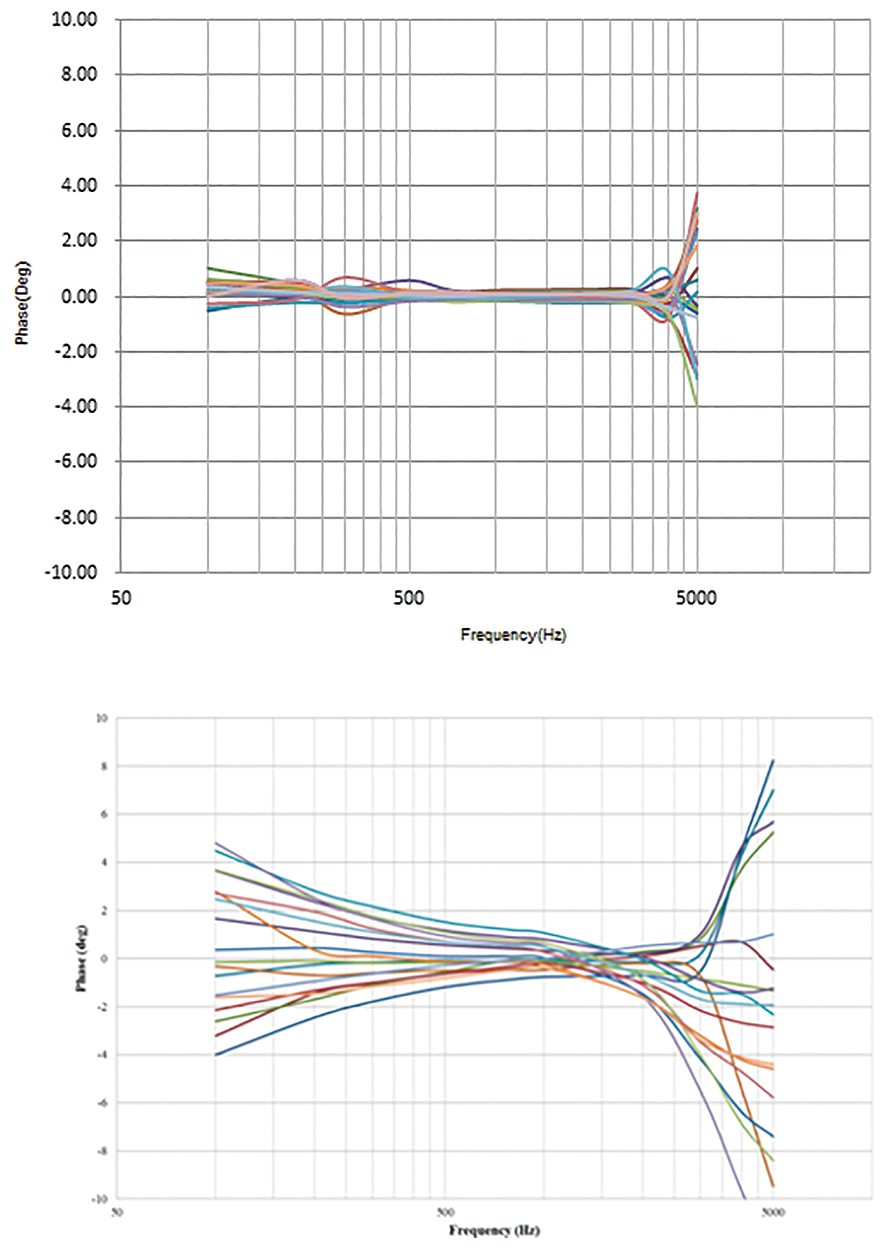 圖6 相位響應差異比較圖(上圖為相位一致性高的麥克風;下圖為相位一致性一般的麥克風)
圖6 相位響應差異比較圖(上圖為相位一致性高的麥克風;下圖為相位一致性一般的麥克風)
後饋式ANC主動降噪
後饋式ANC結構的麥克風位於喇叭與耳膜之間的位置,能處理耳邊的實際噪音,且會對麥克風周圍設計出靜域(Quiet Zone)的區塊,因此麥克風要離耳膜越近,降噪效果越佳;理論上,如果能接收到耳膜的訊號,才有機會做出完美的後饋式ANC結構。麥克風距離喇叭近最大的好處是,系統增益比較高,相對而言比較容易提高麥克風的降噪率,但壞處則是麥克風飽和的風險也比較高。
麥克風要求一:高SNR
由於麥克風是偵測降噪結果靜域的噪聲,需要較高的SNR,以避免麥克風本身的底噪一直被ANC系統認為是降噪結果的誤差而調整輸出波形造成錯誤。
麥克風要求二:高AOP
為了避免麥克風飽和,需要較高聲學過載點(AOP),若AOP不足會在高頻產生諧振,觸碰到原本設計放置在高頻的極點或零點,就可能會造成系統響應發散。
一般耳機揚聲器到耳朵振膜的長度約2.54cm,此耳機含音腔響應的共振點在4kHz的位置,同時考慮使用者在配戴耳機的過程中腔體持續變化,共振點會產生頻率飄移的現象,控制器設計上必須將3kHz以上的響應全部壓掉,因此在濾波器的設計會刻意地安排一個零點在此位置,同時因為濾波器階數的限制,高頻可能也有極點的存在,必須避免諧振產生在此造成系統不穩定,會造成使用者會明顯的不適。
混合式ANC主動降噪
前饋式ANC結構的麥克風在耳機外側,對外部噪音做一檢測,系統輸出一反相波形,目標在耳膜處產生消除噪音的效果,但卻無從得知實際的降噪率;後饋式ANC結構的麥克風在耳機內側,對反相波形輸出的降噪效果作一檢測,可得麥克風周圍的降噪率,卻無法檢測耳膜處的實際降噪效果。前饋式ANC與後饋式ANC結構可以共同搭配設計成混合結構,但是開發上必須共同考量兩種結構的轉換函數關聯性,開發與生產的難度會明顯提高。
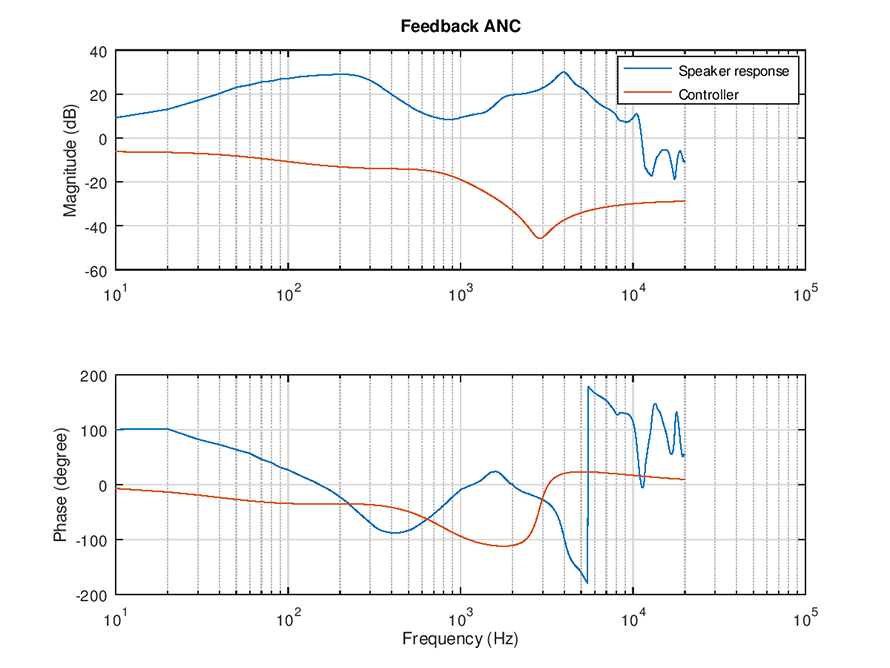 圖7 典型的後饋式ANC的控制器設計
圖7 典型的後饋式ANC的控制器設計
語音喚醒麥克風
TWS藍牙耳機希望能做到更省電,待機狀態時以低功耗模式運作,經喚醒後才以正常模式運作,喚醒功能一般利用加速度感測器或觸控感測器偵測敲擊實現;新式的TWS藍牙耳機則是搭載本地語音喚醒功能,每隔一段時間偵測語音音量與辨識語音喚醒詞,使系統的待機時間更長,節省電池壽命,提升用戶體驗。
TWS藍牙耳機本地語音喚醒的演算法部分由「喚醒詞辨識」及「誤喚醒處理」兩個部分組成。「喚醒詞辨識」需將使用者聲音與背景聲音的訊噪比拉高,以利在不同應用場景讓喚醒詞得到最高喚醒率,系統將聲音訊號存到緩存中進行處理,語音片段從使用者的聲音到達至喚醒詞結束,以此語音片段進行喚醒詞特徵確認。另一方面,「誤喚醒處理」則是必須排除非用戶本人說出喚醒詞後,TWS藍牙耳機做出錯誤的回應。
語音喚醒功能實現平台有不同選擇,一種做法是在TWS藍牙主晶片上執行語音喚醒指令,需要晶片有支援低功耗啟動偵測模式與語音關鍵詞辨識演算法。另一種做法是搭載本地語音喚醒功能的微控制器(MCU),但為了進一步縮減體積,並提升系統設計的便利性,將這顆功能性的微控制器與麥克風封裝在一起成為語音喚醒麥克風。這顆IC除了一般麥克風標準介面外,還必須具備I2C控制介面可對後端系統晶片進行喚醒,以搭配TWS藍牙耳機PCB精簡走線,並對語音喚醒詞與控制指令作客製化開發調適。
總結TWS藍牙耳機的麥克風選型要點於表一,由於各家TWS藍牙主晶片或音頻晶片廠商要求不同,以及麥克風介面數量以及機構設計的限制,需視實際情況進行深度設計考量。
 表1 TWS藍牙耳機的麥克風選型要點
表1 TWS藍牙耳機的麥克風選型要點
(本文作者為鑫創科技市場行銷二處技術經理)