人工智慧(AI)與機器學習(ML)已在商業市場愈來愈受到歡迎。根據GigaOm的《AI at the Edge:A GigaOm Research Byte》報告,過去6年間應用在最大型的AI訓練模型上的運算,平均每100天就增加一倍,而這也讓AI運算增加三十萬倍。
這些以及其他的AI頭條新聞,在工程與開發人員社群中促成狂熱的發展,而個人與企業也競相推出可以讓生活與企業改觀的AI產品與服務。不過,在這波成長熱潮中,設計團隊面臨許多可能的設計方式,這主要是圍繞在運行AI工作負載所需之處理器的選擇,以及不同處理器技術的組合。本文的目的在於解開其中某些技術糾結點,並針對如何才能設計出以實用性、效能與成本為優先考量的AI運算,提供指引。
運算從傳統雲端移出 資料搜集處就近處理
到目前為止,ML相關的焦點都聚集在雲端,以及大型集中式的運算農場。不過,ML運算已經逐漸從傳統雲端移出,朝向較接近資料搜集處移動。其原因包括效率、速度、隱私與保全。此一方式隨著如自駕車、醫療保健、智慧城市與工業物聯網(IIoT)等領域的全新聯網裝置的崛起,正在加速發展中。一如最近一篇PCmag的文章指出:「當雲端陷入困境,前來解套的是終端運算與AI。」
為全球資料網路創造出更多智慧的舉動,可以驗證AI運算民主化的活動,特別是愈來愈多的終端伺服器持續出貨。的確,AI運算是諸如亞馬遜(Amazon Web Services)等公司目前採用的安謀國際(Arm)Neoverse產品系列技術的關鍵焦點。根據研調公司Gartner首席研究分析師Santhosh Rao表示,由企業產出的資料,目前有接近一成在傳統集中式資料中心或雲端以外處理。Gartner預測來到2022年,這個數字將提升至50%。
目前要可靠地估算有多少的AI運算是在終端伺服器內進行,仍然言之過早,不過終端裝置這部分,卻已有頗為有力的數據。從國際數據資訊(IDC)看到的資料顯示,2017年有3.24億個終端裝置使用某種形式的AI(推論與訓練)。其中有三分之二是終端運算系統,如物聯網(IoT)應用,另外三分之一則是行動裝置(圖1)。
 圖1 終端運算、行動裝置使用AI運算比例
圖1 終端運算、行動裝置使用AI運算比例
在雲端之外,絕大多數的AI運算成長出現在推論,以及真實世界資料與訓練用AI模型的比對。來到2020年,IDC預測進行推論的終端與行動裝置加起來總數將達到37億,另外還有1.16億個裝置則負責進行訓練。
GigaOm的研究簡要地總結此一演變:「你應該在哪裡進行推論的計算?答案簡單來說,對於許多(即便不是大多數)應用,未來推論將會在(裝置)終端進行;也就是說,在資料搜集的地方。這對於ML未來要如何發展,將產生巨大的衝擊。」
科技發展改變歷史 AI/ML終究推向終端
有幾股趨勢正在把AI與ML推向終端,並帶動科技達到許多人期待的規模與轉型之影響力。
首先是資料本身性質的改變。終端聯網裝置數目的爆炸性成長,特別是在IoT應用,為這個由AI驅動的世界,產生好幾ZB(Zettabytes)的新資料。這個世界並沒有足夠的頻寬,可以支援將所有的資料傳送至伺服器進行處理。這意謂基於終端的AI不是選項,而是必須。例如,Google曾說如果全世界的每一個人每天使用3分鐘的Google語音助理,該公司必須加倍目前所擁有的運算伺服器數量才夠。
此外,還要考量可靠性。傳統雲端運算模式為系統帶來的延遲(Latency),對於許多終端應用行不通,如自駕車。把車輛資料送至雲端再傳回來根本沒有效率,因此儘可能地進行最多的機上處理,是絕對必要的。
與此相關的是電力。需要電力才能把資料送至雲端並傳回來;運算中心內要運算資料,也需要相當多的電力。
另一個愈來愈具影響力的趨勢,則是隱私。今日的消費者對於傳送至雲端的個人資料,愈來愈為敏感。
連接也扮演相當的角色。儘管大多數為智慧手機的數十億個裝置都能運行AI應用程式,但它們大多數都必須仰賴網路連接,這可能會潛在限制它們的用途。
中央處理器依舊給力 補足終端AI運算拼圖
在這些AI的科技力量中,還有進一步的因素。更明確地說,工程師與開發人員必須處理可能決定他們的AI專案在商業市場是成功或失敗的衝突資訊。也就是說,哪個處理器技術最適合這些AI工作負載?答案是已經成為AI運算且擔負重任的預設處理器:中央處理器(CPU)。CPU對於所有AI系統都是核心,不管是負責處理整個AI,或是針對某些任務與繪圖處理器(GPU)或神經網路處理器(NPU)等輔助處理器共同合作。
也因此,針對ML工作負載,CPU仍將扮演吃重的角色,原因是它受益於行動運算革命中多年來所建立的共用軟體與編程架構。另外,在透過共用與開放軟體介面利用各種加速器的複雜系統,它也扮演極為重要的任務管制角色。
的確,臉書(Facebook)研究人員報告指出就臉書的App而言,目前大多數的推論已經在行動裝置CPU的終端進行,而大多數是在好幾年前推出的處理器上進行運算。該研究作者寫道:「系統的多元化,讓把編碼移植至如DSP等輔助處理器這件事,變得相當具有挑戰性。我們發現提供可供所有處理環境使用的一般與演算法層級的優化,更為有效。」
為了測試那種想法,Arm委託進行了一個研究,針對全球Arm生態系統的AI產品設計人員進行調查。他們由目前使用AI科技的所有產業中抽選,其中包括IoT(54%的受訪者)、工業(27%)、汽車(25%)與行動運算(16%),調查的結果勾勒出相當清晰的圖像。
如圖2所示,近350位受訪者中有超過四成表示,他們進行大多數的AI運算,都使用CPU。有四分之一使用GPU,其他則使用FPGA(12%)、專用ML處理器(8.6%),或數位訊號處理器(DSP)(7.5%)。
 圖2 AI運算使用CPU、GPU、FPGA、專用ML處理器、DSP比較分析。
圖2 AI運算使用CPU、GPU、FPGA、專用ML處理器、DSP比較分析。
智慧型手機不可小覷 榮膺ML轉型力代表
由於開發人員與工程師已從行動運算生態系統崛起中,學到教訓並加以調適,CPU已成為AI與ML大為仰賴的解決方案。行動運算之所以如此快速且大量地擴大規模,正因為它具有CPU這個定錨點,可以處理任何的運算工作負載。另外,建構在基本的CPU上的韌體與軟體,則促成數百萬個產品與App的崛起。
此一歷史傳統,讓智慧型手機成為史上第一個可以運行AI與ML的行動裝置,特別是推論。此種裝置結合效率、可攜性、成本、電力消耗與網路安全,這些都是讓AI運算普及極大化的關鍵因素。
AI運算任務管制 分清楚各類處理器
很快地,帶大家了解中央處理器(CPU)、圖形處理器(GPU)與神經網路處理器(NPU)針對AI在運算上的差別。
CPU主要的優點,在於它已經處於系統的中心,而且不管是今日或未來,都是唯一運行任何類型的ML工作負載都具有足夠彈性的處理器。此外,它可以輕易地擴展規模,並支援任何編程框架或語言,包括C/C++、Scala、Java、Python與許多其他語言。它常在雲端使用,進行AI的推論(比對模型與真實世界資料),同時也是終端裝置AI唯一無所不在的解決方案。CPU極為適合運行複雜的工作負載,並且即便是在IoT與行動運算領域中的AI訂製設計,也是常使用的首選AI處理器。
與CPU相比,GPU是更為複雜的專用處理器,並提供更特定的功能性。它的設計用意通常只用來支援圖形或少量高度平行或固定的工作負載,例如處理影像畫素或影片。GPU的編程使用相對較少的語言,因此與CPU相比,提供的彈性較為受限。今日的AI應用裡,它被用在如自駕原型車與伺服器的訓練。
更專門且超高效率AI運算的需求,導致具高度任務特定性的NPU的設計。NPU為了快速執行AI應用,從頭開始設計,而且執行ML工作負載常見的高密度向量與矩陣運算速度飛快。不過與CPU及GPU相比,NPU較不具彈性。它必須與CPU一併使用,以處理一般的運算功能。
另一個在CPU運行AI工作負載的原因,則在於處理器的歷史:CPU長期以來一直執行與管理系統與應用軟體。在這個系統複雜性與日俱增的年代,此一歷史傳統與熟悉性,對於永遠必須考量產品上市時間的設計人員而言,是極為強大的誘惑。
今日,CPU用在優化的ML與ML相關的任務,包含:
當網路連接斷斷續續或無法連線時,機器人與家用裝置可以使用NLP來辨識要求,特別是複雜或複合的語句。
系統可管理公共區域的出入或記錄會議的參與者,同時把資料保存在本地,以維護隱私。
對於有線或移動較慢的系統(非快速移動的車輛或無人機),CPU通常已經足夠運行SLAM功能。
完整解決方案護持 加快軟體設計腳步
不管設計人員想要創造哪一種AI系統,都必須想到那些想要為更多產品撰寫軟體的開發人員。可以做到這一點的解決方案,已經浮上檯面。例如Arm NN對於在省電、基於Arm的平台上建立與運行ML應用,更為簡易。
開放原始碼的Arm NN軟體與Arm Compute Library(圖3),在既有的神經網路框架(例如TensorFlow或Caffe)與其下的處理硬體(如CPU、GPU或任何Arm機器學習處理器)之間,提供一座溝通的橋樑。
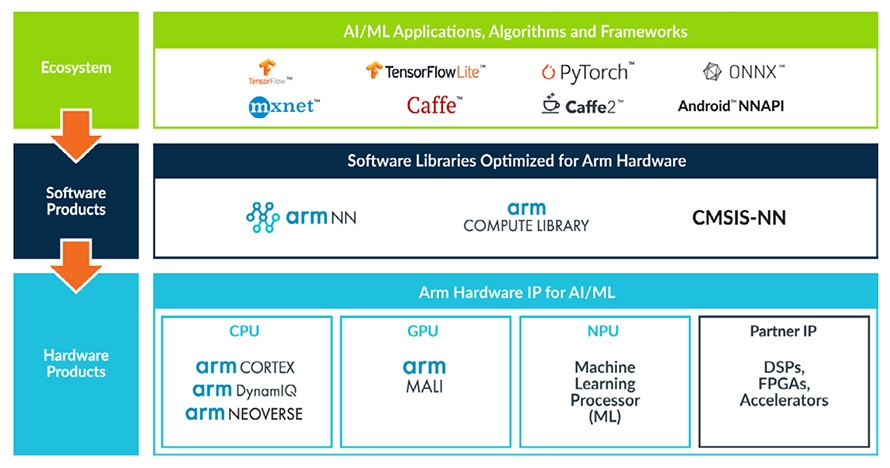 圖3 Arm NN軟體、Arm Compute Library示意圖
圖3 Arm NN軟體、Arm Compute Library示意圖
今日CPU雖然已是ML工作負載的首選,它在即將到來的異質運算、加速器強化系統的世界中,仍然會是壓軸的技術,部分原因是ML工作負載的性質所致。通常會把ML視為運算的「突波(Burst)」,先交給CPU設定處理,然後由CPU完成,或卸載至NPU或GPU。
拜MCU進步所賜 小型機器學習崛起
所謂的小型機器學習(Tiny ML)成長領域已經是主要的擴展區,主要原因是IoT世界裡常見的成本與電力上的限制。拜微控制器(MCU)功能持續進步之賜,現在可以看到許多ML與其相關的任務,例如:
MCU可以調整運作點、將任務重新指定給不同的核心,並依據效率平衡流量。
系統可以藉觀察正常的型態來監控自己的行為,並快速找出異常情況。
系統在進行複雜動作,例如為某個裝置開鎖或拍照,可以開啟低電力模式,不會過度耗損電池電力。
正常運作情況下,系統會對關鍵字或片語做出回應。
ML相關應用 今日俯拾皆是
CPU與MCU的AI技術能力,已經對智慧型手機與終端裝置的設計選擇,造成影響。ML工作負載經常使用於臉部與指紋辨識,甚至是醫療診斷。這也衍生出新的產品與功能等級,例如智慧氣喘呼吸器、臉部辨識與人臉解鎖能力、喚醒與語音感測,以及更多:
MCU上的彈性終端ML
研究顯示儘管記憶體與運算限制,許多設計仍然在MCU上部署複雜的神經網路。諸如修剪與量化等技術,可為MCU上的部署壓縮模型,並且針對CPU、NPU與GPU都能派上同樣的用場。
神經網路經過一段時間後,也必須安全地進行更新,這通常會從遠端進行。位於聖荷西(San Jose)、奧斯丁(Austin)與台灣的Arm工程師團隊,從雲端對部署於MCU的神經網路,展示規模可擴展且安全的遠端更新。該系統使用Google TensorFlow、可在Mbed作業系統上運作、運行時脈為100Mhz的Arm Cortex-M4,以及Arm Pelion裝置管理平台,進行更新。
呼吸更加輕鬆
Amiko Respiro裝置提供智慧吸入器技術,協助氣喘病患呼吸更為輕鬆。位於Respiro感測模組的核心,就是超低電力的Arm Cortex-M處理器。這個解決方案使用ML解譯來自吸入器的振動資料。感測器經過訓練後,可辨識病人的呼吸形態與吸氣時間。處理器讓Respiro裝置可運行即時的ML演算,而且可在感測器模組內部自行辨識行為模式並解譯資料。當使用者按下扣板,模組立即辨識呼吸資料形態,並提供快速、私密的使用者回饋。
臉部辨識
Arm的一支團隊開發出一套概念證實可行的系統,以便運行人臉驗證。在Arm Cortex-M微處理器上處理的低解析圖像啟動整套系統,而系統也跟著觸發高解析照相機。臉部偵測與反詐騙運作則在Arm Cortex-A CPU上進行,並使用Arm Compute Library函式庫支援的低階與優化軟體功能。
ADAS與視覺系統
2019年的國際消費性電子展(CES)中,總部位於以色列的Brodmann17公司展示其先進駕駛輔助系統(ADAS)解決方案:這是一套深度學習(Deep Learning)的視覺軟體解決方案,運行時只需要目前所需運算能力的一小部分,但卻能達成ADAS系統與自駕車輛記錄到的最高精準度。這套ADAS系統利用Arm Cortex-A72進行運作,雖然只用上單一核心,卻能同時保有高效能與精準度。
ML開發的生態系統
這些以及其他靠CPU與MCU驅動的AI終端部署,受惠於欣欣向榮的設計與開發生態系統得以實現,該系統的觸角已從智慧型手機的設計與App的開發,擴展至ML。試著思考Arm的Project Trillium,此晶片平台在所有可編程的Arm IP與夥伴IP,都針對ML工作負載提供彈性支援。它可以與現行的神經網路框架,如TensorFlow、Caffe與Android NN進行無縫整合,同時也獲得生氣盎然且多元的生態系統支援,進而帶動創新與選擇。
驅動行動CPU無所不在以及以它為中心不停創新的特性,在ML應用方面將持續支撐此類CPU的中堅角色。在考量微架構的強化後,這一點尤為真切。
微架構強化為未來Arm Cortex-A應用處理器與Cortex-M裝置的AI能力,帶來根本的轉變。例如,Cortex-A與Mali圖形處理器中新的專用處理器指令,用意在提升AI效能;Arm架構與微架構的持續創新與演進,包括支援較新的資料類型、延伸與更快的向量處理,同時支援個人電腦(PC)/雲端以及終端運算;在Armv8.1-M架構問世當下同時推出的Helium,是針對Cortex-M架構推出的全新優化的向量架構,可為AI提供最多達十五倍的效能提升。
CPU為啟動核心 混合AI加快邁進
隨著Arm持續演進其GPU與NPU技術,AI與ML的設計將進一步獲得助益。這些硬體的創新加上Arm的軟體解決方案,為建構顛覆的AI與ML產品及服務的開發人員,提供強而有力的選項。
終端是下一階段AI技術演變發生之處。經濟考量與單單頻寬方面的限制,意謂把資料傳至雲端以取得AI實現的決定,並不合理。此外,發展過程會追蹤行動運算的演變,並利用標準化的方式、軟體、工具架構,以及可快速提供可靠、強力且高效系統的生態系統。
即便創新公司持續開發專門解決方案,以優化基於雲端或終端系統的AI/ML專案,CPU與MCU仍將保有其顯著超群的地位。再加上異質化的系統會更仰賴CPU進行任務管制,同時賦予增加處理器的能力,以應付特定任務的工作負載。
在CPU成為主要的AI運算的程式設計目標後,開發人員就能將編碼聚焦在會出現於所有基於ML系統的這個處理器上。
CPU雖然是AI任務管制自然且強力的選擇,但已經看到全新混合處理環境的崛起,在其間CPU利用NPU、GPU、視覺處理器(VPU)與深度學習處理器(DPU)等協同處理器,進行特定的工作負載任務。
事實上,Arm AI調查中有近三分之一的受訪者表示,針對未來的專案,他們想要利用如NPU等專屬ML裝置,成為主要的ML引擎。Arm針對NPU與GPU的開發持續進行大量投資,以迎合AI開發社群的多元需求。
這些以CPU為中心的混合AI環境,會將資料的能力拉高至更高的水準,同時帶領邁向比今日更為遠大的運算可能性、行動與洞見。但隨者AI對資料處理能力提升的同時,網路安全的威脅也隨之升高,因此好好利用鑽研達數十年的CPU安全能力,極其重要。
對於想要構建一套以AI運算為基礎的系統的設計人員,這份報告點出了一條合情合理的考量之道,同時也提供現今AI開發人員已經著手進行的相關洞見。
簡單地說,CPU比起以往對於AI應用更具能力,因此針對AI任務管制,請把系統的焦點擺在CPU。它會為系統帶來所有大眾市場產品所需的效能、安全性與成本效益。在此同時,須考量需求的平衡,並將目光放在合理的混合系統。
(本文作者Rene Haas為Arm IP產品事業群總裁、Jem Davies為Arm院士、副總裁暨機器學習事業部總經理)