在維持體態的待辦事項中,鍛練體能有多重要呢?有沒有想過自己每週花了多少時間走路或跑步?研究顯示,將近20%的成人開始使用科技產品來追蹤他們的活動,並藉由下載這些「自我量化」的應用程式(App),從分析每日的活動來了解自己。
本文將說明如何利用Android裝置結合MATLAB的統計與機器學習工具箱(Statistics and Machine Learning Toolbox)所提供的機器學習(Machine Learning)演算法來即時偵測人類的活動型態。
以下是實驗中所使用到的幾個元件,包括一台用來執行MATLAB的電腦(實驗所使用的MATLAB版本為R2014b),並安裝MATLAB支援套裝軟體(MATLAB Support Package),之後選擇支援的硬體,包括Android感測器以及統計與機器學習工具箱。
另外,還必須有事先安裝MATLAB Mobile App的Android智慧型手機,以及具備手機無線區域網路(Wi-Fi)或行動上網功能。這裡將利用MATLAB Connector將Android裝置連接到電腦。
當看著即使是從未見過的人,一般人還是可以輕易地分辨他當下正在做什麼活動。這是因為人的大腦已經受過訓練,可以快速了解人類的活動。在看到活動進行時,大腦會將接收到的活動與記憶裡成千上萬的活動資料進行比對,從中找出相符的活動。同樣地,也可以訓練電腦(或手機)依照制定的辨識活動規則來辨識目前所從事的活動。
MATLAB機器學習 分三階段學習偵測活動
在電腦上,機器學習演算法可以用來「學習」人類活動,並從一些收集的新資料中偵測出活動。像這樣的偵測任務,牽涉到將數據資料分成各個類別(Classes),稱之為分類(Classification)。另一種關於分類的例子是,如依照特定的症狀描述來診斷病患也是分類。
分類演算法的執行通常有訓練(Training)與偵測(Detection)兩步驟。在訓練階段,會建立一個模型,把即將要訓練的數據資料映射套用到特定類別。而偵測階段,則是將新數據資料映射套進某個分類。
這裡使用Android手機內的加速感測器(Acceleration Sensor, Accelerometer)來幫助辨識當下正在從事的活動。並選擇最近鄰居法(K-Nearest Neighbor, KNN)分類器,這是最適合目前應用的演算法,因為它可以快速地偵測每一個活動,並且對低維度的數據資料(僅有部分特徵)的處理有很高的準確度。它藉由讓訓練資料集中最鄰近的K個鄰居以「多數表決」的方式來決定新進資料點的所屬類別。
偵測活動的過程將會透過以下三個階段執行:
從Android手機加速度感測器收集三維(3D)的加速資料。
從加速器收集來的資料中把每一種想要偵測的活動的獨特特徵加以定義,並萃取出來。
利用萃取的各種活動特徵來訓練分類器(Classifier)。這個分類器接著會用來對新的加速度感測器資料辨識活動。
利用加速度感測器 收集三維加速資料
在分類器開始偵測之前,必須先以一組已知的資料點來進行訓練,讓該分類器能夠運作。手機上的MATLAB Mobile應用程式,可透過MATLAB支援套裝軟體內針對Android感測器的支援(MATLAB Support Package for Android Sensors),就能把手機當成感測器,透過手機裝置內的加速度感測器收集資料,並且收到的量測值傳送到電腦的MATLAB。
一旦與Android裝置連結完成,以mobiledev物件為例來記錄從裝置傳送出去的感測器資料。接下來,啟用裝置上的加速度感測器,開始透過MATLAB登錄量測值(圖1)。
 |
| 圖1 啟用加速度感測器,透過MATLAB登錄量測值。 |
下最終指令之後的前10秒鐘先不動,處在閒置狀態。接下來,站起來步行70秒鐘。到達樓梯間時,走下樓,然後再全力衝刺約60秒。接著再步行70秒,爬上樓,走回辦公室。隨後,坐下來並維持閒置狀態直到實驗結束。取得了三維的加速器記錄資料,並將資料視覺化(圖2)。
圖2是所進行的活動的三個維度的加速度感測器資料,包括閒置、步行、跑步、爬上樓、走下樓。僅由圖2並不能分別辨識出上述活動,因此須定義出可以幫助辨識每一種活動的特徵,並與其他活動做區別。
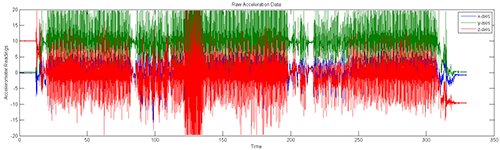 |
| 圖2 將取得的加速器紀錄資料視覺化 |
分析收集而來資料 萃取活動獨特特徵
雖然每一個活動的原始加速度感測器資料從時域(Time Domain)的角度看起來都很相像,資料還是包含了可以用來區分不同活動的獨特特性。例如所有資料點中的最大值或特定門檻之上的資料點數量,把這些特性稱為特徵(Feature)。擁有這些特徵,就可以區別活動,並進行分類。
可以考慮幾種特徵,例如平均值、標準差、中位數、變異數、最大值、最小值、頻率的組成幅度(Magnitude of Frequency Component)等等。然而,如果要有效率地執行特徵萃取,必須找出可以用來區分不同活動,卻不會耗費太多資源的最小的特徵集。
在幾個不同的特徵之中,找到以下六個最合適的特徵:Feature_1表示幅度資料(Magnitude Data)的平均值、Feature_2代表25百分位數以下幅度資料的平方和、Feature_3為75百分位數以下幅度資料的平方和、Feature_4表示y軸資料小於5Hz之頻譜的峰值頻率、Feature_5表示y軸資料小於5Hz之頻譜的峰數、Feature_6代表y軸從0到5Hz的資料積分。
請注意幅度資料為y軸與z軸加速讀數總和的平方根。可以放心忽略x軸讀數,因為該讀數並不隨著活動不同而有所改變,原因是手機一直以相同方向被放置在口袋內。
從每個活動挑出有記錄價值的5秒鐘來萃取出這六項特徵。將播放的視窗長度定為5秒鐘是因為這已經足夠提供連貫且穩定的特徵來進行偵測。可以調整視窗長度,但記得避免過長的視窗(例如1分鐘),因為活動非常有可能在這段時間內改變。
在計算出各個活動的上述六個特徵值後,作為訓練過程執行的一部分,將兩種輸入值餵給訓練演算法,分別是特徵值及適當的回應(也就是活動的特徵標誌)。以下特徵變量是從跑步時的三個維度加速度感測器原始資料計算出的上述六個特徵值,例如:
在這裡,特徵變量為[Feature_1, Feature_2, Feature_3, Feature_4, Feature_5, Feature_6]。每一個成對的(feature, activity)組成一個訓練資料點。每個活動原始的加速度感測器資料都被存在一個MAT檔。把每個活動之間的輸入提醒加進來,以避免在轉換期間收集資料,這可以確保每一個活動原始資料在特徵萃取時是乾淨、連貫的。
請注意,原始的加速度感測器資料是以200Hz取樣,但因為Android手機運作的方式,實際上可能更少。除此之外,取樣頻率可能隨著測量期間有所變動,使得資料取樣並不均勻。為處理這些不均勻的取樣資料,將執行一個再取樣演算法。這可以讓特徵辨識更精確、分類結果更佳。圖3中標註x的紅線代表非均勻取樣的原始y軸加速度感測器資料,標註o的藍線代表再取樣資料。
 |
| 圖3 非均勻取樣的原始y軸加速度感測器資料以及再取樣資料比對 |
上述特徵的前三項都屬於時域,而其他三項則屬於頻域(Frequency Domain)。從圖4可以很清楚地看出不同活動叢集的特徵(例如圖中所有的紅點都屬於跑步Running的特徵)。從這些特徵的特性(各活動獨特的群集)可以準確地辨識新資料的活動。
 |
| 圖4 不同活動叢集的特徵比較 |
利用特徵訓練分類器 針對新資料辨識活動
基本上,一個訓練演算法需要大量訓練資料點來建立一個可靠的偵測模型。因此,從每一個活動各收集超過一千筆訓練資料點來進行分類訓練。
一開始,把特徵依以下順序組合成一個陣列,依序為步行(featureWalk)、跑步(featureRun)、閒置(featureIdle)、爬上樓(featureUp)、走下樓(featureDown):
在上面這行程式碼,featureWalk是一個以步行時收集的原始加速度感測器資料計算出的六個特徵值組成的1000x6陣列。同樣地,featureRun是以在跑步時所收集的原始加速度感測器資料計算出的六個特徵值組成的1000x6陣列,以此類推。
當所有的特徵資料都已放進這個資料陣列,會發現對應到跑步特徵的資料範圍大過對應到閒置或步行狀態下的特徵的資料範圍。這對存在於不同活動的特徵形成偏差,也影響演算法準確偵測可能存在於不同範圍的新進資料所表現之活動的能力。因此,將資料值標準化,讓資料值範圍侷限在[0,1]之間。
圖5說明由各活動計算出的原始Feature_1值,以及標準化後的版本。如圖5所示,經過標準化後,Feature_1的值會介於[0,1]之間。其他五項特徵也會以同樣的動作進行。
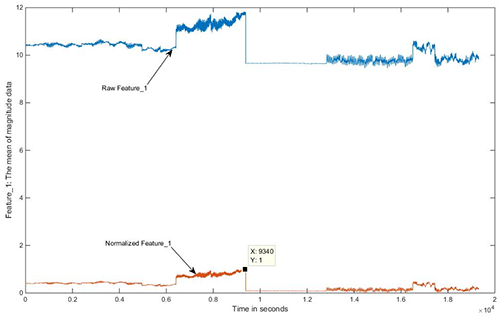 |
| 圖5 各活動計算出的原始Feature_1值以及標準化後的版本 |
當資料已經常態化(Normalized)完成、能被使用,必須定義機器學習演算法在收到做為輸入資料的資料陣列時該如何輸出資料作為回應。輸入資料及輸出反應接著會被用來教導機器演算法如何將新資料分類。
為了建立輸出回應向量,開始指派整數至每一個活動,-1、0、1、2、3分別代表走下樓梯、閒置、爬上樓梯、步行及跑步。因為每一個特徵集的輸入都需要有一個回應,所以建立了每個活動的訓練特徵資料點長度行向量(包含這些整數)做為回應向量。
為了讓這些偵測到的活動可以更容易讓人讀取,把回應向量轉換為一個包含「走下樓梯」、「閒置」、「爬上樓梯」、「步行」、「跑步」以及「轉換」等字樣的分類陣列(Categorical Array):
產生上述回應陣列後,接著訓練KNN演算法來得到一個模型。在這裡,使用統計與機器學習工具箱中的FITCKNN函式。經過幾次嘗試,選擇K('NumNeighbors' property)等於30,因為這讓偵測結果有必要的水準表現及準確度:
利用訓練資料產生模型後,想要把它用在手機的新進資料來驗證其在活動偵測的有效性,藉此證明模型的有效性。因此,使用稱作extraFeature的特製MATLAB函式來計算這六項特徵。計算出來的特徵(儲存於newFeature變量)接著會跟模型一同偵測執行的活動:
訓練這個模型來區分五種活動。問題是如果實際執行的活動並不在這五種活動範圍之內呢?偵測器還是會在目前的視窗評估該活動,並認定與五個活動的相似指數都較低。低相似指數的情況在活動與活動的轉換期間一樣會發生,這時候偵測視窗會拒絕預測器。
所以,與其讓測試結果出現低配對指數,不如設計讓預測器在與每一類活動的相似指數都在95%以下時,將預測結果顯示為「轉換」。這項規則在處於兩個可辨識的活動之間的轉換時同樣適用,像是從步行到跑步,因為在一些轉換期間的連貫視窗的特徵通常不太穩定。
圖6為從手機收集來大約1分鐘的原始資料以及偵測出的活動。為了讓偵測的活動更容易閱讀,將偵測出的活動畫在圖的下方,並分別以符號表示:P代表轉換,x代表步行,△代表上樓,*代表跑步,▽表示下樓,o則是閒置。
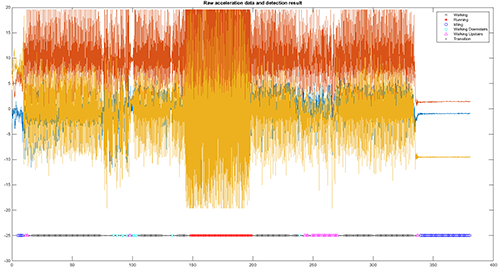 |
| 圖6 從手機收集1分鐘內的原始資料以及偵測到的活動 |
這個機器學習演算法是筆者利用自己從事各種活動的原始加速度感測器資料。如果其他人想要利用這裡的資料訓練之演算法來偵測從手機收集的加速度感測器資料的活動,演算法可能變得非常不準確,即使都使用同一支手機,並且一樣把手機都放在褲子前側口袋,還是會出現這樣的情形,這是人與人的步態可能不太相同的原因,所測量到的感測器數據也可能取決於個人的身高、體重,以及手機與地面的距離。
為了建立能夠準確偵測出個人活動的偵測器,建議從手機的多個加速度感測器收集每一種活動的資料集開始。接下來,以extractTrainingFeatures MATLAB函式萃取每一個活動資料集的上述六項特徵,當把訓練資料的特徵萃取出來,接著就利用這套資料來訓練機器學習演算法。最後,使用演算法來偵測進行的新活動。
在這裡,僅簡單描繪初步的可能性,這項應用也可以套用到其他的偵測系統,包含車輛(腳踏車或汽車)甚至是機器人。除了加速度感測器外,還有更多類型的感測器如全球衛星定位系統(GPS)、陀螺儀、或磁力計等等,也都可以被使用在建立動態追蹤應用上。
(本文作者任職於MathWorks)