隨著先進駕駛輔助系統(ADAS)系統普遍應用於高級車輛上,帶給人們對駕駛安全、舒適、方便與節能等不同於過往的經驗,基於這些現有的技術能量與背景,多種感測器應用技術探索已成為主流並進一步應用於熱門的自動駕駛技術之中。
光達感測器為目前發展自動駕駛技術領域中最為重要的回授單元,相較於其它感測器,能正確地輸出目標物體的位置所在,成為自動駕駛等級SAE Level 5的基礎元件。透過先進的光達感測器與機器學習軟體演算法的處理,可以使車輛模擬人類各種感官能力(Perception),且優於人類在物件辨識上的測距準確性,其可靠與穩定的同步即時全方位環周感知能力,成為車輛行為控制決策判斷的依據。
光達感測器的物件辨識穩定性研究為目前自動駕駛技術的關鍵項目之一,在運算速度、抗環境干擾能力與辨識精準度上為目前該技術發展的三個重要指標。
自駕車光達物件偵測技術
光達是一種主動式光學感測器,透過雷射光束撞擊至待測點後反射回感測器之光束飛行時間,可計算獲得與待測物之相對距離,並依照連續多個距離資料的多寡可換算為2D或3D之物理座標,雷射光束常見的有紫外光、可見光以及紅外光,其中以波長600~1,000nm最為普遍應用,目前市面上較常見的有2D與3D感測器產品,並依照雷射收發器之運動狀態分為固態式與旋轉式,其中3D又依雷射光束的數量普遍分為1、8、16、32、64、128 Beam,並同時進行環周360度高頻掃描,為目前自動駕駛常使用的解決方案,如LeddarTech的固態LiDAR、Quanergy、Velodyne與Ouster的車用360度掃描LiDAR、Bosch的部分空間掃描3D LiDAR等,都是目前在車用領域上常見的產品,然而這些產品目前在感測資訊安全上還需完整的防駭驗證以避免遭到惡意性的偽造光學攻擊。
相較於其它種類的感測器,光達目前在價格上目前最為昂貴,然而對於物件的原始資料測距準確性能維持在3cm以內,這是相較於其它種類的感測器較具有的優勢,然而針對不同種類的感測規格需求,如感測器與待測物的距離遠近、相對移動關係,以及待測物種類的分類程度、移動速度、未來軌跡、語意分析(Semantic Analysis),加上感測時的環境,如雨滴、霧霾、塵埃,通常需善用不同感測器之優勢來達到自動駕駛的基本需求,若需實現上述所列所有規格的偵測能力,較適合進行多種感測資訊的融合(Sensor Fusion),達到各種感測器相輔相成之功效,光達相較於其它種類的感測器在各種偵測需求條件下的優劣比較如表1所示。
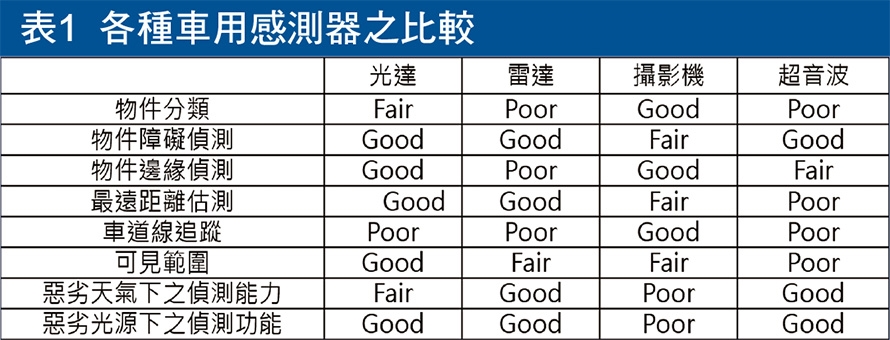
目前部分研究會著重在光達與攝影機的開發上,此兩者皆明顯的具有各自所長,也是較多文獻採用兩者互補的原因,在光達的選擇上會依據使用的解析度的需求而有著巨大的成本差異,高解析度意味著可以進行物件分類與辨識,低解析度意味著只能進行物件偵測,然而距離偵測上不須額外處理較相機準確,而在相機上其成本是遠小於光達,然而在距離輸出的處理上為目前的巨大的挑戰,因此有些相機產品從硬體下手採用多感測器融合如多顆相機或紅外線(IR),有些相機則僅使用單顆相機並在軟體演算法上改良以產出距離資訊,兩個成本與規格比較如圖1所示。
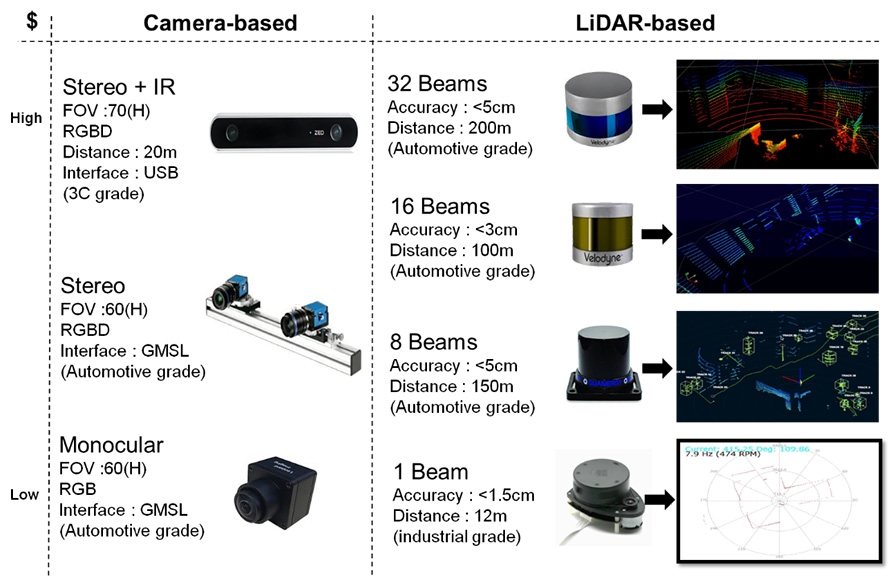 圖1 攝影機與光達感測器規格比較
圖1 攝影機與光達感測器規格比較
深度學習式物件偵測(DNN-Based)
目前在發展光達3D深度學習的文獻上相較於傳統的Rule-Based而言相當稀少,而自2016年底蘋果(Apple)發表基於3D空間網格化的VoxelNet後,基於此種理論背景的相關文獻開始如雨後春筍般地產出,其準確度相較於其它深度學習的網路來得高,然而致命缺點在於因為需要針對整體點雲原始資料進行網格化處理,導致網路輸入的單元與通道數量和計算量相較於其它現有演算法而言極高,因此導致硬體成本也提高許多,才能達到車用規格所規範的畫面更新率(FPS),有鑑於此,後續的幾年又演化出了基於3D轉換為2D影像的深度學習辨識方法,並且基於現有成熟的2D理論套用至光達辨識上,如SqueezeSegNet,此種方法因為採用既有的2D網路架構,並且在網路輸入層的數量上可以固定,因此大大降低計算量與提升計算速度,為後續多數研發單位採用的方法,各種演算法的比較如表2所示。
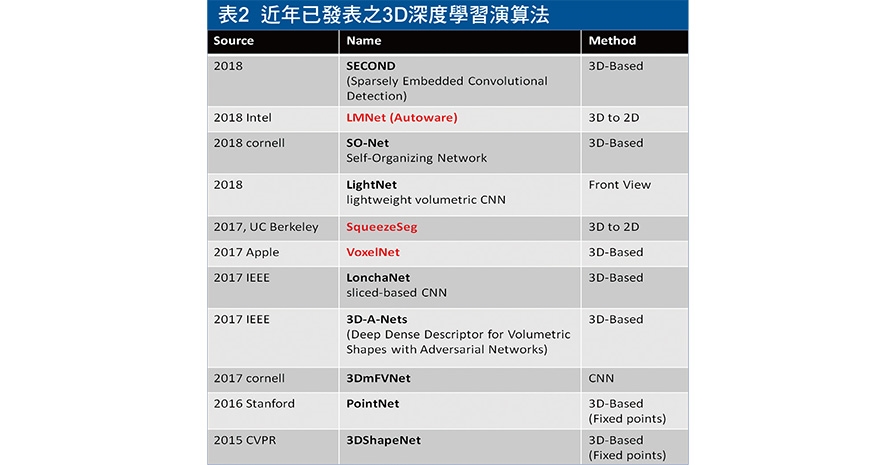
工研院分析現有多種深度學習演算法,針對自駕車所需規格進行比較,最後採用在FPS與精準度較能維持平衡的SqueezeSegNet,此種方法為將3D點雲資料投影至2D影像,再使用深度學習網路辨識後將2D影像上的點雲轉回至3D點雲,並產出3D點雲劃分(Segmentation)的結果,如圖2所示,其中紅色的部分為背景點雲資料,紅色以外的部分為深度學習演算法的輸出結果,其中綠色代表車輛、紫色代表機車(含腳踏車)、藍色代表行人。這些不同的輸出結果意味著3D影像內所有點雲內的每個點的資訊會再附加標記資料,而最後會再基於這些資料進行點雲上的分群以區別不同種類的物體。
 圖2 深度學習演算法之點雲劃分偵測(https://bit.ly/3cQbVv5)
圖2 深度學習演算法之點雲劃分偵測(https://bit.ly/3cQbVv5)
在多數自駕車的應用上,為確保資料傳輸的穩定性,會將資料進行特徵擷取後進行取樣降低(Down Sampling),進行傳輸簡化,此方法可以避免當多個環周物件出現時因資料量過大而產生嚴重的傳輸延遲,資料的簡化過程會依照控制端的需求而使用不同的演算法簡化。本文採用方向性定向框的方法(Orient Bounding Box, OBB),此方法將分群後的物件以非方向性定向框(Axis-aligned Bounding Box, ABB)的長方體方式包覆,其方法為基於現有座標軸計算特定物體之點雲的最大與最小值後組成8個方形點,爾後再進行主向量分析(Principal Component Analysis, PCA),產生旋轉與平移的轉移矩陣或四元數,再套用至將非方向性定向框而產生方向性定向框的結果,如圖3所示。
 圖3 方向性定向框演算法
圖3 方向性定向框演算法
深度學習資料標記方法
現有3D點雲標記工具主要以手工標記為主,並在操作上將人工部分以特定演算法去減少操作程序,而在半自動化的部分尚停留在論文發表的部分,也因此對於標記工具開發商的下個里程碑則是發展半自動化的功能,其半自動化的程度也會因既有的模組準確率而有所不同。本篇研究在人工資料標記上會對應所使用的深度學習演算法,進行點雲劃分的標記,也就是針對單一個點進行種類的標記,在標記的種類定義上也會因應目前光達的解析度而有所不同,以本文所使用之光達感測器為例,對於不同四輪車輛之感測資料常會有重疊的時候,因此無法細分為大客車或小客車,對於不同二輪車輛也會無法分辨細節,如腳踏車與機車的差異,對於人也無法分辨小孩、成年人或老年人。有鑒於上述問題,本篇研究在標記上僅區分出車、騎士與行人,並定義相關的標記規格,如圖4所示。
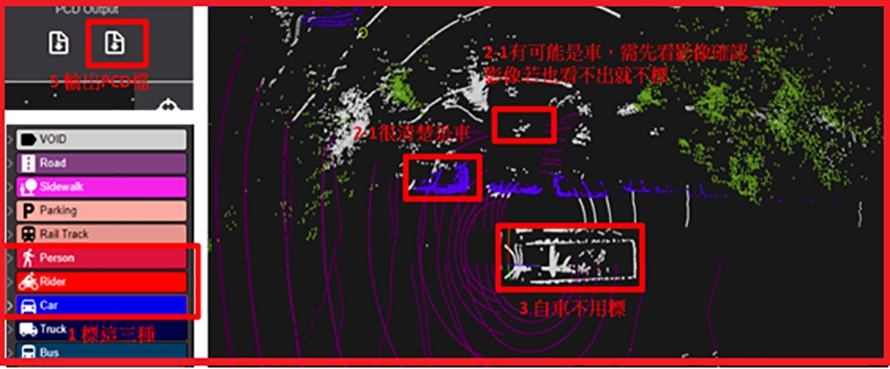 圖4 點雲資料人工標記工具
圖4 點雲資料人工標記工具
工研院基於半自動化標記軟體可以將現有物件偵測上進行功能延伸,如圖5所示,可以使用基礎的分群演算法將有可能的關鍵物件先行標記,讓人工在標記時僅需要針對多餘或錯誤的標記點進行處理而不用再由影像判斷後進行3D點雲的標記,此方法也可以有效降低人工標記上的漏標率。
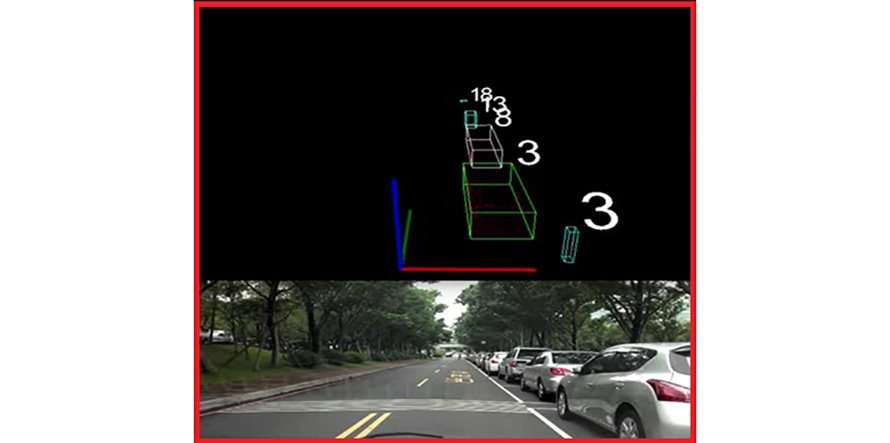 圖5 現有物件偵測結果
圖5 現有物件偵測結果
為了提升光達運算的效能,工研院將自駕車車輛的相關參數輸入至模擬環境裡面並進行相對應的感測器設置如圖6所示,該虛擬標記資料產生工具除了運用在光達感測器上使用,亦可使用在攝影機或其他感測器的環境。在光達環境下能將對應的標記資料以遊戲的方法同步輸出光達的原始資料與標記資料,可大大減少資料標記所需成本。
 圖6 虛擬標記資料產生工具
圖6 虛擬標記資料產生工具
除了上述的標記資料取得方法外,也有相關組織針對關鍵的點雲資料進行資料蒐集與標記後對外開放給相關研究領域使用,如圖7所示,然而在本文所使用之深度學習演算上容易受到不同的光達感測器安裝位置而產生不同的辨識結果,因此,還是需要針對所使用的載具進行感測資料的蒐集與標記,使用既有的光達資料庫進行訓練僅能做部分參考的依據。
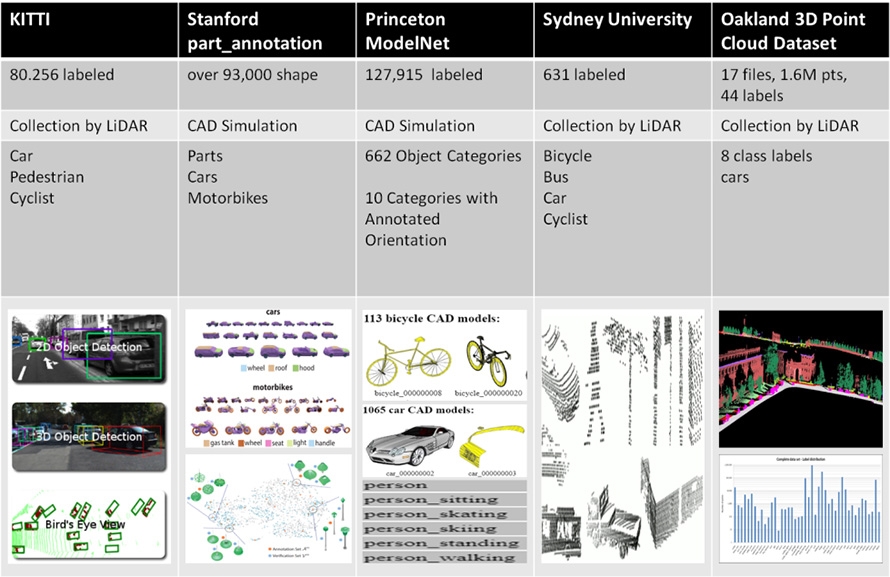 圖7 現有開放式3D光達點雲資料庫
圖7 現有開放式3D光達點雲資料庫
半自動AI標記加持光達環境感知力新突破
有鑒於國際自駕車發展趨勢與我國資通訊產業技術優勢及缺口,發展車用感測器技術並建立車規等級之高可靠度環周物件感知能力為自動駕駛技術的首要任務,透過既有的機器學習之技術能量,在有限的感測裝置與資訊及多變的行車環境上提供自駕車可靠的視野辨識能力,光達感測技術則扮演關鍵的角色。工研院致力於研發光達深度學習演算法,並探究如何提升光達標記資料的效能,因此,有別於傳統影像的人工標記,光達的點雲標記則較為困難,工研院觀測出半自動產生標記資料以驗證深度學習演算法的可行性與準確性並同時降低標記的成本,於開發的過程發現使用虛擬的標記資料進行模型訓練容易造成過度擬合(Overfitting)。未來於光達深度學習演算法的精進上,將模擬標記資料與真實標記資料進行混合訓練出模組,該模組可改善單獨使用模擬環境或真實資料所獲得的標記資料其物件偵測準確度較低的問題,使自駕車具備結合模擬環境與真實世界的標記資料所訓練後的模組,提供更準確的環境感測與定位。
(本文作者皆任職於工研院資通所)