如果要說有哪個指標可以用來衡量新技術的顛覆性,那莫過於大眾所表露出的恐懼和懷疑。如果以社會的焦慮做為衡量標準,那麼人工智慧(AI)在今日的再次興起,會讓AI成為改變世界的突破性科技名單候選人。正如伊隆・馬斯克、比爾蓋茲、史蒂芬・霍金和其他科技巨擘所說,AI將會改變人們的生活。對於AI應用不良影響的廣泛擔憂,在技術變革發生時並不稀奇,這是社會不安的表現,在新技術相關變革及隨之而來的巨大潛力產生之前,常會出現這種不安。
以當前的議題做為契機,針對AI及相關的機器學習(ML)和深度學習(DL),提出產業的觀點,本文將會檢視從雲端轉移到邊緣網路的高效能處理,如何讓物聯網(IoT)蓬勃發展,以及這種模式的轉變如何為AI奠定基礎,發揮真正的潛力。同時也會探討現今物聯網未來的展望,屆時智慧的互聯裝置不僅可以彼此通訊,還能運用AI代表人類相互進行交流。有朝一日,這種AI物件的新全球結構,將會成為AIoT,也就是AI物聯網,而後文會進一步討論這些技術的龐大潛力,檢視其限制,並反思某些AI應用對物聯網安全所造成的實際威脅,以及如何對抗這些威脅。
AI發展現況
作為一門數學學科以及某種程度上的哲學,AI已經沒沒無聞超過60多年,直到現在才突然受到大眾的熱切關注。造成這股熱潮的其中一個原因,是因為過去長期以來,對AI應用的思考一直停留在純理論,或只能在科幻小說中見到。要在目前的物聯網環境中實現AI的使用,必須滿足三個條件:
1. 極為龐大的真實世界資料集
2. 具備強大處理能力的硬體架構和環境
3. 強大的新演算法和人工神經網路(ANN)的發展,充分發揮前述兩項的潛力
後兩種要求顯然是相互依存,如果處理能力沒有大幅提升,深度神經網路的突破也無法實現。至於輸入的項目,也就是各種性質的龐大資料集(視覺、音訊和環境資料),則正由數量日益增加的嵌入式物聯網裝置所產生。現今的資料流量呈現爆炸性的成長。事實上,到2020年,年度資料的產生量預計將達到44ZB(1ZB=10億TB),五年之間的年複合成長率(CAGR)等於141%。到2025年,年度資料產生量就會達到180ZB(圖1)。
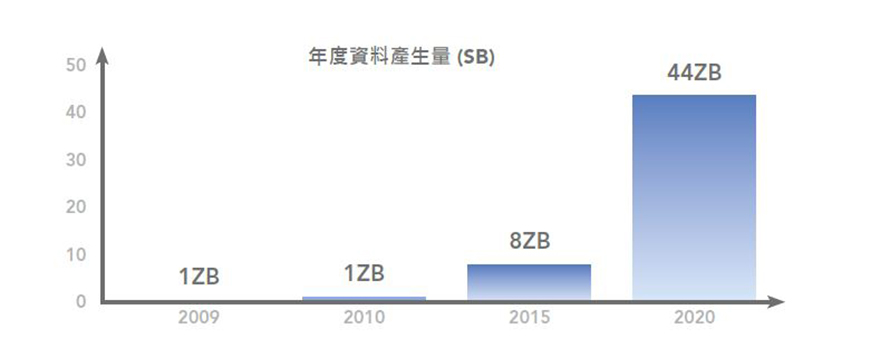 圖1 2009、2010、2015與2020年度資料生產量
圖1 2009、2010、2015與2020年度資料生產量
全球的互聯裝置、機器和系統數量持續增加,所產生的非結構化資料量跟著大幅成長。約從2015年起,當多核心應用處理器和圖形處理器(GPU)普及化時,人們也開始使用這些工具來處理龐大的資料量。平行處理變得更快速、更便宜也更強大。加上快速、充足的儲存空間以及更強的演算法,針對這些資料進行排序和建立結構,突然之間讓AI能夠蓬勃發展的環境就出現了。
如圖2所示,自1993年以來,全球超級電腦的原始運算效能(以GFLOP為衡量單位)呈現爆炸性的成長。此圖為全球超級電腦500強名單中,Rpeak GFLOPS排名第一的全球超級電腦數據。
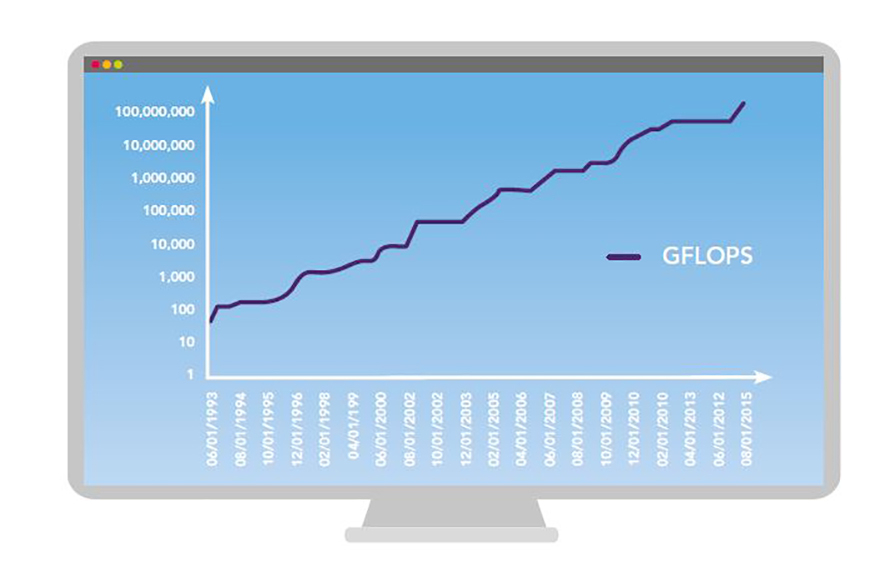 圖2 1993~2016年間全球超級電腦的原始運算效能
圖2 1993~2016年間全球超級電腦的原始運算效能
2018年,經由神經網路訓練的AI語音辨識軟體,已成為各種消費應用和工業應用不可或缺的一部分。運算能力每年大約提升10倍,主要是由新類型的客製化硬體和處理器架構所帶動。運算能力的大幅提升是促使AI進步的要素,推動AI成為未來的主流。
多重演算法實踐AI
就典型的定義來看,AI其實並不新奇。英國神經科學家暨AI先驅大衛馬爾(David Marr),在他1976年所發表的具開創性的論文〈AI:個人觀點〉中說道:AI的目標是找出和解決有用的資訊處理問題,以及抽象地說明如何解決問題,也就是所謂的「方法」。
構成大腦的生物神經網路,的確隱約地啟發了AI運算系統。不過,AI希望重現人類大腦的功能,讓機器能夠以人類的方式來解決問題,這也成為了流行的迷思。神經網路是一種架構,讓許多不同的機器學習演算法能夠共同運作,並處理複雜的資料輸入。這與生物的不同之處在於,人工神經網路(ANN)著重於執行特定任務,而非廣泛的問題解決與計畫能力。
相較於科學研究工作,現今產業發展AI的方法其實更加務實。當前的AI開發並非試圖複製人類的思維,而是利用人類推理的方式做為指引,以提供更理想的服務或製造出更好的產品。但要如何達成?須進一步檢視目前的方法(圖3)。
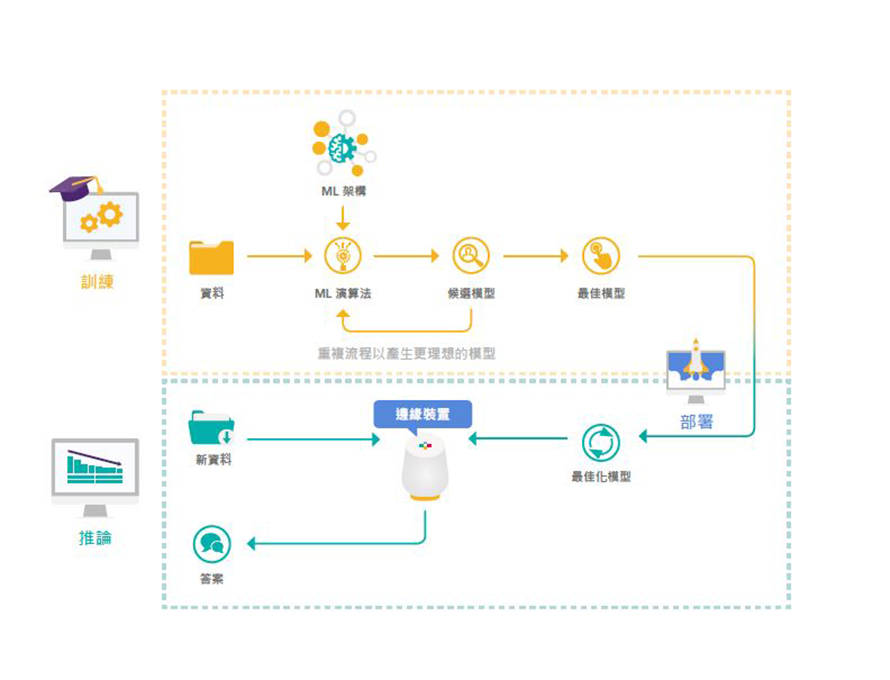 圖3 AI訓練與推論流程
圖3 AI訓練與推論流程
機器學習
機器學習是AI的子集,不須透過明確的程式設計,而是運用統計的技術,給予電腦學習的能力。最粗淺的方法是,機器學習會利用演算法來分析資料,然後根據其解讀來進行預測。
關鍵環節是機器須經過訓練,可從資料學習,進而執行指派的工作。為了達成這項目標,機器學習應用了模式識別和計算學習理論,包括概率技術、核函數和貝氏機率,這些技術已經從專業的小眾學問,發展成為當前機器學習方法的主流。機器學習演算法的運作方式不是遵循靜態的程式指令,而是根據輸入訓練集的範例來建立模型,然後輸出由資料產生的預測。
電腦視覺是機器學習中最活躍且最受歡迎的應用領域。這是從真實世界中擷取高維度的資料,以產生數值或符號性的資訊(最終產生出決策形式資訊)。不過在近期,仍必須進行大量的人工程式設計,才能讓機器發展出進階的模式辨識技巧。人類操作員必須擷取邊緣的資料,以定義物體開始和結束的位置、套用雜訊去除濾波器或加入幾何資訊,例如關於特定物體的深度。結果發現,即使運用先進的機器學習訓練軟體,要讓機器以數位方式真實重現其環境,也並非簡單的任務。這時深度學習就能發揮作用。
深度學習
軟體可以在人工的「神經網路」中,模擬生物新皮質的神經元陣列,這想法已經行之有年。深度學習演算法模擬人類神經網路的多層結構和功能,就是在嘗試實現這個想法。在實際應用上,深度學習演算法會在數位化呈現的聲音、影像和其他資料中學習,以辨識出模式。但是要如何做到?
隨著演算法目前的改進和處理能力的提升,現在可以建立擁有更多層虛擬神經元的模型,以更進一步的深度和複雜度來運作模型。過去有很長的一段時間,使用貝氏(Bayesian)方法並不可行,因為如果要計算證據,就必須以人工方式來計算機率的積分。現在,人們在多層神經網路中使用貝氏深度學習法,來解決複雜的學習問題。
不過,人們現今所能做到的,大部分仍屬於「狹義」或「弱」AI的概念,也就是這些技術只在特定的任務中能做得跟人類一樣好,或是做得比人類好。例如,用來將圖像分類或辨識人臉識別的AI技術,在某些方面能夠進行如人類智慧的思考(但並非全面),或甚至是結合數種人類能力進行作業。機器如果能夠執行眾多的複雜任務,表現出至少與人類一樣熟練和靈活的行為,則會被視為「強AI」。雖然專家們對是否能夠實現強AI的議題意見分歧,但他們都在努力嘗試著實現。
AI投資自2013年以來增加三倍
隨著相關的資料量呈現爆炸性成長,能夠以更高效率解決數學和運算問題的系統,也成為當前的重要需求。因此,IT產業的主要業者也聚焦於發展IC和應用程式,目標是在市場中將AI定位於新一代軟體技術的核心。
若要衡量一個技術是否具有顛覆性潛力,目前注入AI領域的投資規模是個可靠的指標。麥肯錫(McKinsey)的資料顯示,2016年對AI的投資額為260億至390億美元,其中大部分來自於Google和百度(Baidu)等科技巨頭。自2013年以來,對AI的外部投資已提升了三倍。在中國,對AI方面的投資比去年同期增加了76%。中國高科技公司阿里巴巴(Alibaba),將會在未來的5年內投資150億美元,打造全球AI技術網路。
值得注意的是,投資者也越來越關注與AI事業的新創公司。對這些事業的投資金額,已經從2014年的26.7億美元,增加到2016年的50.2億美元。從2016到2017年,全球AI新創公司的數量增加了大約141%;自從2016年起,有超過1,100家新的AI公司募集了股權資金。
全球各地的政府也開始注意AI產業的實用性。歐盟委員會希望讓歐盟居於AI的領先地位,並宣布提供17億美元用於研究和開發相關技術,此一金額與中國國家集成電路產業投資基金比較之下相形見絀,該基金的目標是投入470億美元來開發AI技術。其他數個國家也已制定了國家AI計畫。美國在2016年5月實行了全面性的AI研發計畫、英國啟動計畫以改良資料的存取、AI技能與AI研究,加拿大則宣布一項1.25億美元的「泛加拿大AI策略」計畫。
AI經濟展望一片光明
因此,經濟預測看好新興的AI市場。普華永道(PWC)的研究顯示,全球的GDP在2030年可能會因為AI而提升高達14%,這等於再增加15.7兆美元。「其中6.6兆美元可能來自生產力的提高,9.1兆美元可能來自消費方面的效應。」縱觀各國,中國和北美預計將從AI獲得最大的經濟收益(2030年中國GDP將增長26%,北美將增長14.5%),相當於總計10.7兆美元,中國將獲得其中的7兆美元,占全球影響力的近70%,使北美的3.7兆美元收益相形見絀。
AI對北歐的區域經濟影響較小,但預計仍會增加9.9%的GDP,等同於1.8兆美元。在英國,預計到2035年,AI可以為經濟增加額外的8,140億美元(6,300億英鎊),將GVA的年增長率從2.5%提高到3.9%。基於AI對強大運算硬體的依賴性,IC產業不意外地成為影響經濟的最大因素。到2025年,僅僅只看半導體產業,AI相關元件將達到600億美元的全球銷售額。其中一個具有龐大潛力的領域是醫療照護市場,從2017到2027年,AI可貢獻將近40%的成長,此市場的產值預計將在2027年達到500億美元。
在過去的兩年中,AI已經在各種不同的產業達到26%以上的複合季增長率(CQGR)。從策略的角度來看,AI最大的潛力在於與物聯網的互補性:物聯網的元件可確保持續提供相關資料,AI的功能則做為系統的推理引擎,解讀端點所產生的資料,並驅動其運作功能。將物聯網和AI合併為整合性的技術組合,可打造出強大的數位商業價值新平台。
將AI推向邊緣
正如我們所見,AI若要能夠發揮其龐大的潛力,須要仰賴同樣強大的硬體。機器學習尤其需要強大的處理與儲存功能。例如,百度其中一種語音辨識模型的訓練週期,不僅需要4TB的訓練資料,而且在整個訓練週期內,需要進行20EFLOPS的運算。現今的AI需要仰賴強大硬體,無怪乎AI多局限於資料中心。
發揮高效處理潛力
將AI從資料中心分離出來,並推進到物聯網的端點,將可讓我們充分發揮AI的潛力,這正是半導體業者(如恩智浦)的目標,而其也深入檢視這些需求。現今的物聯網生態系統已發生顛覆性變化,也就是將資料處理從互聯系統的中心轉移到邊緣。邊緣處理已經把對於運算應用程式、資料和服務的控制,從某些中心節點(核心)轉移到網際網路的外圍。這是物聯網裝置與實體世界接觸的地方,也是資料經由各種感測器(例如視覺、語音、環境)進入之處。在邊緣處理這些資料,可以大幅減少待轉移的資料量,進而提高隱私性、縮短延遲,並提升服務品質。
脫離中央核心的依賴,也代表消除了主要的瓶頸和潛在的單點故障風險。邊緣處理使用分散式的資源,在某些應用中,這類資源可能無法持續連線到網路,例如自動駕駛車、植入式醫療器材、感測器等極為分散的場域,以及各式各樣的行動裝置。為了在此類嚴峻環境中使用AI,必須配備敏捷的應用程式來持續學習,並將結果快速套用到新資料上。這種能力稱為推論:擷取較小的真實世界資料區塊,然後根據程式已經完成的訓練,來處理這些資料。
針對邊緣的AI應用,其關鍵設計目標是在系統成本與最終使用者體驗之間找到平衡。例如,採用機器學習技術的微波AI烤箱,在1到2秒內辨識出食物即可。不過,辨識停止標誌、行人穿越道,或是偵測車輛駕駛昏昏欲睡時眼睛即將閉起等情境,則需要更快的處理速度。企業若要加強其AI應用產品組合,可擴充的處理器和軟體支援是關鍵,因為這些可讓開發人員針對廣泛的特定AI應用,部署最適合的IC。因應此趨勢,恩智浦的產品組合也致力涵蓋現代AI應用中所使用的完整MCU和應用處理器產品組合。
量子運算是打造強AI的靈丹妙藥嗎
為了要加速運算,量子電腦直接踏入一個超乎想像的巨大現實結構,那是量子力學的奇異世界。不同於傳統數位電腦那樣使用代表0或1的位元來儲存資訊,量子電腦使用量子位元(Qubits),將資訊編碼成0、1或是同時為0與1。此一疊加狀態加上其他量子力學的糾纏與穿隧現象,使量子電腦可以一次操作巨量的狀態組合。
AI極須仰賴快速處理,那麼量子電腦是否為實現強AI的明燈?
是,但也不是。事實上,在過去十年裡,量子電腦的發展已經從推測與辯論這項技術的現實可行性,進入小型原型的示範領域。其概念不但已獲得驗證,內建數十個量子位元的運算機器也已經在運作。然而,無法確定這樣的發展勢頭是否能持續不減,量子電腦是否能夠到達或超越傳統電腦的能力。量子電腦的進展中,有一些根本的問題,讓科學家無法確實預測究竟是否能夠打造出更大許多的電腦。
量子電腦的一項重要特性,是其僅適用於特定類型的運算問題。一般電腦使用的隨機演算法並非全都適合量子電腦使用。至今只開發出少數可以在量子電腦上執行的演算法。這類演算法也包括Grover演算法,可以大幅度加速非結構化方法搜尋,以此搜尋非常大量的資料,因此具備AI的巨大潛力。如果量子電腦普及化,我們預期量子電腦將補足普通電腦的功能,而不是取而代之。
一直以來都有推測宣稱,量子電腦可以破解傳統的加密系統,例如公用金鑰演算法(RSA、Diffie-Hellman、Elliptic Curve),以及對稱性密碼,例如三重DES和AES。暫且不管對此一主張的重大疑點(緣自於量子電腦的概率性質),就算真的破解密碼,那也是在未來才會發生的事,大約在2030年左右。
專用機器學習環境
若要建置具有最新尖端能力的創新AI應用,開發者需要一個機器學習軟體環境,以輕鬆將專用功能整合到一般的消費類電子產品、工業環境、車輛以及其他嵌入式應用中。但若要以更廣大的規模實施以AI為基礎的商業模型,讓所有垂直產業的數十億位最終使用者能使用AI應用,產業必須先克服過去的限制。
這就是恩智浦自行開發機器學習硬體和軟體環境的原因,以便在現有架構中執行推論演算法。利用本身的機器學習環境,讓旗下裝置陣容,從低價MCU到突破性的跨界i.MX RT處理器和高性能應用處理器,都可執行各種不同的機器學習功能。這個機器學習環境能使用統包方式,讓設計者在整個產品系列中選擇最佳的運算元素:從Arm Cortex M和A核心,到高效能GPU和數位訊號處理器(DSP)以及自訂加速器架構皆有提供,以利提升資料處理能力。
這樣的機器學習環境可以針對視覺、語音、路徑規畫與異常偵測方面,實現快速發展的機器學習使用案例,並在引擎上部署機器學習模型所需的整合平台與工具,包括神經網路與經典機器學習演算法。
對於預計將機器學習整合於應用中的開發者而言,機器學習環境的軟體工具能幫助開發者匯入自己預先訓練的機器學習框架。從開發者所選的開放原始碼軟體程式庫匯入,可達到高效能的數值運算,例如TensorFlow或Caffe模型,設計人員可將這些模型轉換成最佳化的推論引擎。開發者可以使用工具訓練雲端中的模型,然後匯出模型,並將模型部署在內建於邊緣應用的晶片內。
為了支持各種各樣的開發者需求,半導體業者亦建立了機器學習合作夥伴生態體系,體系不斷成長,讓開發者能夠接觸互補性技術,以利經實證的機器學習工具、推論引擎、垂直應用和設計服務可以更快帶來收入。而這還只是第一步,目前市場上有業者(如恩智浦)已開始在裝置中整合可擴充的AI加速器,這會將機器學習效能提升至少一個數量級。
AI對物聯網安全之影響
每隔一秒,就有五個新的惡意軟體變種被發現。全球各組織每小時遭受一百種未知的惡意軟體攻擊。物聯網世界中,每天都會出現100萬個新的惡意檔案。隨著越來越多的裝置和系統連接到網路,網路犯罪也對人們的技術資產以及整體社會的安全造成更大的威脅。為此,恩智浦也致力打造安全裝置,在裝置內建立各種對策,讓裝置能防禦各種邏輯上和物理上的攻擊,例如旁路攻擊或範本攻擊。駭客利用AI來擷取安全系統的秘密和重要資訊是遲早會發生的問題,因為AI會增強其學習能力。晶片業者必須思考衡量產品的防護機制,以確保防範各種即將出現的手法。
AI的進展與網路威脅的發展密切相關。機器學習是雙面刃:雖然機器學習能讓產業等級的惡意軟體偵測程式運作更有效率,但它很快就會被惡意攻擊者用來增強攻擊的進攻能力。事實上,阿姆斯特丹大學有一群研究人員最近證明了這可能性。在一場旁路攻擊中,攻擊致使CPU轉譯後備緩衝區(TLB)資訊外洩,白帽駭客使用新穎的機器學習技巧來訓練他們的攻擊演算法,並讓效能更上一層樓。研究人員認為,機器學習技巧將提升未來旁路攻擊的效力。在全新高效的AI與機器學習技巧實現後,為防止進攻與防護的平衡崩壞,產業必須專注於利用AI改善系統安全和資料隱私權。
機器學習讓系統安全性加分
機器學習型安全功能的一個好例子就是異常偵測,系統會「偵測」資料流中有否有異常行為或模式。在過去,垃圾郵件和惡意軟體偵測經常使用這個程序,但機器學習可擴大為搜尋系統中更加細微和複雜的異常行為。雖然有效的系統防護重點在監控並防止外部威脅,卻甚少組織注意內部威脅。Accenture於2016年所做的調查中發現,有三分之二的受訪組織曾是組織內部資料竊盜事件的受害者。在這些例子中,91%受訪者表示他們缺乏有效的偵測方法來確認這類威脅。而在開發有效、即時的剖析與異常偵測功能方面,機器學習可偵測和抵消系統內使用者造成的威脅,提供極大的幫助(圖4)。
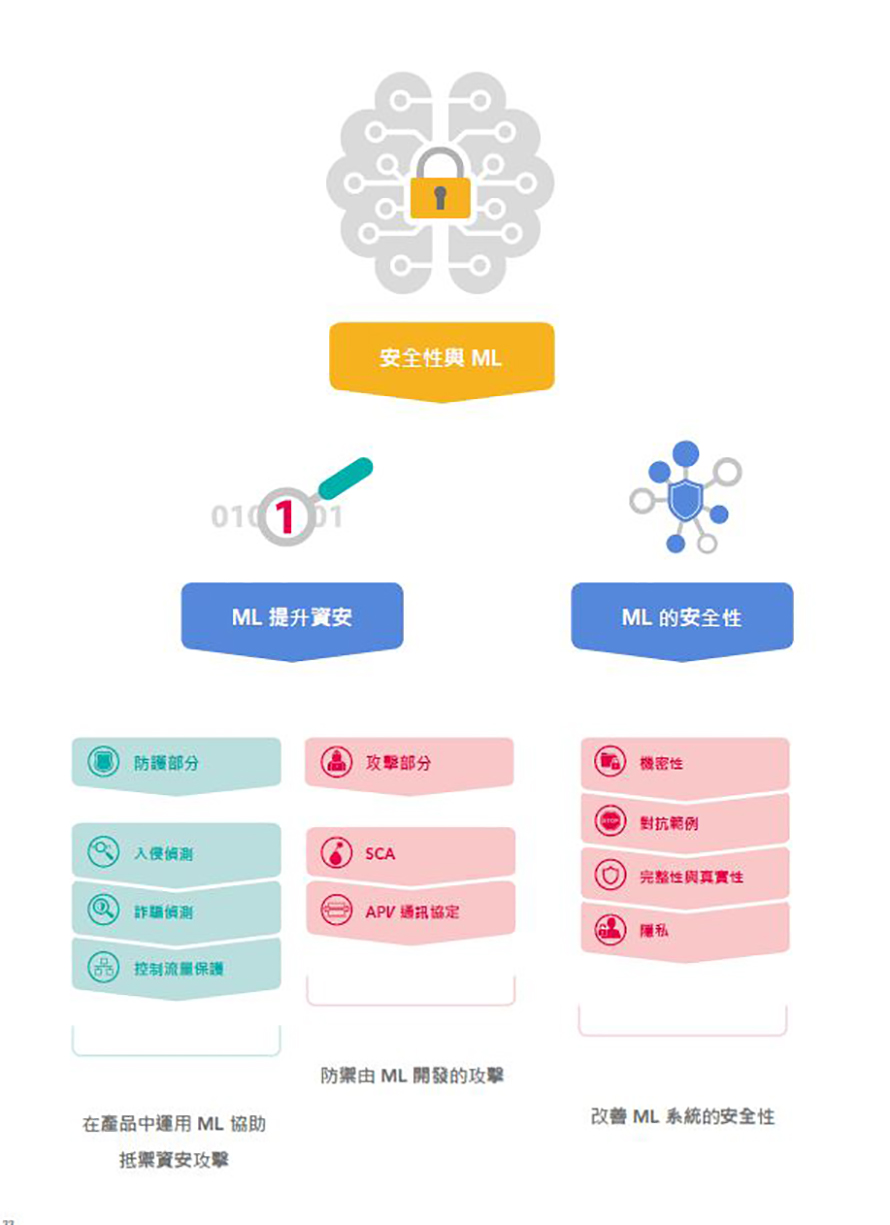 圖4 安全方案與機器學習技術相輔相成
圖4 安全方案與機器學習技術相輔相成
保護隱私的機器學習
使用應用的資料提供者不希望在缺乏保護的情況下,提供資料給AI(無論是在訓練階段或推論階段)。自2018年5月25日起,新的歐盟一般資料保護規範(GDPR)生效以後,所有企業在處理歐盟公民的資料時,均必須實施隱私權保護,違反規範者將面臨高額罰款。
比如,在醫療與金融應用中,若使用者將個人資料提供給資料集,企業均負有保護其隱私權的責任。其中一個典型的使用案例是病患病歷診斷模型的訓練。在機器學習模型對外開放使用時,即會招來相關的威脅,例如在上一個使用案例中醫院執行診斷的情況,惡意使用者若擁有存取模型的權限,便有能力分析其參數,並回溯用於訓練該模型的部分資料。
在工業環境中,也有一些應用的資料隱私性對系統提供者而言十分重要。例如,在預測性維護中,機器資料用於判斷維修中設備的狀況,以利準確預測應在何時執行維護。這個方法可以大幅降低例行性或時間性的預測維護成本,因為只有在必要的時候(而且理想上要在系統故障發生之前)才須要執行任務。參與服務的機器使用者有很明確的意圖,就是想要從所產生的資料獲益,然而為保護自身利益,他們也不想與使用同一部機器的競爭對手分享資料。這會讓提供維護服務的業者陷入兩難。
同態加密的一般研究領域因應而生,這是一種加強隱私的技術,能將資料加密為可計算的密碼文字。在運算中使用的任何資料皆保持加密形式,唯有指定的使用者才能看見內容。在解密後,運算的結果與純文字套用相同運算所獲得的結果相符。在機器學習的環境中,若公司希望將資料輸入至外部提供的雲端型機器學習模型,可以使用同態加密,避免他人存取未加密的資料,同時又可對資料套用複雜的運算。
屬性加密是另一種隱私保護技巧,遵照嚴格的資料保護與隱私規定執行機器學習程式。以恩智浦所使用的屬性驗證為例,是以IBM Research研發的Identity Mixer通訊協定為基礎,兼具強大的驗證能力與隱私保護。此屬性驗證利用彈性公用金鑰(假名)和彈性憑證的組合,讓使用者僅分享特定交易所需資訊,而不會揭露任何其他屬性。此外,外部各方也可以僅根據使用者的假名來建立資料檔。
攻擊機器學習:在訓練時發生的攻擊
如果攻擊者攻擊的是機器學習本身的安全性呢?在介紹這個領域的可能威脅之前,可先簡單總結機器學習的運作方式。所有機器學習均從訓練資料起步,其會輸出一組參數,本質上就是一個模型。在第二階段(推論),若指定新的樣本,模型便會推論出相應的輸出。例如,若機器學習演算法是一個影像分類程式,有人輸入一個新影像,模型便會回傳影像的類別(例如,該影像代表一隻貓)。這個程序的所有步驟,從訓練到推論,都可能成為被攻擊的目標。
甚至在收集訓練資料並輸入至機器學習模型時,也可能發生攻擊。攻擊者的目標可能是竊取資料,也可能是變更資料或是操控機器學習模型的結果。一個AI模型若要作出與現實相符的預測,最重要的是其訓練資料必須值得信任。但有時難以取得足以信任的資料。其中一種典型的應用,是利用使用者傳送的資料訓練異常偵測工具。若使用者故意傳送不正確的輸入資料,對訓練資料「下毒」,就可能導致效能變差,甚至是使機器學習的模型在推論時發生失敗。
在推論時發生的攻擊:對抗範例
在推論階段亦必須保障使用者的隱私權。若是使用私人資料或敏感資料進行推論時,關係就更加重大了。使用者也可能是攻擊者,他們可能利用所謂的「對抗範例」作為攻擊方式。對抗範例是一種有效的輸入資料,但會導致機器學習模型曲解。這種看似無害的攻擊卻可能造成災難性的後果,以交通號誌的分類這攸關安全的狀況為例,研究人員在停止號誌上貼上特別製作的貼紙,證明可以欺騙影像分類程式曲解號誌或是完全無法辨識號誌。雖然在人類的肉眼看來只是一般的停止號誌,機器學習模型卻無法如此辨認。對抗範例的概念已提出許久,但其造成的後果嚴重性非昔日可比,例如停止號誌對抗範例會導致自動駕駛汽車撞車。
IP保護刻不容緩
機器學習模型的價值大多在於相關聯的資料集。訓練資料可能要花費高額成本去收集,又或是難以取得。當提供機器學習的服務時,使用者僅可存取模型的輸入和輸出。例如,在影像分類程式的案例中,使用者提交一個影像,然後收到影像類別的回傳結果。使用者可能會動起歪腦筋而複製模型,這樣以後使用就不必再付費。其中一種可能發生的攻擊,是針對選定的輸入資料查詢服務,取得相對應的輸出,然後訓練所取得的資料集,以獲得一個功能相同的模型。
本文僅提及部分攻擊型態,攻擊者也可能結合各式攻擊,造成更大的傷害。例如,只要某個模型被竊取,便可用來還原訓練資料或是製作對抗範例。必須考量AI的可能影響,使其成為物聯網系統安全不可或缺的一部分,以作好準備應對這些不斷演進的威脅。若不希望AI機器學習模型的訓練與推論在未來為競爭對手敞開大門,必須從一開始就將設計內含安全性(Security by Design)與設計內含隱私權(Privacy by Design)的原則納入考量。幸好,現在開始讓AI領域運用從物聯網安全所學習到的教訓,並不算太遲。
在得到高效能處理能力後,即可開始減少在資料中心和雲端處理及分析的資訊,並提升在邊緣進行的處理和分析,同時見證了魔法般的驚奇。我們見到了基礎建設、產業、個人裝置等方面的奇妙改變,讓人們的生活更多姿多彩,這得感謝物聯網所帶來的一切。
半導體業者設計出具有智慧內容的機器,並將它們連結至物聯網,進而建立起一個全球性的資產網路,不但改善人們的生活,也讓這些資產更易於使用,更加安全。物聯網賦予人們眼睛、耳朵甚至雙手,從網路邊緣伸展至現實世界,讓人們得以收集原始資訊,再將資訊串流至雲端經過處理,化作極具價值的事物,那就是可應用的知識。
現在的智慧物件會串流資料,瞭解人類的喜好,而且可使用應用程式控制,但仍不是AI裝置。它們可互相通話,但無法合力運作。監控疫苗供應冷鏈的智慧貨櫃並不是AI系統,除非它能做出某些特別的事,例如預測貨櫃的溫度變化並自動調整冷卻功能。
瞥見未來:AI物聯網
自動駕駛車,以及自動搜查岸邊的搜救無人機,就是AI系統。如果機器能代替人類開車或飛行,其中一定包含非常厲害的AI功能。閱讀、說出或翻譯語言、預測某個物件的質量與速度、代購買股票、辨識臉孔或診斷乳癌,上述由演算法完成的作業都具有AI特徵。
現在,想像一個所有AI裝置均聯網的世界,利用認知功能(例如學習、解決問題和決策)擴大物聯網的邊緣,能讓現在的智慧物件從單純的實用工具,變成人類自我的真正延伸,讓人們與現實世界互動時有更多不同的可能性。而AI是物聯網不可或缺的一部分,也是創新使用案例與服務的基礎。舉例來說,西門子(Siemens)正使用AI改善燃氣渦輪發電機的作業,系統能從作業資料學習,大幅減少有毒氮氧化物的排放,同時提升渦輪發電機的性能與使用壽命。西門子亦使用AI系統,自動調整下游風力渦輪機的葉片角度,以提高電廠的發電量。
此外,GE已開發出採用無人機和機器人的工業檢驗服務,使用AI針對檢驗裝置的導覽,以及從檢驗裝置中擷取到的資料確認缺陷等,將事務全面自動化。在醫療界,美國費城的湯瑪斯·傑佛遜大學醫院(Thomas Jefferson University Hospital)設法利用自然語言處理改善病患體驗,讓病患可以控制病房環境,並利用語音指令要求提供各種資訊。而勞斯萊斯(Rolls-Royce)則正在研發一項具備物聯網功能的飛機引擎維護服務,利用機器學習識別引擎形式,找出引擎運作的深入見解,並向航空公司販售這些資訊。
在消費者方面,Google Duplex也構築出未來的可能樣貌:虛擬助理可透過電話執行「現實世界」的任務,能執行包括預約牙醫門診或晚餐訂位等功能。這些任務一般在兩端都需要真人互動,但情況即將改變,Duplex的AI語音聽起來十分自然,通話的人可能無法察覺他們正與機器對談。
那麼,這對未來代表什麼意義?事實上,即使已經有各種各樣初期的AIoT應用不斷出現,人們仍然無法確切預測未來的發展。唯有一件事情是肯定的:現今所知的數位世代社會,正經歷一場徹底的改變。AI與物聯網合流帶來了模式轉變,其程度比當初個人電腦或行動電話的出現還要更大。而恩智浦希望能透過邊緣的安全聯網處理解決方案促成轉型,讓未來的AIoT得以開發出無數應用。
有效的安全性必須以設計內含安全性與設計內含隱私權為指導原則,這將是減輕未來風險的重要關鍵。若在設計未來使用的基礎架構和裝置時以此為念,AIoT將成為人們轉變生活的力量。
(本文作者為恩智浦半導體技術長)