邊緣運算(Edge Computing)是一種在更靠近伺服器所提供服務的應用端進行資料處理及分析的概念,這樣的概念正日益普及,且為電信供應商、半導體新創公司以及新興軟體生態系開啟新的市場。過去數十年由於科技的巧妙結合,促使大數據(Big Data)為起始展開一個全新領域;而運用儲存在大型資料中心巨量資料的想法,讓人們能夠分析世界上各種紛亂繁複的資料,進而提供消費者新的價值。若將此概念結合物聯網(IoT),並連接從咖啡杯至藥丸分配器、煉油廠至造紙廠、智慧眼鏡至手表等物件,可望帶給消費者無限的價值。
然而,人們普遍認為物聯網市場並未經歷預期中的曲棍球棒成長曲線(Hockey Stick Growth)。除特定的利基市場外,IoT的連結性(Connectivity)並未替消費者帶來足夠的價值。但是,在過去五年中,隨著人工智慧(AI)技術的提升,其已對各行各業及連結性能提供給消費者的價值等觀念產生革命性的改變。在相關產業市場能夠看到結合大數據、IoT與AI應用所帶來的無限潛力令人振奮,但人們才剛開始起步。邊緣運算的概念及其對未來技術路線圖的影響,是有助於利用這些技術結合的初始發展之一。
邊緣運算的概念本身或許不算是完全創新,但若落實應用的話,將會是革命性的創舉。一旦落實邊緣運算,可望解決許多日益嚴重的問題,包括減少大型資料中心的能耗量、提升個人資料的安全性、啟用保障安全(Failsafe)解決方案、降低資訊儲存及通訊成本,以及藉由降低延遲(Latency),創造新的應用程式。
究竟什麼是邊緣運算呢?要如何使用它?它對網路能提供什麼樣的優勢?為能瞭解邊緣運算,就需要瞭解推動其發展的因素、邊緣運算應用的類型,以及當今各行各業如何建構與部署邊緣運算系統單晶片(SoC)。
邊緣運算有許多類似術語,包括「邊緣雲端運算」(Edge Cloud Computing)與「霧運算」(Fog Computing)。邊緣運算通常是形容在一個本地伺服器(Local Server)上執行一個應用程序的概念,並試圖將雲端處理流程移至更接近該終端裝置上進行。
傳統上,「企業運算」(Enterprise Computing)以與邊緣運算類似的方式被採用,且不一定要指出運算位置就能更精準呈現網路功能。而像是思科(Cisco)所創的霧運算,基本上與邊緣運算相同,儘管有許多人將霧運算形容為是在邊緣運算的空間之上或之下,或甚至將它視為邊緣運算的一個子集合。
僅作為參考,端點裝置(End Point Device)與端點通常被稱作「邊緣裝置」,請勿與邊緣運算混淆,而這個區別劃分對本文相關討論內容頗為重要。邊緣運算可採用多種形式,包括小型聚合器、本地端現場伺服器(On-premise Server)或微型資料中心。微型資料中心可以是分布在各地的永久性或甚至是綑綁在18輪大卡車上的移動式貨櫃。
邊緣運算消除既有挑戰並確保安全性
傳統上,感測器、攝影機、麥克風以及一系列不同的IoT與行動裝置,將從其所在位置收集資料,並將資料發送至集中式的資料中心或雲端。
2020年時,全球將有超過500億個智慧型裝置會相互連接,這些裝置每年均會產生皆位元組(ZB)的資料量,到2025年時則會成長到150ZB以上的資料量。
建構互聯網的骨幹(Backbone)主要是能可靠地將各種裝置設備彼此連接並與雲端連接,以確保將資料封包(Packets)傳送到目的地。
但是,將這些資料全部傳送至雲端會產生一些嚴重的問題。首先,150ZB的資料會導致容量問題;其次,就能源、頻寬與運算能力而言,將大量資料從其所在位置傳輸到集中式資料中心的費用很高。據估計,目前只有12%的資料由擁有該資料的公司進行分析,其中只有3%的資料能產出有意義的結果(對「環保數學家」而言,有97%所收集與傳輸的資料都是浪費)。這也清楚說明資料運算效率問題需被解決;第三,存取、傳輸和分析資料的功耗相當大,因此必須找到能降低成本與浪費的有效方式。若導入邊緣運算以在本地存取資料可降低傳輸成本,但仍需高效率的技術以消除資料浪費,而現今的主要方法是在AI效能上尋求解方。因此,所有應用程式的多數本地伺服器都增加AI效能,而已建置的主要基礎架構是新型的低功耗邊緣運算伺服器CPU,以GPU、ASIC或晶片陣列(Array)的形式連接到AI加速SoC。
除了解決容量、能源與成本問題外,邊緣運算還能提高網路可靠性,因為應用程式能夠在大範圍網路中斷期間持續運作。而藉由消除某些威脅因素,如全球資料中心阻斷服務(DoS)攻擊,則可提升安全性。
最後,邊緣運算最重要的面向之一是能夠對即時使用情境,如虛擬實境(Virtual Reality, VR)遊樂商場與行動裝置的影片快取(Caching)提供低延遲的效能;而減少網路延遲則能衍生新的服務,使各種裝置能在自駕車、遊戲平台或具挑戰性的快節奏製造生產環境中提供許多創新應用。
像美超微電腦IoT與嵌入式副總裁兼總經理Michael Clegg便表示,藉由在邊緣處理輸入的資料,減少發送至雲端與回傳的資訊,可大幅減少網路處理的延遲;這就如同一家廣受歡迎的比薩餐廳在更多的鄰近地區開設較小規模的分店,以防在本店所烤好的比薩在送往遠端客戶的途中變冷。
邊緣運算驅動應用程式新商機
5G基礎架構是邊緣運算最具說服力的驅動力之一。5G電信供應商看到在其基礎架構上提供服務的機會。除了傳統的資料和語音連接,5G電信供應商還在構建生態系統,以代管(Host)獨特的本地應用程式。透過將伺服器安置在所有基地台旁邊,行動通訊供應商可以向第三方主機應用開放其網路,進而改善頻寬和延遲。
像Netflix這樣的串流媒體服務,藉由其Netflix開啟連接計畫,已經與地區網際網路服務供應商(ISP)合作多年,以將高流量內容託管在距離使用者更近的地方。隨著5G的多重接取邊緣運算(Multi-Access Edge Compute; MEC)興起,電信供應商嗅到了為串流媒體內容、遊戲及未來創新應用程式提供類似服務的商機。電信供應商認為,他們能夠以一種付費服務方式向所有人開放此功能,使需要較低延遲的任何人都可以支付額外的費用,以能夠在邊緣而不是在雲端中存取應用程式。
Credence Research認為2026年時,整個邊緣運算市場將達到美金96億左右的規模。相較之下,研究與市場分析觀察到在2026年時,行動邊緣運算市場將從現今幾億美元的規模成長到超過27.7億美金。儘管電信是最具聲望且可能是最快速的成長引擎,但據估計,它們僅占大約邊緣運算總市場的三分之一。這是因為大型網路業者、產業界和企業集團也針對其傳統市場提供邊緣運算硬體、軟體和服務,期望邊緣運算能為新應用程式開創新商機。
知名速食餐廳正在開發更加自動化的廚房,以確保食品的品質、減少員工培訓、提升營運效率並確保達到預期的客戶體驗。例如速食連鎖店Chick-fil-A,成功使用現場(On-premise)伺服器,將數百個感測器及控制裝置與相對便宜的本地設備聚集在一起,並在本地運作以防止任何的網路中斷。在2018年的Chick-Fil-A部落格中便提及,藉由製造出更智慧的廚房設備,得以收集到更多的資料。而藉由將資料應用於在餐廳,就能夠建構出更具智慧的系統,同時進一步更加拓展公司業務。該部落格文章也提到,在邊緣運算的協助下,許多餐廳現已能夠處理原先計畫的三倍業務量。
總而言之,一個成功的邊緣運算基礎架構,需要結合本地伺服器的運算能力、AI運算能力,以及對行動裝置、車輛及IoT運算系統的互通性(圖1)。
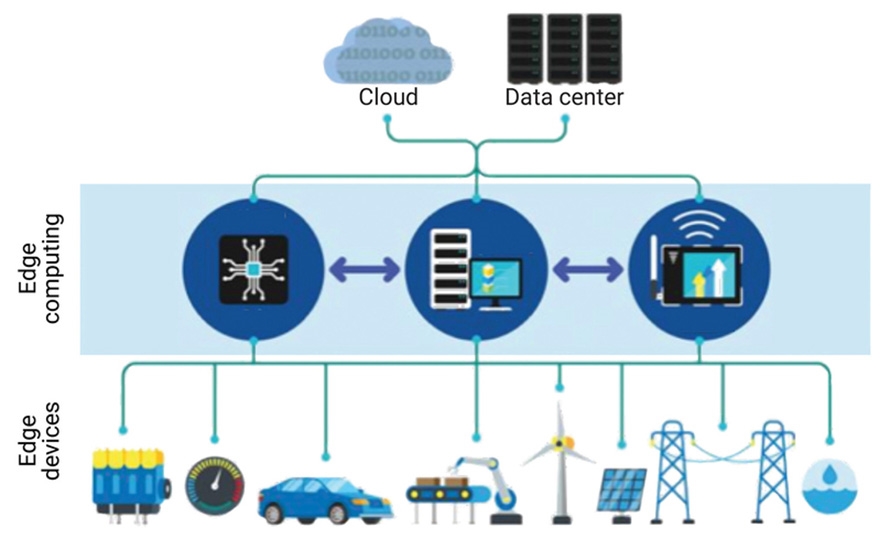 圖1 邊緣運算藉使用微型資料中心分析與處理資料,使雲端處理更接近各終端裝置
圖1 邊緣運算藉使用微型資料中心分析與處理資料,使雲端處理更接近各終端裝置
而像CompTIA科技傳播長James Stanger便表示,隨著物聯網連接越來越多的裝置,網路連結正從主要高速公路到中央位置的往返轉變成某種類似能相互連接、中介儲存與處理裝置的蜘蛛網路。邊緣運算並非在一個集中式資料處理庫中,而是在產生資料的客戶端附近進行資料擷取、儲存、處理與分析。因此資料是儲存在網路「邊緣」的中點,而不是始終將資料儲存在中央伺服器或資料中心。
邊緣運算使用案例
為瞭解使用邊緣運算的延遲優勢,羅格斯大學(Rutgers University)與Inria使用微軟HoloLen對邊緣運算(或稱邊緣雲端)的可擴展性與效能進行分析。
在該使用案例中,HoloLens讀取條碼掃描器,然後使用建築物中的場景分割功能,將使用者導引至特定的房間,並在Hololens上以箭頭標示。這個過程同時使用定位座標(Mapping Coordinate)的小資料封包及連續影片的較大資料封包,以驗證邊緣運算相較於傳統雲端運算的延遲改善。HoloLens最初是讀取QR碼,將定位座標資料發送到邊緣伺服器,在1.2毫秒(ms)的時間內,使用4個位元組加上標題。伺服器找到座標並通知使用者,只花了16.22毫秒的時間;若是將相同的資料封包發送至雲端,則大約需要80毫秒(圖2)。
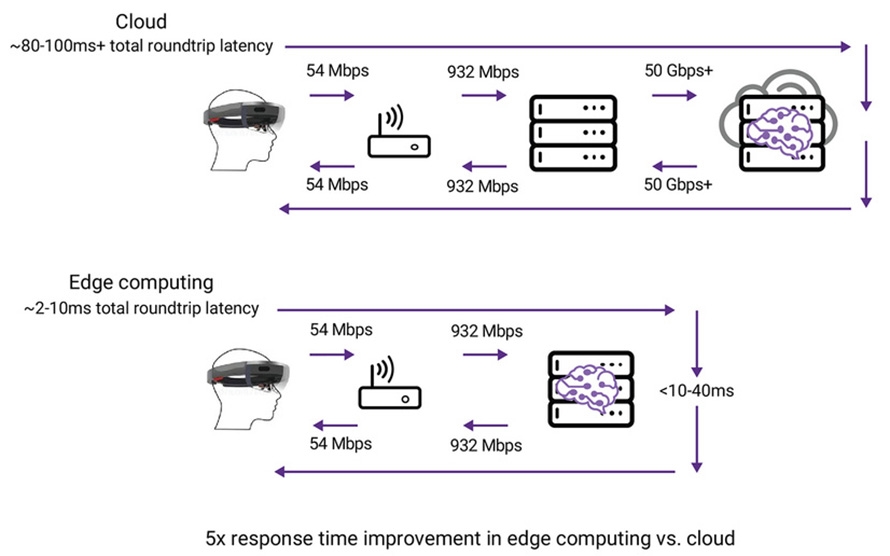 圖2 從邊緣裝置將資料發送至雲端伺服器/邊緣雲端伺服器的延遲比較
圖2 從邊緣裝置將資料發送至雲端伺服器/邊緣雲端伺服器的延遲比較
同樣地,他們針對使用OpenCV進行場景分割,將Hololens的使用者導引到適當位置以進行網路延遲測試。HoloLens在3.33GHz的Intel i7 CPU和15GB RAM的邊緣運算伺服器上進行影像處理,並以30fps的速度串流傳輸影片。將這些影片資料串流傳輸至邊緣運算伺服器花了4.9毫秒,處理OpenCV影像則耗用額外的37毫秒,總計花了47.7毫秒的時間。而在雲端伺服器上進行相同的流程則花費將近115毫秒,顯示出邊緣運算在減少延遲上具有較明顯的優勢。
這個案例的研究顯示邊緣運算在網路延遲上的優勢,相信未來將會有更多的新技術能實現更良好的低延遲效能。
圖3則概述現今5G應用已達到低於1毫秒網路延遲的使用案例,同時針對6G應用能將網路延遲降低至10微秒(μs)的相關討論也已經展開。5G與Wi-Fi 6正在增加互通性的頻寬—5G打算提高到10Gbps,而Wi-Fi 6已可支援2Gbps。AI加速器宣稱場景分割的時間能少於20微秒,相較前述研究中提到Intel i7 CPU約可在20微秒內處理一個畫面的速度,可見有顯著改善。
 圖3 若頻寬提升至10Gbps,相較圖2每秒採樣百萬次(Msps)的10s與100s,從Hololens至路由器與從路由器至具有AI處理改善(從20毫秒縮短至20微秒)的邊緣伺服器,可使往返延遲低於1毫秒
圖3 若頻寬提升至10Gbps,相較圖2每秒採樣百萬次(Msps)的10s與100s,從Hololens至路由器與從路由器至具有AI處理改善(從20毫秒縮短至20微秒)的邊緣伺服器,可使往返延遲低於1毫秒
若邊緣運算相較雲端運算具有明顯的優勢,那麼將資料運算全部移到邊緣中豈不是最佳的解決方案嗎?不幸的是,如圖4所示,並非現今所有的應用都適用邊緣運算。在HoloLens案例的研究中,資料使用結構化查詢語言(Structured Query Language, SQL)資料庫,而SQL資料庫太大因此無法儲存在眼鏡中。時下的各種邊緣裝置,尤其是身體所配戴的各種裝置,都不具可處理大量資料集(Dataset)的運算能力。除運算能力外,相較於在邊緣裝置的軟體,在雲端中或邊緣伺服器上的軟體開發成本更低,因為雲端或邊緣軟體不需要壓縮到較小的記憶體及運算資源。
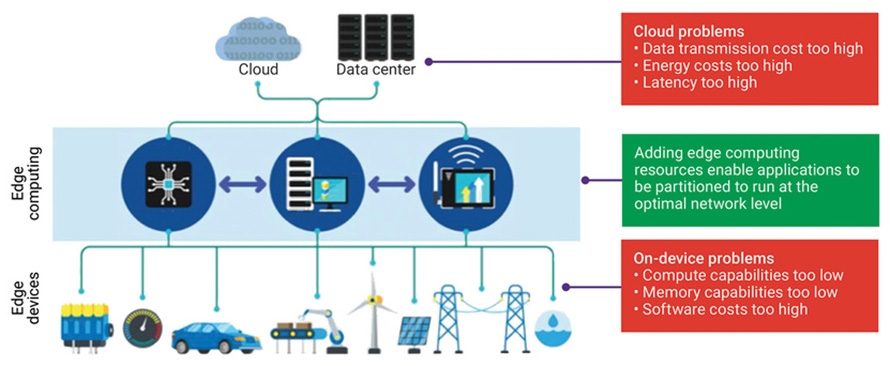 圖4 利用終端裝置比較雲端運算與邊緣運算
圖4 利用終端裝置比較雲端運算與邊緣運算
由於某些應用程式可依據不同位置的基礎架構所擁有的運算能力、儲存能力、記憶體可用性和延遲效能進行理想操作,因此無論是在雲端、在邊緣伺服器或在邊緣裝置中,都有支援未來混合運算能力的趨勢(圖5)。邊緣運算可視為全球混合運算(Hybrid Computing)基礎架構的初步建立。
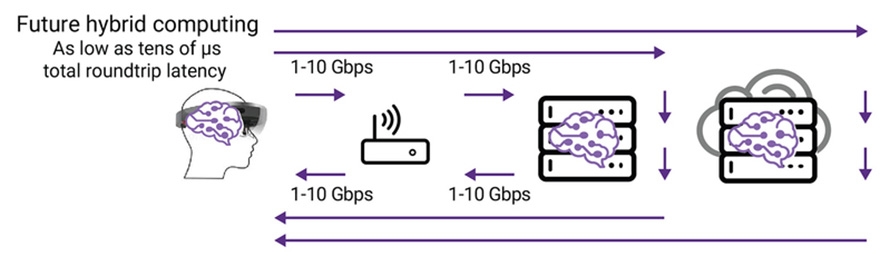 圖5 安裝於Hololens處、邊緣伺服器處與雲端中的AI可讓混合運算的基礎建設針對運算、記憶體與儲存資源進行優化,以符合應用程式需求
圖5 安裝於Hololens處、邊緣伺服器處與雲端中的AI可讓混合運算的基礎建設針對運算、記憶體與儲存資源進行優化,以符合應用程式需求
深入剖析三類邊緣運算取向
邊緣運算是運算位置比較接近相關應用(相較於雲端而言)的運算。但這個距離是300哩、3哩或是300呎呢?在運算領域中,理論上雲端具有無限的記憶體與無限的運算能力。就該裝置而言,理論上僅有足夠的運算與記憶體資源以捕獲並將資料發送至雲端。上述兩種論述其實都有些超出實際運算的想像,但還是可用來描述邊緣運算的不同層級。隨著雲端運算資源越來越接近該端點裝置或該應用程序,就理論上而言,儲存、記憶體與運算資源就越來越少,所耗用的電力亦可被降低。移動至更靠近之處進行運算不僅可降低電力,且可降低延遲與提升效率。
如圖6所示,在該空間內有三種基本的邊緣運算之基礎架構。首先且最接近傳統資料中心者為區域性的資料中心,它是策略性放置的雲端運算陣列之微型版本以減少延遲,但以同等程度保持所需的運算、儲存與記憶體。許多企業與新創公司選擇在此空間解決運算的問題,這類專門為解決區域性的資料中心而設計的SoC,與當前典型的雲端運算解決方案差異不大,專注於高效能運算(HPC)。
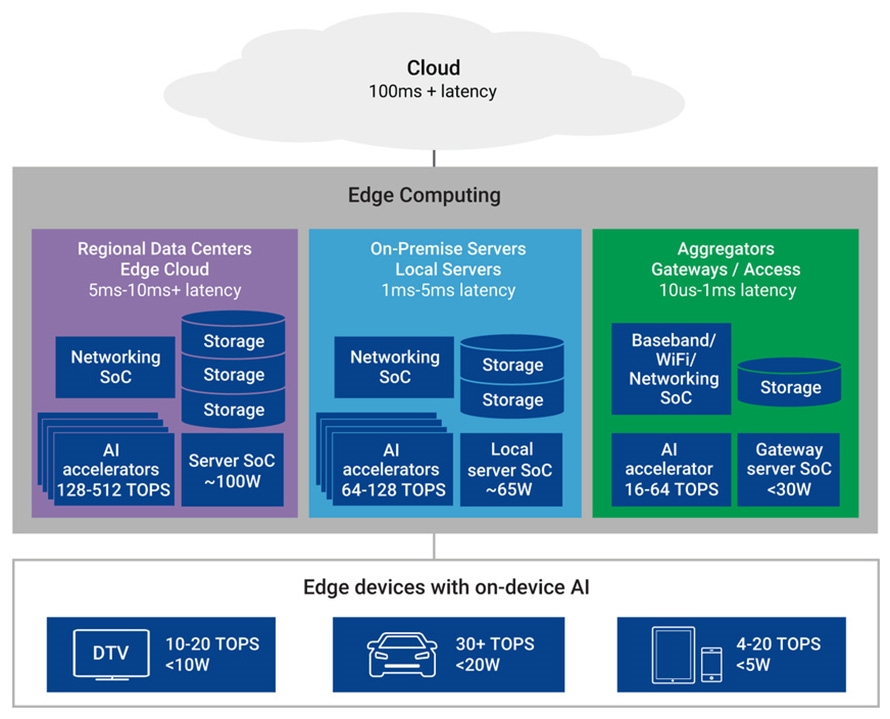 圖6 邊緣運算的三種主要的SoC架構:區域性資料中心/邊緣雲端、現場伺服器/本地伺服器、聚合器/閘道/存取
圖6 邊緣運算的三種主要的SoC架構:區域性資料中心/邊緣雲端、現場伺服器/本地伺服器、聚合器/閘道/存取
第二類邊緣運算是針對SoC解決方案之邊緣運算的電力消耗與連通性需求,通常含有本地伺服器與現場伺服器。當前晶片開發常伴隨者軟體需求的考量,需要採用更有彈性的平台,譬如像是Dockers與Kubernetes之類的容器,Kubernetes已被應用於上述的Chick-Fil-A範例中。對半導體供應商而言,最常見的是現場伺服器資料段在鄰近伺服器SoC處,導入一個晶片組,以處理所需的AI加速。通常AI加速器是位在雲端的運算陣列中,而為邊緣伺服器建構的不同等級之AI加速器則稍有不同,這類邊緣運算也被市場視為較具有成長潛力。
第三類邊緣運算包括執行各項有特定功能的聚合器(Aggregator)與閘道(Gateway),可能僅以最小的延遲與最低的電力消耗運作一個或幾個應用程序。
這三類邊緣運算均已被界定為支援實際的應用程序。例如McKinsey已有107個使用案例的邊緣運算分析。ETSI透過其群組規範MES 002 v.2.1.1對5G MEC界定超過35個的使用案例,包括用於遊戲、服務層級協議、影片快取、虛擬實境、流量重複刪除等。此等應用程序的每一項應用均有基於該邊緣伺服器中的預先界定之延遲要求。
OpenStack基金會為另一個將邊緣運算納入其工作的組織,加上將中央辦公室(Central Office)重新架構為一個資料中心(CORD),其中分布在整個網路中的傳統電信辦公室,現在則由邊緣雲端伺服器主控。
5G市場的案例通常需要自邊緣裝置至邊緣伺服器,再回到該邊緣裝置的延遲往返(Latency Roundtrip)可以達1ms。達成此目標的唯一方式必須藉由一個本地閘道或聚合器,因為通過至該雲端的全程通常需要100ms。而在2019年秋天所發布的6G方案,其延遲目標則為僅數十個μS。
每一邊緣運算系統均支援一個類似的SoC架構,包括一個網路SoC、一些儲存、一個伺服器SoC,以及一個AI加速器或AI加速器陣列。各類型之系統均提供其本身的網路延遲、電力消耗與功能級別。而圖6中則說明此類系統的一般準則。市場瞬息萬變,隨著科技的進步,這些數字可能也會快速變化。
邊緣運算加速AI/降低系統延遲
許多邊緣運算應用的主要目標都是在於提供較低網路延遲之相關新型服務。為支援較低延遲,許多新的系統採用最新的工業介面標準,包括PCIe 5.0、LPDDR5、DDR5、HBM2e、USB 3.2、CXL、基於PCIe的NVMe,與其他基於各種科技的新標準。與上一代相比,這類科技均透過改良頻寬,實現較低的網路延遲。
另一個減少延遲的方法則是設法為邊緣運算系統提升AI加速(AI Acceleration),也就是說,經由某些具有新指令的伺服器晶片使AI加速。例如x86擴展AVX-512向量神經網路(AVX512 VNNI)。很多時候此種額外的指令集不足以提供預期任務所需實現的低延遲與低電力,因此會將AI加速器添加至大多數新的系統中。這類晶片所需的連通性通常採用高頻寬的主機以盡可能地達到加速器連通性。例如正在迅速擴展中的PCIe 5.0,由於其頻寬需求會直接影響延遲,因此常在某些交換結構配置多個AI加速器。
CXL是為降低延遲並提供快取一致性(Cache Coherency)而特別建構的一種介面。由於AI演算法的異構運算需求與大量記憶體的要求,因此快取一致性就顯得非常重要。 除本地閘道與聚合伺服器系統之外,單一的AI加速器通常無法提供足夠的功能,因此需要具有高頻寬的晶片至晶片(Chip-to-chip)的SerDes PHY以縮放此等加速器。最新發布的PHY支援56G與112G的連接;對支援AI縮放的晶片至晶片要求,也有許多不同的實現方式。乙太網路可能為在一個基於標準而實現的一個選項,其他則為利用具有專用控制器的可能頻寬的SerDes。不同的架構可能會改變伺服器系統的SoC架構,以納入網路、伺服器、AI與儲存元件於整合的SoC,相對當前將四種不同的SoC中有所不同(圖7)。
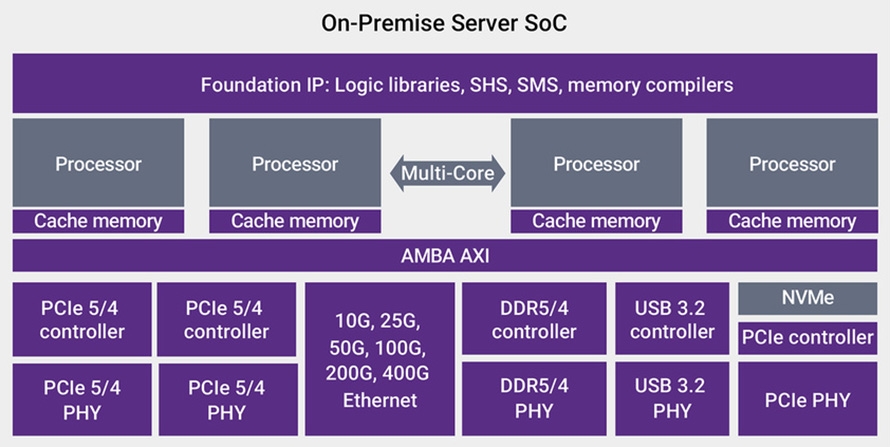 圖7 在通用伺服器SoC之邊緣處,具有基於各項任務、電力、延遲與其他需求的處理器數量、乙太網路傳輸量與儲存能力之變化度
圖7 在通用伺服器SoC之邊緣處,具有基於各項任務、電力、延遲與其他需求的處理器數量、乙太網路傳輸量與儲存能力之變化度
AI演算法正在推動對於記憶體頻寬要求的演進。舉例而言,最新的BERT與GPT-2型號分別要求345M與1.5B的參數,明顯的需要高容量的記憶體能力,以便能執行主控運算以及在該邊緣雲端中執行複雜的應用程序。為支援這樣的功能需求,設計人員正在為新晶片組採用DDR5。除容量的挑戰外,尚須存取在非線性順序中、並行完成多次巨大數量的AI演算法之各項係數。而當前最新科技HBM2e,便是快速採用在每一晶粒進行眾多演算(圖8)。
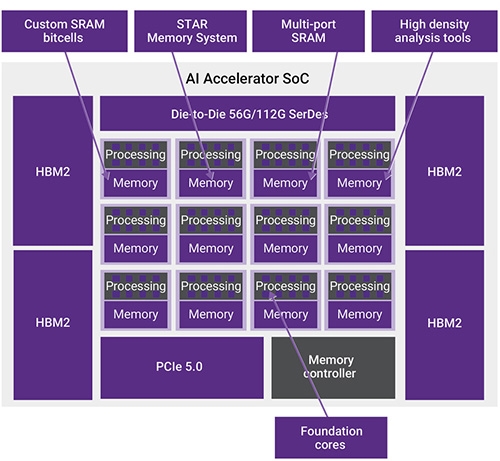 圖8 具有高速、高頻寬、記憶體、主機至加速器與高速晶粒至晶粒介面的AI SoC,可縮放多個AI加速器
圖8 具有高速、高頻寬、記憶體、主機至加速器與高速晶粒至晶粒介面的AI SoC,可縮放多個AI加速器
移動目標與邊緣運算區隔
若更仔細地研究邊緣運算需求的類型,可以發現到區域性的資料中心、本地伺服器與聚合閘道具有不同的運算、延遲與電力需求。這些要求明顯地集中在降低往返回應(Round Trip Response)的延遲、降低特定邊緣應用程序的電力,並確保有足夠的處理能力以處理特定的任務。
伺服器SoC所消耗的電力會依照延遲與處理的要求而有所差異。新一代的解決方案不僅可以降低延遲與降低電力,還包括提升AI的能力,特別是AI加速器。這類AI加速器的功能也會依據需求而有所變化。
AI與邊緣運算的要求正在進行快速的變化,人們今日看到的許多解決方案,在過去二年已多次演進,未來也將持續這樣進行(圖9)。可嘗試將當前的功能分類,但類別的數量應會持續變動、包括提升功能、降低電力,並降低整體延遲等等。
 圖9 有了新一代伺服器SoC與AI加速器,可進而促進高效邊緣運算
圖9 有了新一代伺服器SoC與AI加速器,可進而促進高效邊緣運算
邊緣運算為實現更快互通性(Connectivity)的關鍵環節,它可以讓雲端服務更接近各類的邊緣裝置,提供消費者新的應用程序與服務並降低延遲,並快速提升AI能力,甚至將AI運算自雲端中移出;同時它也是實現未來混合運算的基礎技術,可依據延遲需求、電力需求與整體儲存及功能需求,在該雲端中或特定的裝置處,就地即時做出運算判斷。
(本文作者為新思科技產品行銷經理)