近年人工智慧物聯網(AIoT)發展如火如荼展開,包含車聯網、智慧穿戴、智慧建築與智慧家庭等與物聯網相關的應用範疇,對於人工智慧(AI)的需求更是與時俱增,可看到嵌入式處理器AI化的進展速度飛快,無論是矽智財(IP)或晶片廠商皆大舉投入其中,全力搶進AIoT帶來的龐大商機。
從2018年開始,AI相關的技術與應用積極由雲端擴展至終端,不論是智慧手機、監控系統、物聯網、無人機、車載系統等終端裝置,已經無須透過網路與雲端,便能於裝置進行即時性的AI運算與判讀,做出專屬性或小規模的判別與應用。這些預先經由大量機器學習訓練與算力演繹的邊緣運算,將透過各式各樣的智慧裝置進入日常生活與工作環境之中。
恩智浦(NXP)微控制器暨微處理器大中華區市場行銷經理弋方(圖1)表示,從晶片角度而言,受惠於各種不同AIoT邊緣運算的應用發展,特別是語音和人臉辨識需求的升溫,MCU和MPU市場持續保持穩定成長的態勢,而這之中,成長的動力來自於AI運算能力的強化。
 圖1 NXP微控制器暨微處理器大中華區市場行銷經理弋方表示,處理器運算能力的提升,進一步帶動AIoT發展速度。
圖1 NXP微控制器暨微處理器大中華區市場行銷經理弋方表示,處理器運算能力的提升,進一步帶動AIoT發展速度。
邊緣運算正夯 AI MCU/MPU陸續登場
相較於去年邊緣運算發展,主要還是較仰賴於雲端進行資料處理,也就是將本地取得的圖片或音訊資訊,上傳至雲端進行推論,再將結果回傳至邊緣,2019年邊緣運算最大的不同,就是更聚焦於在邊緣進行即時、安全又可靠的數據處理,而這也意味著終端裝置對於邊緣運算的能力有更進一步的要求。基於此,MCU和MPU的市場隨之快速成長,協助各種裝置在邊緣進行運算。
弋方談到,各種運用對於運算能力要求的增加,具備AI能力的MCU和MPU已成為潮流之下不可或缺的關鍵重點,而打造這類型的晶片可從三個面向著手。首先,晶片本身擁有低功耗、高效能、高安全與通訊能力是基本要求;其次,需要具備AI演算能力,意指在晶片內部增加DSP或神經網路加速器的加速單元,進一步提升運算速度;最後則是要有一整套的軟體開發套件,提供終端開發商良好的開發環境,使其得以容易將現有AI模型移植到MCU或MPU,滿足相關的應用需求。
呼應上述邊緣運算對於MCU和MPU效能及AI化的需求,NXP不僅在硬體本身強化其效能,同時亦於軟體端提供相對應的開發套件e.IQ方案,滿足各種對於人工智慧的應用需求(圖2)。
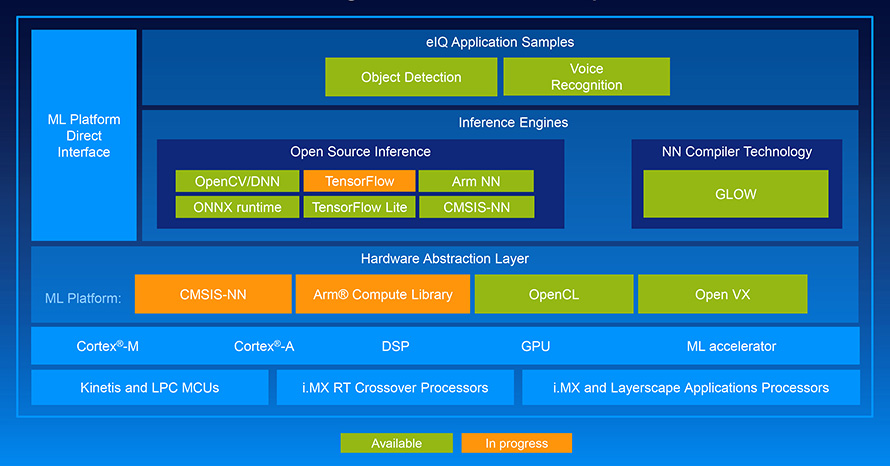 圖2 e.IQ機器學習軟體開發環境
圖2 e.IQ機器學習軟體開發環境
資料來源:NXP
弋方強調,人工智慧服務不僅須強化軟硬整合的實力提供完整的解決方案,與雲服務商合作也是成就AI方案的重要一環。現階段NXP已與亞馬遜(Amazon)、微軟(Microsoft)、阿里巴巴、百度、騰訊與京東等雲服務商皆有深度的策略合作,由雲服務商提供服務人力與終端產品應用入口,晶片商則是密切跟進雲端業者回應的終端需求,進而提供迎合低功耗、高效能與高運算能力需求的晶片,從而達成雙贏的局面。
發揮AI綜效 晶片/雲服務商攜手合作
舉例來說,於行動支付應用中不外乎需要進行人臉和物品辨識功能,再透過雲端服務形成最後的交易。通常購買物品時,會針對購買物品的品項、價格進行辨識,而後透過人臉辨識系統執行支付行為,而這些本地端的辨識要求高的即時性、高安全性且對能效比要求較高,主要由晶片商提供相關解決方案;而後端進行最後交易確立的行為,則必定由騰訊、支付寶或微信這類型的雲服務商所提供,故此模式就形成端和雲的互補作用。
弋方透露,NXP不僅在邊緣有AI的MCU與MPU解決方案,同時亦有部分像是EdgeScale可以放在雲端的框架解決方案。從行動支付應用場景中,雲服務廠商可能會提供一些金融、物流服務等其他服務,但以終端設備商角度來看,只有終端設備業者對於自身的設備、晶片最瞭如指掌,故NXP在雲端運行一個EdgeScale的框架,強化邊緣與雲服務廠商服務的深度結合,更便於其服務對邊緣端NXP的MCU與MPU相關設備進行操作與管理。
布局AIoT 瑞薩四等級分頭進行
另一方面,同樣具備提供AI MCU和MPU的廠商瑞薩(Renesas),在AIoT應用則是採取Class 1~Class 4四個等級的規畫藍圖循序漸進,藉由e-AI軟體開發工具作為基底,滿足瑞薩旗下MCU與MPU人工智慧效能(圖3)。
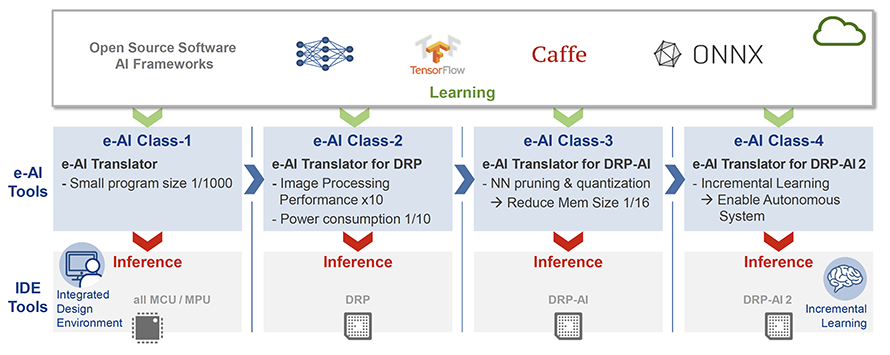 圖3 建立在e-AI之上,工具鏈將與AI加速器DRP共同演進
圖3 建立在e-AI之上,工具鏈將與AI加速器DRP共同演進
資料來源:瑞薩
瑞薩物聯網暨基礎設施事業本部市場行銷部經理黎柏均(圖4)表示,AIoT應用已成為眾所注目焦點,其中嵌入式系統占很重要角色,尤其是終端設備對於MCU的選用非常重視,MCU的生態系及在不同應用場域的適用性,都是未來MCU選型上的重點,也因此瑞薩將人工應用方案分為四種等級,對應各種不同應用需求。
 圖4 瑞薩物聯網暨基礎設施事業本部市場行銷部經理黎柏均談到,MCU的生態環境與實際應用場域的不同,將影響設備商MCU選用。
圖4 瑞薩物聯網暨基礎設施事業本部市場行銷部經理黎柏均談到,MCU的生態環境與實際應用場域的不同,將影響設備商MCU選用。
整體而言最成熟的方案也就是嵌入式AI Class 1,該等級的AI應用聚焦於影像、比對上面的應用,透過AI做快速判斷,再運用神經網路學習建立模型,而此模型如何執行到MCU上,為目前晶片業者著重的重點。基本上瑞薩嵌入式AI被定義為最初級軟體層Class 1方案,此方案採用瑞薩e-AI(Embedded Artificial Intelligence)解決方案。
黎柏均指出,e-AI適用於瑞薩旗下所有嵌入式MCU,透過瑞薩e-AI Translate Tool環境,將終端設備已經學習完的神經網路模式轉換成瑞薩MCU的機械碼(Machine Code),實際可執行在該公司旗下所有MCU晶片。
接下來Class 2則是屬於MPU等級處理器,內建e-AI和DRP(Dynamically Reconfigurable Processor)進行即時影像處理與影像前處理等功能,同時整合Cortex A9 CPU核心執行神經網路分類,目前大多應用於人臉辨識、虹膜辨識等生物辨識應用。
上述Class 1~Class 2皆已廣泛運用於市場當中,協助各種應用強化資料判讀的效果。黎柏均透露,下一步Class 3階段,瑞薩將導入DRP的AI引擎,透過IP整合方式進行AI加速,效能將超越GPU與NPU,預計2020年上半年將推出樣品,年底進行量產,該方案主要強調功耗可持續保持非常低。至於Class 4則發展於更遠的未來,預期會採用第二代DRP加速引擎,其效能將更勝於以往。
黎柏均談到,瑞薩現階段布局MCU朝兩個路線進行,一是更加微型化,針對數位類比轉換搭配感測器應用為主,也就是目前傳統MCU所執行的應用,主要聚焦於更低功耗,採用類比IP技術;另一部分則是針對某些IoT場域,其市場與技術要求更優異的運算能力,例如工業應用類型需要實際運算能力進行資料分類,避免影響到所有資料到雲端導致網路塞車問題,在此前提下,邊緣端須具備良好運算與識別能力,以進行趨勢分析與二次學習,諸如AI邊緣運算應用。
在AI判斷過程中已經自動分類邊緣場域判斷,再由雲端伺服器做二次學習,亦即分層學習,故CPU都須要具備AI執行能力。整體而言,在AI應用上對於感測器資料輸出正確性要求較高,MCU或MPU須處理、蒐集大量感測器資料,辨別原本雲端判斷模式與評分模式沒辦法定義分類的差異。
全新Armv8.1-M架構獻計 高整合MCU ML擦新火花
Arm應用工程總監徐達勇(圖5)表示,邊緣運算技術逐漸明朗,許多像是人臉辨識、語音辨識應用須結合許多感測器資訊,在邊緣端由推論(Inference)引擎蒐集並簡單進行資料分析,因此MCU需要提升運算力使其具備邊緣智慧的能力。
 圖5 Arm應用工程總監徐達勇表示,目前大多AI MCU方案採用一顆Cortex M結合DSP方案,但亦可以單一Cortex M7滿足AI需求。
圖5 Arm應用工程總監徐達勇表示,目前大多AI MCU方案採用一顆Cortex M結合DSP方案,但亦可以單一Cortex M7滿足AI需求。
以技術發展看來,從晶片層面再往內部核心IP層深入探討,現階段晶片核心運算能力在架構上基本上會需要一顆Cortex-M外加一顆DSP,或使用更高階Cortex-M7(本身即內建DSP,無須外加一顆加速器),實現具備AI功能的MCU晶片設計(圖6)。
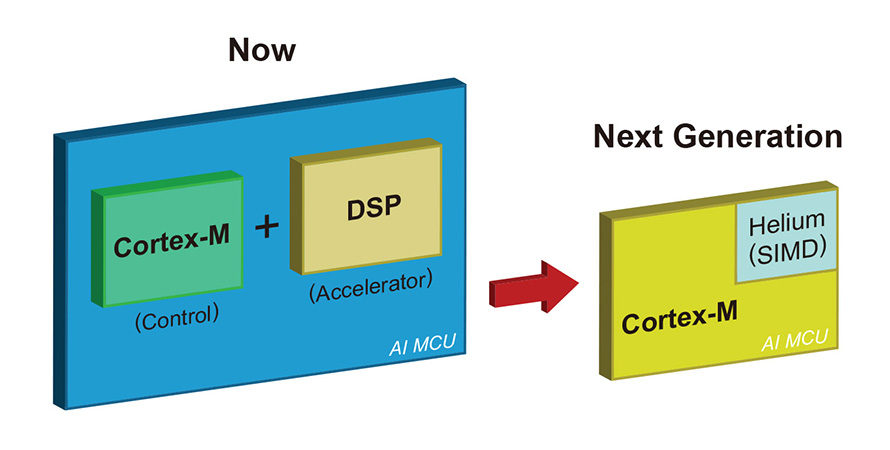 圖6 現階段AI MCU方案與下一代搭載Helium架構的AI MCU方案比較。
圖6 現階段AI MCU方案與下一代搭載Helium架構的AI MCU方案比較。
資料來源:新通訊、Arm
針對功能受到最多限制的嵌入式系統,能源效率是最優先考量的因素,其採用的解決方案以往都是用一顆Cortex處理器搭配SoC晶片內的DSP處理器,然而這種作法也增加硬體與軟體設計的複雜度。Arm希望在這些裝置上納入更多機器學習功能,使得現有的SoC開發難題變得更加艱鉅,因而需要更高深的專業技術才能運用不同的工具鏈、撰寫程式、除錯以及運作於各種複雜的專利式安全解決方案。
為了有效提升未來基於Cortex-M處理器裝置的機器學習與訊號處理效能,Arm於2019年年初推出基於Cortex-M系列處理器打造的Helium架構,讓在TrustZone安全基礎上運行的Armv8.1-M架構能夠提高運算效能。
Armv8.1-M與Helium的組合能克服上述這些難題,不僅帶來即時控制程式碼、機器學習與DSP執行能力,而且效率絲毫不減。這讓數百萬軟體開發者得以運行各種DSP功能,安全無虞地擴展各種智慧程式到種類更廣泛的裝置,強化對三種關鍵類別新興應用的支援:振動與動態、語音與聲音、以及視覺與影像處理。這些新一代基於搭載Helium技術的Cortex-M架構SoC將改進未來各種裝置的使用者經驗,包括感測器中樞設備(Sensor Hub)、穿戴裝置、音效裝置、工業應用等。
DSP現已透過Neon技術擴展至更多Cortex-A架構元件。針對功能受限的應用,Arm亦在旗下較高效能的Cortex-M處理器(包括Cortex-M4、Cortex-M7、Cortex-M33以及Cortex-M35P)加入DSP擴充方案。兩種技術都可用來加速特定應用的機器學習運算。
徐達勇解釋,Heilum是一個SIMD架構引擎,相似於Cortex-A系列行之有年的Neon架構,只是針對Cortex-M系列訴求低功耗、低運算的能力,重新定義新一代的SIMD架構。在未來的新一代Cortex-M處理器中,將搭載Heilum架構提供達15倍的機器學習效能以及提升5倍的訊號處理效能,協助晶片商發掘眾多新市場商機。
此外,Helium統一的工具鏈、函式庫、以及模型等資源將讓軟體開發流程更為簡化。Helium工具鏈包含Arm Development Studio,附有Arm Keil MDK套件、Arm Models模型(開發者能立即用在程式碼建模)、以及各種軟體函式庫,包括CMSIS-DSP以及CMSIS-NN在內,讓開發者能依據自己需求挑選適合方案。
AI應用百花齊放 嵌入式核心搭配百百種
如同上述所言,因應各式各樣的AI應用,晶片商內部所搭載的嵌入式方案核心也各有不同。有些廠商採用雙核、四核的解決方案滿足所需的應用,而有些廠商則採用高階單個MCU處理器(如Cortex-M7)實現AI應用,甚至是面對更高階類型的AI應用,採用MPU類型的處理器,內部則採用Cortex-A系列搭配NPU、DSP或其他加速器,達成人工智慧方案。
究竟處理器核心應該如何選用呢?徐達勇分析,嵌入式方案可分成兩種類型,一種為要求即時性、低功耗的MCU方案,另一種則是屬於Rich嵌入式方案,類似於IP Cam應用要處理大量的影音圖像資料,須具備電腦視覺運算能力,並運行於Rich OS系統,本身須具備記憶體管理單元(MMU)功能,故有時會採用Cortex-A32或Cortex-A35等級的方案。
徐達勇談到,通常Rich嵌入式大多採用多核心解決方案,如雙核或四核。有些架構採用Cortex-M系列進行控制,Cortex-A系列進行運算功能;相反的,多核架構應用於MCU設計上則還在少數,部分記憶體應用採取這類型方案,但整體而言,MCU主要還是以運算能力的提升為首要目標,運算能力的強弱不會與核心數量成正比,例如未來搭配Huilum架構的Cortex-M,單一核心即能取代雙核架構。
弋方補充,MCU主頻也越來越高,可以到600~800MHz甚至更高,而MPU也朝著低成本與低功耗的設計,這兩者技術界線愈趨模糊。以晶片商角度來看,主要從作業系統與記憶體容量進行區隔,MPU產品設計也就是Rich嵌入式方案,支援MMU所以記憶體可以透過外接的方式擴增,例如可以外接DDR3、DDR4記憶體,並運行於Linux或Android作業系統,執行較複雜的系統運作。而MCU則是強調處理能力,記憶體較小且沒有MMU,主要聚焦於對即時性、低功耗要求更高的應用。一般而言,MCU記憶體約1MB左右;而MPU則是100MB起始,甚至高達4GB。
徐達勇透露,為了協助產業加速AI應用發展,該公司日前已宣布將推出新的NPU,預計2020年年初將會看到NPU相關產品,未來將可能有Cortex-M+NPU或Cortex-A+NPU類型產品面市。不過這還是非常初期階段,由於現今NPU尚未標準化,軟體與相關配套資源尚未完整,故目前MCU晶片商會採用通用型IP,如CPU、GPU或DSP等方案使用彈性較高,僅針對一些對於效能與功耗要求較高的特殊應用,採用NPU進行高速運算的機會就比較大。
弋方表示,MCU和MPU的AI化現今還處於萌芽到成熟階段的過渡期,但成長速度非常快,目前該公司合作廠商的產品都已進入即將量產階段,預估2020年將是AIoT成長爆發的一年,而主要應用來自於語音與人臉辨識的推動。