穿戴式裝置風潮持續擴散,為使穿戴裝置運算更加智慧,滿足未來各種多元應用,已有研究單位採用深度學習技術,加強穿戴式裝置影像/動作分析、辨識能力,提供更智慧化服務,滿足消費者需求。
穿戴裝置的市場需求持續增溫,根據市場研究機構CCS Insight之報告(圖1),整體穿戴裝置之銷售量在2020年將超過到四億部,預估產值將達到342億美金。其中銷售數量最高的預期將是智慧手環,其次則為智慧手錶與AR/VR智慧眼鏡。AR/VR智慧眼鏡雖然在2020年預估之銷售量僅智慧手環之一半,但其產值貢獻將最高,預估達到145億美金。
 |
| 圖1 Global Wearable Forecast, 2016-2020。 |
許多穿戴裝置,如:智慧手環、智慧手表、智慧眼鏡、或是智慧運動鞋等,都內建有能偵測裝置運動狀態(如加速、旋轉等)之動作感測器(IMU)。透過分析解譯穿戴裝置之動作感測器資料,將能辨識使用者當下之動作內容,進而發展各式各樣之智慧穿戴服務,如久坐偵測、步伐分析、跌倒偵測、健身教練等。
分析解譯穿戴裝置之動作感測器資料的關鍵技術之一為深度學習技術,本文將簡介深度學習技術以及其應用於動作辨識之可行性,期望能讓使用者對於深度學習技術在穿戴裝置之應用潛力能有進一步之瞭解。
深度學習技術源起
從1943年Warren McCulloch最早的人工智慧研究論文,1956年夏天達特茅斯學院(Dartmouth College)的一場會議中「人工智慧」(Artificial intelligence, AI)這名詞誕生,人類製造智慧機器的目標一路走來已經超過半個世紀。人工智慧領域曾經經歷過數次所謂的「冬天」(AI Winter)。在2016年,一場在南韓舉辦的棋賽,Google在2014年所收購的公司Deepmind,其研究團隊發展出來的圍棋程式AlphaGO成為史上第一支於公開場合,不讓子的狀況下成功以4-1打敗人類職業棋士的電腦圍棋程式。寫下了歷史。
AlphaGO成功的關鍵之一是,它在蒙地卡羅樹搜尋(Monte Carlo Tree Search, MCTS)這個近年來使棋類程式棋力出現明顯進展的演算法上,結合這幾年機器學習領域的顯學方法-深度學習(Deep Learning),使電腦圍棋程式突然間從業餘等級趕上甚至超越了職業頂級棋手的棋力。這場勝利使許多人好奇,究竟何謂深度學習?
要了解所謂的深度學習,須要先了解類神經網路(Neural Network)。因為現今談到所謂的深度學習,大多指一種基於類神經網路(Neural Network)發展出來的機器學習模型。類神經網路的基本架構是一個人工神經元(Neuron)。有一個輸入,一個輸出。神經元根據輸入進行簡單的運算後產生輸出。如圖2所示。
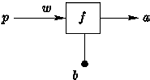 |
| 圖2 輸出a= f(p.w+b) |
圖2是一個單一輸入單一輸出的人工神經元節點。其所做的計算很簡單。根據輸入p,計算p.w+b之後,代入函數f,得到輸出a。w和b都是這個節點的參數,為此模型中需要進行「學習」(根據資料來修改數值)的部分。f是一個事先決定好的活化函數(Activation Function)。進一步擴充,我們也可以定義多個輸入一個輸出的神經元模型。
類神經網路模型以上述單一人工神經元節點為基礎。將多個節點合併建造出「網路」架構。以圖3為例。這個模型左方定義了一個單層m輸入n輸出的類神經網路。右方則是另一新的n輸入k輸出的單層類神經網路架構。左方的n個輸出接到這個新的n輸入的單層類神經網路上。
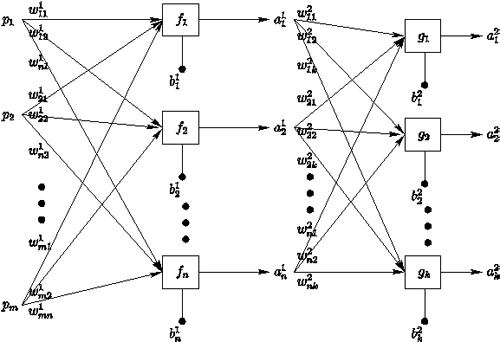 |
| 圖3 兩個單層多節點的網路結合而成的多層類神經網路。連結多個單層結構形成多層網路模型,可形成有「深度」的模型。 |
這個夾在中間的n輸入k輸出神經網路架構,以前一層運算輸出做為其輸入,計算後輸出整個模型的運算結果。在類神經網路架構上稱為隱藏層(Hidden Layer)。若是重複上述步驟,可形成多層類神經網路架構。
提升影像辨識能力 卷積/池化運算不可少
回到原題。何謂深度學習?簡單而言,深度學習在類神經網路架構上就是一個有多層架構的網路模型。以類神經網路架構為代表,此種將許多可以進行簡單運算的基本單元連接,以模擬智慧行為的方法一直是研究者們嘗試實現人工智慧的主要研究方向之一。
但類神經網路早期因為電腦硬體能力,眾多參數需要較多資料樣本作調整,以及參數最佳化演算法的技術問題,一直沒有太突出的表現。加上Hornik等研究者在1989年發表的論文,證明了單一隱藏層的類神經網路可逼近任何多變數的連續函數,因此除少數例外,早年研究者較少探討多層架構。直到近年GPU及硬體計算能力的進展,有利於大量資料及分散式計算的雲端計算技術的出現,加上最佳化演算法的問題有所突破,終於又重新嶄露頭角。
深度學習中最有名的卷積神經網路(Convolutional Neural Network, CNN)概念來自貓的視覺神經細胞以階層形式運作的假說。由Hubel及Wiesel在1968年提出。目前已知最早據此建立的模型是1979年日本人Fukushima所提出的神經網路模型--Neocognitron。現行的CNN則主要是LeCun等人所提的LeNet。CNN在輸入層之後有兩種神經細胞層,分別執行卷積(Covolution)以及池化(Pooling)運算。應用在影像辨識問題上,卷積運算將一張影像切割為多個局部影像,每個節點針對局部影像進行運算。
舉例來說,假設原始影像大小為m×n,所設定要擷取的局部影像單張大小為r×r。一種可能的做法是將r×r的正方形由原始影像左上角開始,每次往右位移一個單位,到最右方之後回到最左方,但往下位移一個單位。如此反覆進行,直到覆蓋到整張影像為止。執行卷積運算的每一個節點對一個局部影像進行運算,產生輸出給下一層。
圖4是最左上方的節點在一個3×3的局部影像中進行運算的例子。卷積運算之後通常會進行的運算為池化運算。上一層卷積運算的輸出可視為一新影像。在此新影像上,可設定另一局部影像,大小可與前一層局部影像無關。
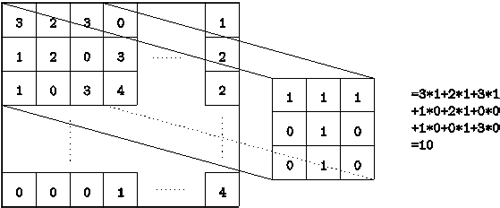 |
| 圖4 卷積(Convolution)運算的例子。局部影像大小須先設定,右方3×3方陣上對應原圖位置的數值可由演算法訓練進行調整。 |
根據在此局部影像內的資料進行池化運算。常見的池化運算例如在所有輸入資料內取最大值,或是計算平均值等等。池化運算完的結果可再傳給下一層進行卷積運算,然後再進行池化運算。反覆數次之後,最後的輸出便拿來作為一個分類器的輸入,進行影像辨識。
改良D-CNN演算法 穿戴式裝置動作辨識準確度大增
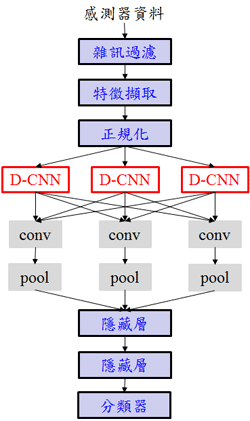 |
| 圖5 D-CNN動作辨識模型架構,其中Conv代表卷積(Convolution),Pool代表池化(Pooling)。 |
深度學習至今已在電腦視覺及語音識別等領域,取得領先地位。例如Google Brain完成了辨識影像中的「貓」、ImageNet進行照片辨識、TIMIT之語音辨識等成功案例,皆說明深度學習已相當成功。然而,截至目前為止,應用深度學習來處理動作感測器(IMU)訊號,由於不易擷取良好特徵、資料差異變化較大,仍有相當之難度。
有鑑於智慧手錶或智慧手環之應用將越來越普及,分析源於智慧手錶等穿戴裝置之動作感測器訊號,以理解使用者之動作狀態等應用需求將越來越高,資策會智通所嘗試對深度學習中的卷積神經網路架構進行改良,在分層架構中導入統計模型形成一個動態式之卷積神經網路(Dynamic CNN,或稱為D-CNN),並引入訊號關聯性的架構對卷積神經網路進行改良,以提升精確度,如圖5。
圖5為D-CNN動作辨識模型架構,包含收到感測器時間序列原始資料後所須進行之雜訊過濾、特徵擷取、正規化等動作,以及進入D-CNN模組後的多層卷積網路運算,以及經過訓練生成的分類器(Classifier)等,在卷積網路之多層架構
中進行改良,以協助其擷取更具代表性之
特徵。
本研究使用一項在學術界公開使用之動作資料庫Wearable Human Activity Recognition Folder(WHARF)進行實驗,該動作資料庫中包含十四種透過感測器所收集的日常生活動作加速度感測器訊號資料(表1),感測器的取樣頻率為32Hz,首先將資料以八十筆資料為一組,兩組資料50%重疊的方式取出,每類取一百二十筆做訓練,其餘做測試。
將D-CNN演算法與傳統機器學習方法對同樣的WHARF資料進行分析,發現經過改良處理之D-CNN演算法,辨識率有大幅度的提升,整體辨識率改善比率約為10%。由此研究成果,研究者相信應用深度學習技術解析辨識穿戴裝置使用者之動作行為未來將大有可為。
深度學習使穿戴式裝置更智慧
透過深度學習等技術將賦予穿戴裝置某種程度的智慧運算能力,提供使用者更便利有效率的生活。在硬體運算能力與網路技術進步之促進之下,相信在不久的將來,穿戴智慧服務將會百花齊放,而協助服務開發者快速建立智慧服務之智慧運算平台的角色將越來越重要。資策會智通所正投入研發符合穿戴裝置需求之智慧運算學習服務平台(Learning as a Service),期望協助穿戴服務開發者發展合適其智慧運算需求的辨識模型,競逐智慧穿戴服務之龐大商機。
(本文作者皆任職於財團法人資訊工業策進會智慧網通系統研究所)