行動裝置上的人工智慧已經不再依賴於雲端連接,2018年CES最熱門的產品展示和最近發布的旗艦智慧手機都證實了這一觀點。人工智慧已經進入終端裝置,並且迅速成為一個市場賣點。包括安全、隱私和回應時間在內的種種因素,使得該趨勢必將繼續擴大到更多的終端裝置上。為了滿足需求,幾乎每個晶片產業的廠商都推出了不同版本、不同命名的人工智慧處理器,像「深度學習引擎」、「神經處理器」與「人工智慧引擎」等等。
然而,並非所有的人工智慧處理器都是一樣的。現實是,許多所謂的人工智慧引擎就是傳統的嵌入式處理器(利用CPU和GPU)加上一個向量處理單元(VPU)。VPU單元是專門為高效執行與電腦視覺及深度學習相關的繁重計算負載而設計的。雖然擁有一個強大、低功耗的VPU是嵌入式人工智慧的重要組成部分,但這不是全部。VPU雖然經過精心設計,也確實提供了所需的靈活性,但它不是一個AI處理器。還有一些其他功能對於人工智慧處理前端化至關重要(圖1)。
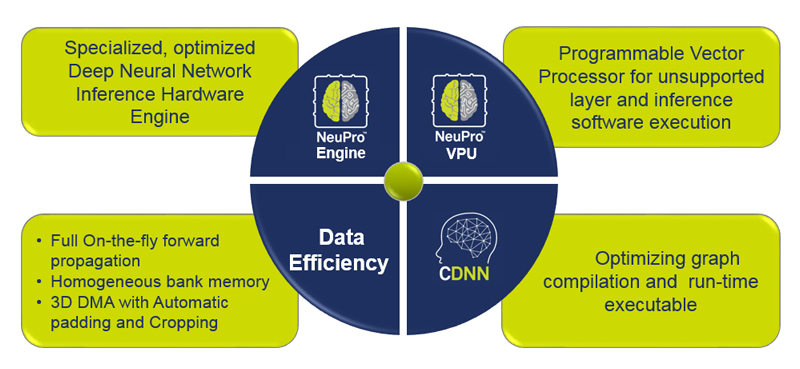 圖1 NeuPro為一種人工智慧(機器學習)整體解決方案。
圖1 NeuPro為一種人工智慧(機器學習)整體解決方案。
圖片來源:CEVA
優化嵌入式系統工作負載
在雲端運算處理過程中,採用浮點運算進行訓練,定點運算進行推理,從而實現最大的準確性。用大型伺服器群組進行數據處理,功耗和大小雖必須考慮,但相較於有邊緣約束的處理能力幾乎是無限的。在行動裝置上,功耗、性能和面積(PPA)的可行性設計至關重要。因此在嵌入式SoC晶片上,優先採用更有效的定點運算。當將網路從浮點轉換為定點時,會不可避免的損失掉一些精度。然而正確的設計可以最小化精度損失,可以達到與原始訓練網路幾乎相同的結果。
控制精度的方法之一是在8位和16位整數精度之間做出選擇。雖然8位精度可以節省頻寬和運算資源,但是許多商用的神經網路仍然需要採用16位精度以保證準確性。神經網路的每一層都有不同的約束和冗餘,因此為每一層選擇最佳的精度非常重要(圖2)。
 圖2 以層為單位選擇最佳精度。
圖2 以層為單位選擇最佳精度。
圖片來源:CEVA
針對開發人員和SoC設計者,一個工具可以自動輸出優化的圖形編譯器和可執行檔,例如CEVA網路生成器,從上市時間的角度來看是一個巨大的優勢。此外,保持為每一層選擇最佳精度(8位或16位)的靈活性也是很重要的。這使每一層都可以在優化精度和性能之間進行權衡,然後一鍵生成高效和精確的嵌入式網路推理。
專用硬體支援AI演算法
VPU使用靈活,但許多最常見的神經網路需要的大量頻寬通道對標準處理器指令集造成了挑戰。因此,必須有專門的硬體來處理這些複雜的計算。例如NeuPro AI包括專用的引擎處理矩陣乘法、完全連接層、啟動層和匯聚層。這種專用AI引擎結合完全可編程工作的NeuPro VPU,可支持所有其他層類型和神經網路拓撲。這些模組直接連接允許數據無縫交換,不再需要寫入記憶體。此外,優化的DDR頻寬和DMA控制器採用動態流水線處理,可以進一步提高速度,同時降低功耗(圖3)。
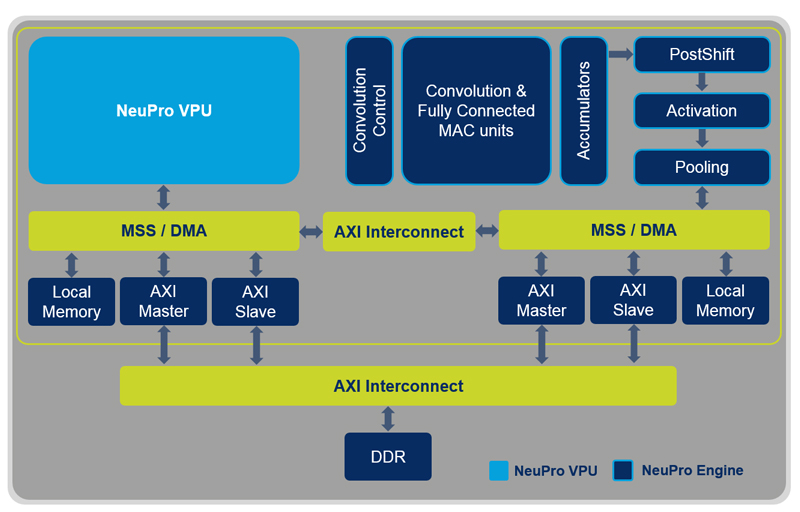 圖3 結合NeuPro引擎和NeuPro VPU的NeuPro AI處理器框圖
圖3 結合NeuPro引擎和NeuPro VPU的NeuPro AI處理器框圖
圖片來源:CEVA
保持「聰明」 行動AI戰火開打
人工智慧仍然是一個新興且快速發展的領域。神經網路的應用場景快速增加,例如目標識別、語音和聲音分析、5G通訊等等。保持一種適應性的解決方案滿足未來趨勢是確保晶片設計成功唯一的途徑。因此,滿足現有演算法的專用硬體肯定是不夠的,還必須搭配一個完全可編程的平台。在演算法一直不斷改進的情況下,電腦模擬仿真是基於實際結果進行決策的關鍵工具,並且加速產品上市時間。CDNN PC仿真套件允許SoC設計人員在開發真實硬體之前,預先使用PC環境權衡自己的設計。
另一個滿足未來需求的寶貴特徵是可擴展性。NeuPro AI產品家族可以應用於廣泛的目標市場,從輕量型的物聯網和可穿戴裝置(2TOPs)到高性能的產業監控和自動駕駛應用(12.5TOPs)。
在行動端實現旗艦AI處理器的競賽已經開始。許多業者快速趕上此趨勢,使用人工智慧作為自己產品的賣點,但並不是所有產品都具備相同的智慧水準。如果想要創建一個在不斷發展的人工智慧領域保持「聰明」的智慧裝置,應該確保在選擇AI處理器時,檢查上述提到的所有特性。
(本文作者為CEVA產品行銷總監)