因應大數據潮流下,人工智慧邊緣運算的趨勢興起,進一步驅動各大晶片商積極投入AI晶片研發,如英特爾(Intel)、聯發科、耐能與寒武紀等廠商,皆有相關解決方案,且為了滿足多元化應用,AI晶片設計更是朝多元分眾的方向邁進。
2012年夏天,Google發布透過深度學習可以辨識影片中的貓,但其硬體是透過16,000個處理器,連接超過10億個神經網路,因此很難大規模地部署及應用。但當2016年Google AlphaGo擊敗人類圍棋棋王,創造人工智慧發展的空前突破,使沉寂多年的人工智慧再度吸引全球關注。人工智慧的發展受到資料處理、演算模式、硬體效能、應用需求等因素驅動,因近期深度學習技術出現突破性進展,使人工智慧在圍棋對弈取得重大勝利,引起各界再次關注。
如果說人工智慧的發展前期主要集中在雲端(Cloud),那麼接下來的發展趨勢將會往終端(Edge)轉移。這個轉移有四大好處,第一是終端的回應速度大大提升,比如針對一些車載系統的智慧應用,如ADAS應用,如果通過雲端運算處理,再把資料從雲端傳回來的速度會比較慢。第二是如果把資料放到雲端,隱私也非常容易暴露。第三是目前的上傳流量資費成本也很高。第四是相對伺服器端,終端的功耗會更低。實際上目前雲端伺服器的用電量已經達到全球電力的5%。從環保節能的角度來看,AI從雲端往終端的運算轉移也會是一個潮流。
人工智慧邊緣運算(AI Edge Computing)定義為將運算工作放在靠近終端裝置的運算設備或終端裝置本身上,終端裝置不需仰賴雲端運算即可獨立運作(圖1)。
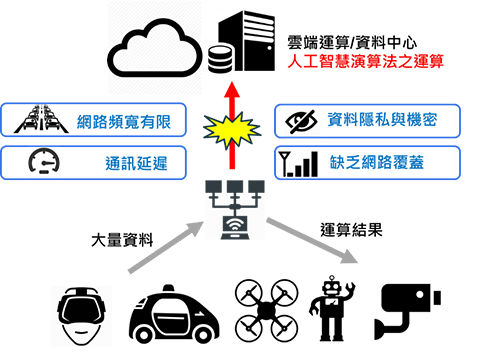 圖1 邊緣運算概念就是將運算工作由雲端轉移至終端或近端。
圖1 邊緣運算概念就是將運算工作由雲端轉移至終端或近端。
資料來源:Transparency Market Research 2018
由於AR/VR、自駕車、無人機與安防監控系統對AI邊緣運算的需求與日俱增,預估全球邊緣運算的市場規模將從2017年的80億2,450萬美元,大幅成長到2022年的133億1,370萬美元的規模,年複合成長率(CAGR)達10.7%(圖2)。
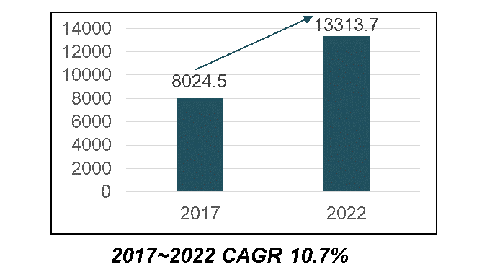 圖2 2017~2022全球邊緣運算市場規模
圖2 2017~2022全球邊緣運算市場規模
資料來源:Transparency Market Research 2018
滿足多元應用 分眾專用化AI晶片獻計
Intel表示,大數據浪潮(Flood of Data)已經來襲。至2020年平均每個網路用戶每天會產生1.5GB流量,自駕車每天會產生4.0TB資料,聯網飛機每天產生5.0TB資料,而智慧工廠每天產生的視訊資料量更高達5.0PB。上述這些龐大的資料再經過AI運算,讓裝置更智慧化,人類生活更美好。
因傳輸延遲、頻寬大小、個人隱私等問題,若都靠雲端運算的作法不符合部份應用所需,因此邊緣運算需求興起,且因省電及各種應用需求不同,AI邊緣運算晶片從通用晶片走向分眾專用化。如在智慧手機市場,蘋果的A11 Bionic晶片、華為(海思)的麒麟970晶片,三星及聯發科也預計推出相關NE(Neural Engine)SoC。自駕車方面,如Intel(Mobileye)的EyeQ5晶片及Nvidia的Xavier SoC。未來不論是智慧音箱、無人機、機器人、AR/VR與智慧監控等新興應用,都需要分眾專用化晶片。
分眾專用化晶片需要同時對系統規格、晶片硬體架構及軟體演算法做最佳化,因此各家廠商布局策略各有不同,如蘋果與華為採用垂直整合(採用自製晶片),而Intel則以併購方式(併Nervana、Movidius、Mobileye等)獲得所需IP(圖3)。
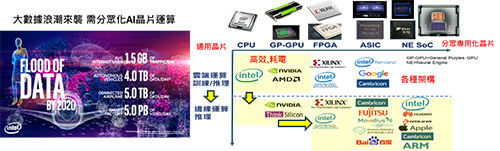 圖3 大數據浪潮來襲,需要分眾化AI邊緣運算專用晶片處理。
圖3 大數據浪潮來襲,需要分眾化AI邊緣運算專用晶片處理。
資料來源:Intel、工研院IEK
AI晶片大致上可區分為CPU、GP-GPU、FPGA、ASIC、NE SoC等不同架構,各種架構各有優缺點,但一般來說GPU在雲端運算仍具有優勢,在邊緣運算方面如FPGA是演算法未定型前的最佳選擇,ASIC因功耗低及量產成本低將是多數應用長期發展的最終目標。
AI平台本身在晶片設計上也要滿足一些特殊的需求,比如性能和功率的平衡。由於AI演算法的演進非常快,硬體的性能要能夠跟得上演算法的變化。目前業內的普遍架構是CPU加上硬體加速器的做法,將一部分可能需要升級的演算法放到CPU,因為CPU可以靈活地處理各種演算法,但是運算效率較差。另一部分比較固定的演算法會放到硬體加速器中。CPU對於演算法的彈性最好,但是效率最差,GPU更適合做圖像的運算,硬體加速器的效率最好但是彈性不夠(圖4)。
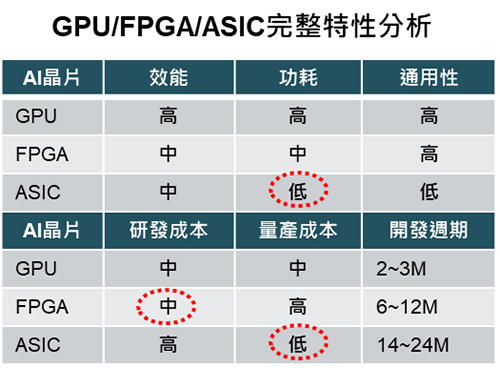 圖4 GPU/FPGA/ASIC完整特性分析
圖4 GPU/FPGA/ASIC完整特性分析
資料來源:工研院IEK
AI邊緣運算專用晶片大廠發展現況
Intel
Intel宣布收購電腦視覺處理器公司Movidius,加速進軍無人機、機器人以及VR領域。Movidius的殺手級產品就是花費九年時間完全從零開始自主研製的全新架構低功耗視覺處理器。Movidius客戶包括Google、聯想、無人機業者DJI及紅外線熱像儀廠商FLIR。其中Google採用Movidius的視覺處理器單元產品Myriad 2發展AR手機計畫Project Tango,聯想也用它來開發AR及VR產品,如Phab 2 Pro手機等。
另外,Intel也與Neuromem合作,將物聯網模組Curie加入人工智慧的功能。Curie是Intel 2016年推出的可穿戴及物聯網模組,低功耗高性能,只有鈕扣般大小,憑藉一個鈕扣大小的電池就能夠保持長時間運行。內置藍牙、加速度計和陀螺儀在內的六軸組合感測器,可以對接更多感測器的數位與類比介面。Curie之所以能改變傳統,主要在於其內置支援人工智慧的晶片,有一個支援128個神經處理單元的處理器,多個神經元組織在一起形成神經網路—Neuromem Network。和傳統的神經網路類似,它也具備分類器的功能,能對Curie搜集的資料進行分類和學習。
傳統上運動資料獲取和分類是非常耗時耗力的,需要程式設計師手動的去查對應資料寫演算法,而效果往往差強人意。但是通過Curie的神經網路來做動作的學習識別、分類就可以做到自動化,開發者只需要告訴它相應的動作或者姿態,讓它自己去學習即可,不用關心通過什麼樣的演算法實現,大大的降低了開發的門檻和成本。可以預見,將此項技術用在運動姿態的分析、矯正,普通人也能享受專業運動員的技術裝備,獲得專業的輔助、指導,高爾夫、網球、游泳、拳擊等各種運動愛好者都將因此而受益。
另外在自駕車AI晶片上,Intel開發的EyeQ5 SoC晶片,在子公司Mobileye先進技術加持下,宣稱其深度學習效率是對手的2.4倍。EyeQ5支援全自主駕駛(Level 5),Mobileye預估2020年就會有搭載EyeQ5晶片的自駕車上市。Intel與Google母公司Alphabet、BMW與汽車零件供應商Delphi在自駕車方面都建立合作關係(圖5)。
 圖5 Intel推新自駕車平台
圖5 Intel推新自駕車平台
資料來源:CES、工研院IEK
Think Silicon
新創公司Think Silicon展示其號稱「全球最高效節能的GPU」,專為支援小型顯示器的超低功耗IoT、穿戴式與嵌入式裝置而設計。這款Nema系列的最小型GPU利用6:1的訊框緩衝壓縮與4:1的軟體庫壓縮,大幅降低了功耗。
耐能(Kneron)
Kneron的神經網路處理器(NPU)支持運行各種神經網路,如Caffe、TensorFlow等。處理器本身體積很小,小到可以嵌入手機。除了晶片,Kneron自己也做智慧演算法的研究,可以把面向特定功能、訓練好的神經網路模型寫入晶片提供給客戶。Kneron還可以提供伺服器端的NPU,並組建雲+端協同的整套NPU解決方案。
寒武紀(Cambricon)
寒武紀為中國科學院計算技術研究所背景,擁有終端AI處理器IP和雲端AI晶片兩條產品線。公司主要的產品為2016年發表的寒武紀1A處理器(Cambricon-1A),是一款可以商用的深度學習專用處理器。
這款處理器基於寒武紀科技所發明的人工智慧專用指令集,具有完全自主智慧財產權。在特定的人工智慧應用上實測,寒武紀1A達到了傳統的四核通用CPU的25倍以上效能。
2017年底寒武紀發表新一代AI晶片,面向低功耗場景視覺應用的寒武紀1H8、擁有更廣泛通用性和更高性能的寒武紀1H16,以及可用於終端人工智慧產品的寒武紀1M。與傳統晶片不同,寒武紀的人工智慧晶片模擬大腦的神經元和突觸,一條指令即可完成一組神經元的處理。這種計算模式在做智慧處理時,比如識別圖像,效率要比傳統晶片高幾百倍。隨同新產品發布的,還有寒武紀專門為用戶打造的寒武紀人工智慧系統軟體「CambriconNeuWare」,全面支撐端雲一體的智慧處理。軟體開發平台構建於寒武紀全新的人工智慧專用指令集支撐之上。此外,寒武紀科技還表示未來將發表專門針對智慧駕駛的寒武紀1M處理器。
聯發科
聯發科技在AI領域的布局其實很早,布局的技術包括視覺識別(AI Vision)和語音辨識(AI Voice)。聯發科在2018年CES宣布針對消費性電子產品的人工智慧技術與平台NeuroPilot,基於聯發科AI處理器、軟體搭配NeuroPilot SDK,提供包括智慧手機、智慧家庭到自駕車所需的人工智慧解決方案;NeuroPilot目標為提升終端AI運算效率,並在多樣產品平台透過AI提升功能與品質,當然也支援主流的AI框架如Google的TensorFlow、Caffe、Amazon的MXNet、Sony的NNabla(圖6)。
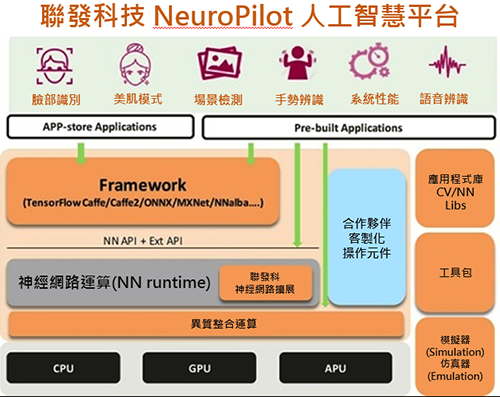 圖6 聯發科AI平台NeuroPilot
圖6 聯發科AI平台NeuroPilot
資料來源:MTK、工研院IEK
NeuroPilot採用的就是透過AI處理器的方式,把目前已知的比較固定的80~90種演算法固定到APU中,剩下一些持續演進的10個演算法會放到CPU中,兼顧彈性和效率。
AI邊緣運算加持 半導體產業掀革命
特定領域的專用人工智慧系統,由於應用背景需求明確、深厚之領域知識、模型建立計算簡單可行,在單項測試之智慧水準已可以超越人類智慧,目前在許多領域已取得具體成效。技術挑戰則在於發展低能耗、高準確率的認知運算,包括新型運算架構電路設計、演算法等。未來人工智慧晶片是特定的演算法加速器,來加速包括卷積神經網路(Convolution Neural Network, CNN)、遞迴神經網路(Recursive Neural Network, RNN)在內的各種神經網路演算法,專用晶片的最大優勢在於其成本和功耗降低,大幅提升人工智慧演算法運行效率。
由於AI演算法眾多,適用的產品類型亦不同,例如視覺式人工智慧處理多採用卷積深度神經網路。台灣產業若能結合應用驗證並建立合適的AI架構及權重,有助於與國際大廠接軌一同合作開發產品。連結國內機器人、無人機、車載系統、AR、VR等各生態系供應鏈系統業者,配合特定應用場域與情境,並聯盟國際人工智慧開源平台共同開發Hybrid人工智慧解決方案(圖7)。
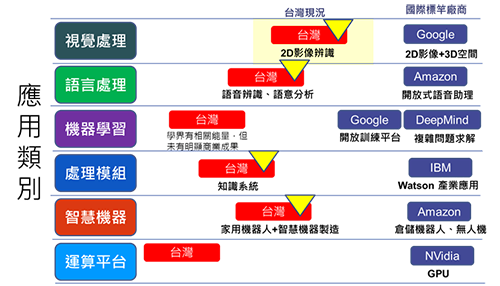 圖7 台灣AI產學研總體在影像/視覺的表現較佳
圖7 台灣AI產學研總體在影像/視覺的表現較佳
資料來源:工研院IEK
相對於大廠寡占雲端運算的CPU及GPU晶片,台灣較有機會發展AI邊緣運算推理晶片,其中較有機會的應用是影像與視覺的FPGA/ASIC解決方案。
分眾專用化AI晶片需要大量的資料作為訓練之用,雖然台灣沒有大型終端產品或電商公司,但智慧醫療(X光片影像協助判讀)或智慧交通運輸(輔助駕駛或智慧交通號誌)仍有獨特的數據可以開發分眾專用化的AI晶片。
台灣AI晶片產業發展方向,像是提升邊緣運算晶片的運算效率,支援業界現有類神經網路框架,如Google的TensorFlow、Intel的Caffe、Amazon的MXNet、Sony的NNabla、Microsoft的CNTK等;再者,可在多樣性產品平台上實現AI,如跨作業平台方案將AI應用在台灣有優勢的利基市場。